

Innhold Vis
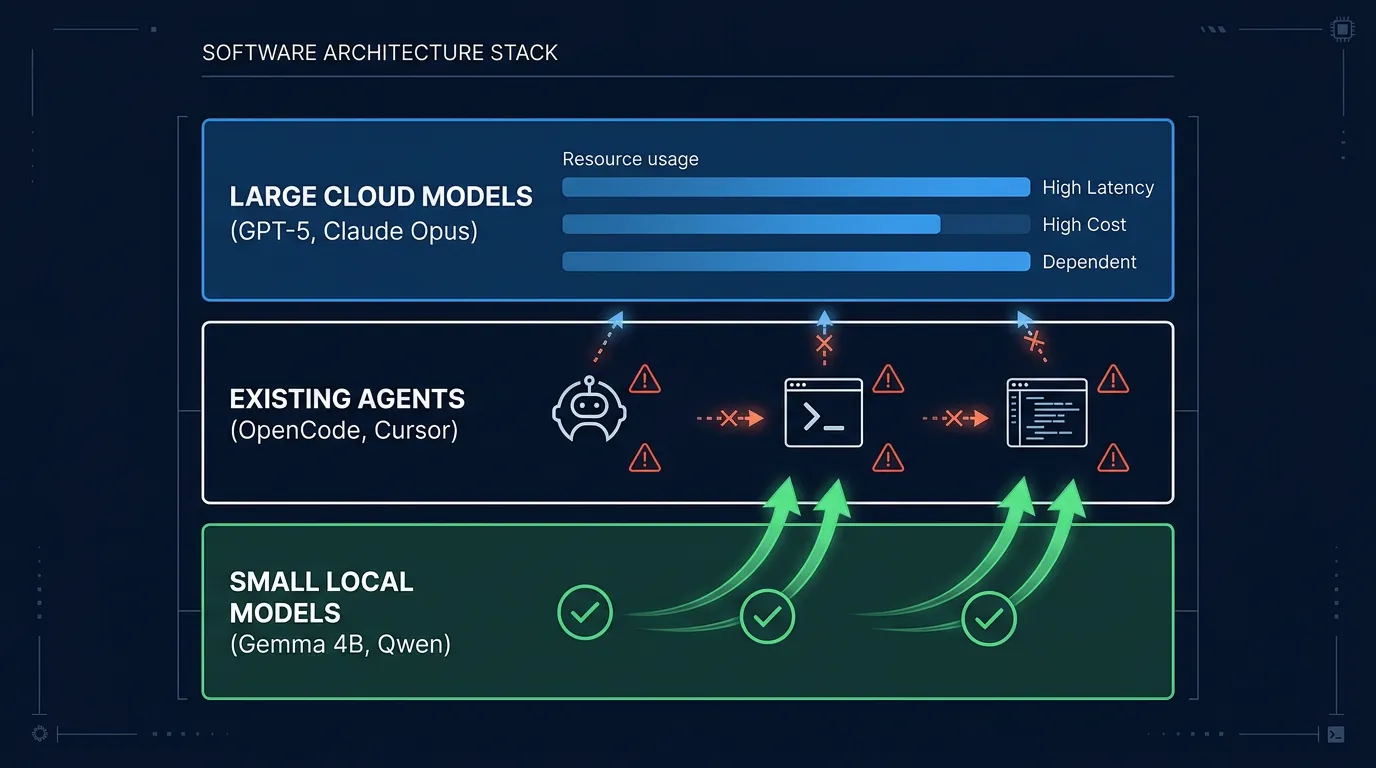
De fleste coding agents er bygget for sky-modeller og tar for gitt at du har tilgang til GPT-5 eller Claude Opus. Med en lokal modell som Gemma eller Qwen kollapser de – tool calls feiler midt i sekvensen, context overflower på komplekse oppgaver, og multi-step tasks går i stykker etter tredje steg. SmallCode er et svar på akkurat det problemet.
