

Innhold Vis
En 1 milliard parameter stor modell trent på 1000 dollar slår Metas Llama 3.2 3B på matematikk og resonnering. Sapient Intelligence – selskapet bak den hierarkiske resonneringsarkitekturen HRM – slapp HRM-Text 1B i mai 2026, og benchmark-chartene er interessante nok til å ta en titt, selv om du er skeptisk til markedsføringen.
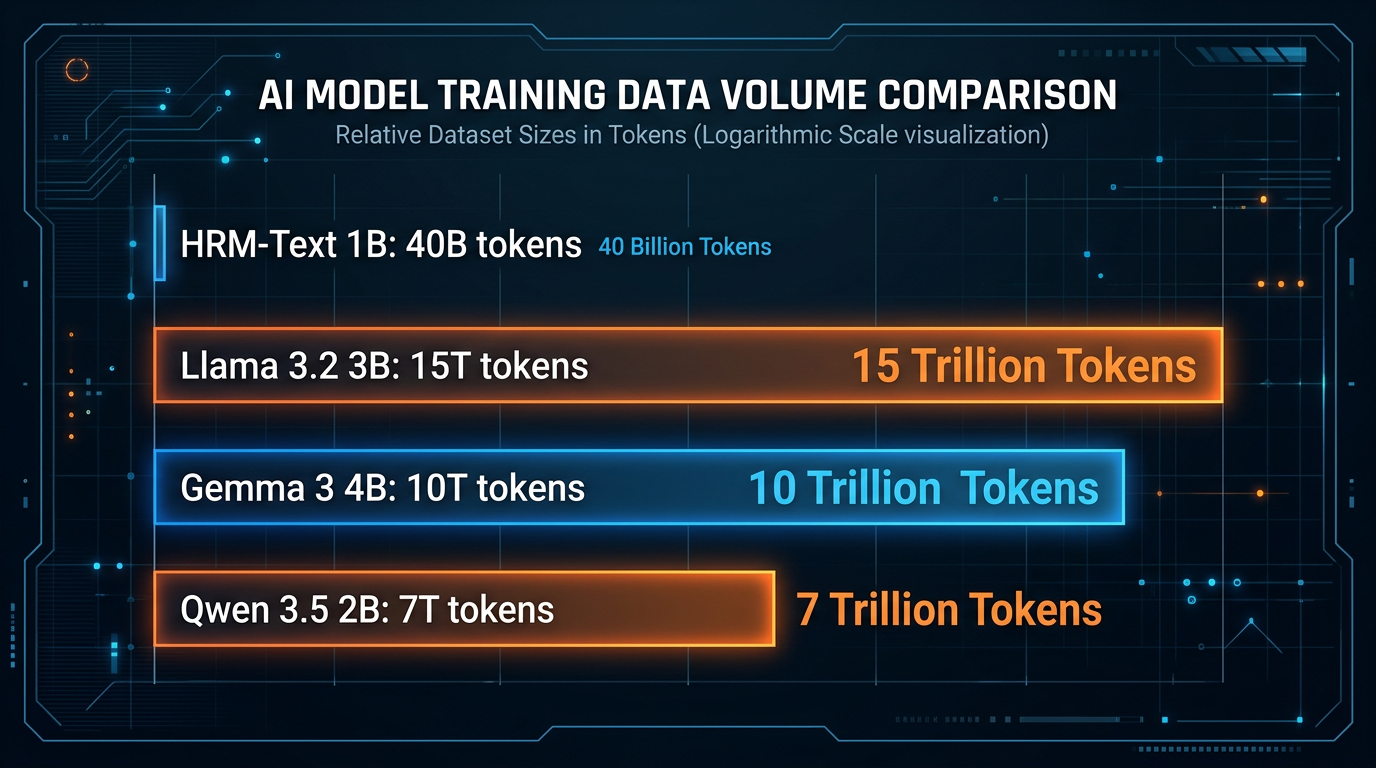
Tallene er konkrete: 40 milliarder unike tokens, 16 GPUer, 1,9 dager trening og en oppgitt kostnad på rundt 1000 dollar. Det de hevder er at HRM-Text 1B er trent på 100 til 900 ganger mindre data enn konkurrentene – Gemma 3 4B, Llama 3.2 3B, Qwen 3.5 2B og Olmo 3 7B – og likevel matcher eller slår dem på sentrale benchmarks.
Det er en stor påstand. Og som alltid med benchmark-publiseringer fra ukjente aktører: tallene lyver ikke nødvendigvis, men det er verdt å grave litt i hva de faktisk viser.
Hva er HRM-Text 1B?
HRM-Text 1B er en ren tekstmodell på 1 milliard parametere, trent fra bunnen av av Sapient Intelligence. Selskapet er kjent fra før for HRM-arkitekturen – Hierarchical Reasoning Machine – en alternativ tilnærming til transformer-modeller som hevder bedre datautnyttelse gjennom hierarkisk resonneringsstruktur.
Modellen er trent på 40 milliarder unike tokens. Til sammenligning er Llama 3.2 3B trent på rundt 9 000 milliarder tokens – altså rundt 225 ganger mer data. Gemma 3 4B og Qwen 3.5 2B er trent på enda mer. At en modell trent på en brøkdel av dataen likevel hevder konkurransedyktige resultater, er enten genuint interessant eller et tegn på at benchmark-utvalget er gjort strategisk. Sannsynligvis litt av begge deler.