SmallCode er en coding agent designet spesielt for små lokale modeller. Den ble bygget av en utvikler som var lei av at eksisterende verktøy som Claude Code, Cursor og OpenCode forutsetter at du sitter på en sky-modell med hundrevis av milliarder parametere. Det er ikke alltid tilfelle – og det er ikke alltid ønskelig heller.
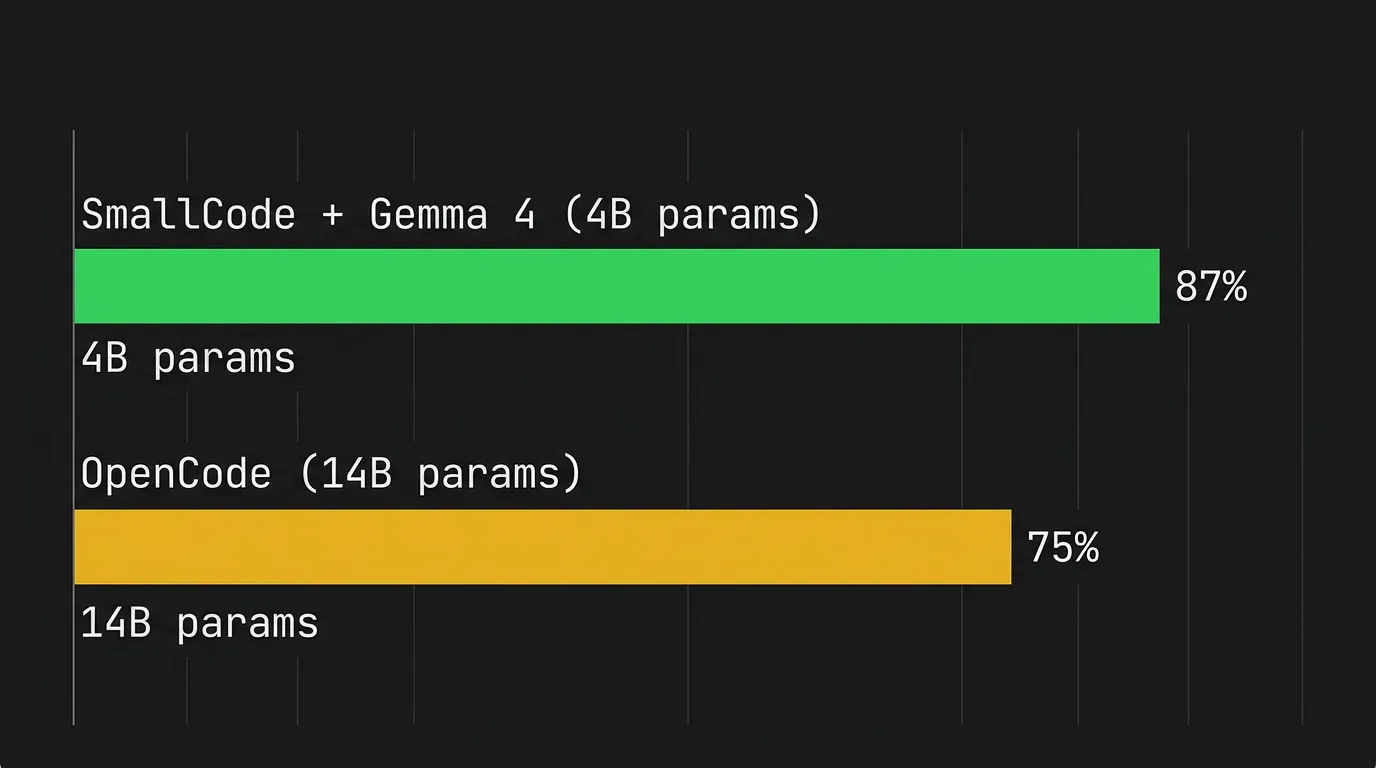
Resultatet er ganske overraskende: 87 av 100 benchmark-oppgaver løst med Gemma 4 på kun 4 milliarder aktive parametere per token. OpenCode scorer rundt 75% – og det med 14B-modeller. Det er en forskjell verdt å ta på alvor.
Hva er SmallCode, og hva gjør den annerledes?
SmallCode er en open source coding agent som prioriterer kompatibilitet med modeller du kan kjøre lokalt via Ollama eller lignende runtimes. Der de fleste agenter er optimalisert for store API-modeller, er SmallCode designet nedenfra og opp med tanke på begrensede ressurser.
De tre største problemene med eksisterende coding agents på lokale modeller er:
- Tool calls feiler fordi prompting-strategien er optimalisert for GPT-4-klassen
- Context overflower på lange oppgaver fordi agenten ikke er bevisst på minnebruk
- Multi-step reasoning knekker fordi modellen mister tråden mellom stegene
SmallCode adresserer alle tre med arkitektoniske valg – ikke ved å be deg bruke en større modell.
Hvordan håndterer SmallCode tool calls og context?
Kjernen i SmallCode er at den forenkler og tydeliggjør hvert steg for modellen. I stedet for å gi modellen en lang kontekst med alle tidligere handlinger, bruker SmallCode et komprimert arbeidsminne der bare det relevante for neste steg beholdes.
Tool call-formateringen er skrevet spesielt for at mindre modeller skal forstå strukturen. Store modeller som GPT-5 kan tolke tvetydige instruksjoner fordi de har sett så mange varianter i trening. En 4B-modell har ikke den samme robustheten – og SmallCode tar hensyn til det ved å bruke enklere, mer konsistente prompts.
Multi-step tasks løses ved å bryte oppgaven i klart avgrensede, sekvensielle steg der modellen bare trenger å fokusere på ett mål om gangen. Det er egentlig den samme teknikken gode promptere bruker manuelt – SmallCode bare automatiserer det.
Hva sier benchmarktallene?
87% på benchmark-oppgaver med Gemma 4 på 4B aktive parametere er det viktigste tallet her. Til sammenligning scorer OpenCode rundt 75% – og det med 14B-modeller som krever betydelig mer RAM. Det betyr at SmallCode med Gemma 4 er raskere, billigere å kjøre, og mer effektivt på oppgaveserien.
Det er verdt å minne om at benchmarks ikke er hele historien. Som jeg har skrevet om tidligere, er benchmarks generelt et dårlig mål på hva en modell faktisk presterer i hverdagsbruk – men i dette tilfellet er de interessante fordi de måler det samme verktøyet mot den samme oppgaveserien. Sammenligningen er mer rettferdig enn de fleste benchmark-presentasjoner man ser.
Gemma 4 er Googles lille lokale modell med interessant arkitektur – og den er tydeligvis godt egnet til kode-oppgaver med riktig agent rundt seg.
Passer SmallCode for deg?
Hvis du allerede kjører lokale modeller via Ollama eller lignende, er SmallCode verdt å teste. Du slipper API-kostnader, koden din forlater ikke maskinen, og du har ingen rate limits midt i en arbeidsøkt.
For de som bruker sky-tjenester i dag og er komfortable med det, er det ikke sikkert overgangen er nødvendig – men det er uansett nyttig å vite at alternativet finnes og faktisk fungerer på dette nivået.
Hvis du er nysgjerrig på hva AI coding agents er i stand til i dag, er SmallCode et konkret eksempel på at det ikke alltid er størrelsen på modellen som avgjør. Arkitektur, prompt-design og forståelse for modellens begrensninger teller like mye – kanskje mer.
SmallCode er tilgjengelig som open source. Søk opp prosjektet på GitHub og test det mot din lokale modell. Det koster deg ingenting utenom litt tid – og 87% benchmark-score fra en 4B-modell er en ganske god grunn til å prøve.