Arkitekturen er det som skiller HRM fra standard transformere. I stedet for at alle tokens behandles flatt i hvert lag, organiserer HRM hierarkier av abstraksjonsnivåer – en tilnærming som ligner mer på hvordan noen kognitive teorier beskriver menneskelig resonnering. Tanken er at modellen lærer mer robust kunnskap fra færre eksempler fordi representasjonene er strukturelt dypere.
Hva sier benchmarkene – og hva sier de ikke?
På MATH og DROP slår HRM-Text 1B Llama 3.2 3B direkte, ifølge Sapient Intelligences egne resultater. MATH er en standardbenchmark for matematisk resonnering på videregående-nivå. DROP (Discrete Reasoning Over Paragraphs) tester om modellen kan kombinere informasjon fra tekst og gjøre enkel aritmetikk for å svare riktig.
Begge disse benchmarkene er sensitive for resonneringsevne fremfor rå faktainnhenting – noe som er konsistent med det HRM-arkitekturen er designet for. Valget av benchmarks er altså ikke tilfeldig, og det er ikke et tegn på juks at selskapet velger å fremheve der de er best. Det er helt standard praksis.
Det som er verdt å merke seg er hva vi ikke vet: Hvordan er resultatene på MMLU, HellaSwag, ARC eller mer generelle evnebenchmarks? Og viktigst – er en 1B-modell faktisk nyttig i praksis sammenlignet med en 3B-modell, uavhengig av benchmark-poeng? En 3B-modell er fortsatt mer kapabel i daglig bruk, selv om en 1B-modell matcher den på en spesifikk oppgave.
Jeg er generelt skeptisk til benchmarks som primærargument, og det bør du også være. 600 kriterier som ikke er en benchmark er ofte mer relevant enn et enkelt tall fra en leaderboard. Men tallene her er konkrete nok til å ta på alvor.
Hva betyr 1000 dollar i treningskostnad?
Den oppgitte treningskostnaden på rundt 1000 dollar for hele pretrening-fasen er det som virkelig skiller seg ut. 16 GPUer i 1,9 dager tilsier en relativt beskjeden klynge – sannsynligvis A100 eller H100-instanser på cloud til markedspris.
For å sette det i kontekst: Llama 3.1 405B ble anslått å ha kostet titalls millioner dollar i GPU-tid. Selv Llama 3.2 3B – som nå brukes som referansemodell her – ble trent av Meta med ressurser de aller fleste ikke kan drømme om. At en liten organisasjon kan produsere en konkurransedyktig modell på 1000 dollar er et interessant signal om hvor arkitektur-valg faktisk kan gjøre en forskjell.
Dette er ikke unikt for HRM. Vi har sett lignende påstander fra Microsoft med Phi-serien, fra Google med Gemma og fra Apple med OpenELM – alle modeller som prøver å gjøre mye med lite. Meta Muse Spark er et annet eksempel på en modell som krever «over en størrelsesorden mindre beregningskraft enn Llama 4 Maverick» ifølge Metas egne tall. Effektivitetsargumentet er populært akkurat nå – og med gode grunner.

Er HRM-arkitekturen gjennomtestet?
Sapient Intelligence publiserte originalt HRM-paperet tidligere i 2025, og dette er den første tekstmodellen basert på arkitekturen som slippes offentlig. Det er et relativt lite og ukjent selskap, og det er fornuftig å vente på uavhengig evaluering før man legger for mye vekt på resultatene.
LocalLLaMA-fellesskapet er tradisjonelt flinke til å teste påstander selv. Erfaringen der er at modelleiere som poster benchmark-charts uten replikerbare evalueringsscripts ofte møter mye skepsis, og med rette. Det er foreløpig uklart om Sapient Intelligence leverer tilstrekkelig transparens rundt evalueringsmetodikk.
Modellen er tilgjengelig via Sapient Intelligences offisielle kanaler. Open source AI-guiden min gir god bakgrunn på hva «open weights» faktisk betyr og hva du bør sjekke før du stoler på en modell-publisering.
Hvem er dette relevant for?
En 1B-modell er primært interessant i to scenarioer: edge-deployment (modeller som kjører på enheter med begrenset minne og strøm) og forskning på effektiv trening. For praktisk bruk er en 3B-modell som Llama 3.2 fortsatt mer allsidig, og den kjører fint lokalt på de fleste maskiner med Ollama.
Det HRM-Text 1B potensielt representerer er mer interessant enn selve modellen: en demonstrasjon av at arkitektur-innovasjon kan kompensere for treningsdata-mangel på meningsfull måte. Hvis HRM-tilnærmingen lar seg skalere opp, og resultatene holder ved uavhengig validering, er det et eksempel på at det fremdeles er mye uutforsket terreng i AI-arkitektur utenfor transformer-paradigmet.
VL-JEPA fra Meta er et annet eksempel på en slik alternativ tilnærming – en modell som predikerer mening fremfor ord, med 50% færre parametere men bedre ytelse enn tradisjonelle vision-language modeller. Fellesnevneren er at de utfordrer antagelsen om at «mer data = bedre modell» som har dominert siden GPT-3.
Om HRM-Text 1B faktisk holder det den lover, vil vi vite når fellesskapet har fått tid til å teste den skikkelig. Inntil da er benchmark-chartene interessante nok til å følge med – men ikke interessante nok til å erstatte din nåværende arbeidsflyt med.







