

Innhold Vis
Hvis du har brukt AI-agenter til noe mer enn enkle engangsoppgaver, vet du problemet: agenten husker ikke hva den gjorde for to minutter siden. Kontekst flyter over, token-grenser nås, og agenten begynner å gjenta seg selv eller miste tråden. Tencent har nettopp sluppet en løsning på dette – et åpen kildekode-minnelag kalt TencentDB Agent Memory som kjører helt lokalt på din maskin.
Systemet er lisensiert under MIT, krever ingen sky-tjenester, og bygger på SQLite og lokale vektorinnbygginger. Det er altså ikke en ny API du betaler per token for, men et lokalt minnehierarki du kan installere og kjøre selv.
Det interessante er arkitekturen. I stedet for å bare putte alt i en flat vektordatabase – slik de fleste minneløsninger gjør i dag – deler TencentDB Agent Memory minnet inn i fire lag. La meg gå gjennom hva det betyr i praksis.
Hva er problemet med AI-agentminne i dag?
De fleste minneløsninger for AI-agenter fungerer slik: ta samtaletekst, splitt den opp i biter, lagre vektorinnbygginger av bitene, og søk i disse ved neste forespørsel. Det høres greit ut inntil du har en agent som har jobbet med en codebase i en time og skal referere til noe den gjorde for 50 verktøykall siden.
Problemet er at flat vektorsøk ikke vet hva som er viktig. Et atomt faktum («bruker foretrekker TypeScript») havner i samme haug som en verbose loggfil fra et API-kall. Gjenfinning blir støyende. Agenten drukner i detaljer den ikke trenger, og mangler sammenheng den faktisk trenger.
TencentDB Agent Memory beskriver dette problemet direkte i dokumentasjonen: «Most current memory stacks shred data into fragments and dump them into a flat vector store.» Det er ganske riktig, og det er det de prøver å løse.

Hva er de 4 lagene i minnehierarkiet?
Kjernen i TencentDB Agent Memory er en semantisk pyramid med fire lag – fra rådata nederst til abstrahert personaprofil øverst:
L0 Conversation er selve dialoghistorikken, den rå samtalen. Dette er grunnfjellet – alt havner her først.
L1 Atom er atomare fakta i JSONL-format. Systemet ekstraherer konkrete fakta fra samtalen automatisk hvert 5. steg. Eksempel: «bruker foretrekker Python 3.11», «prosjektet bruker PostgreSQL 15». Presise, søkbare enheter.
L2 Scenario er sceneblokker i Markdown-format. Høyere abstraksjonsnivå – samlede oppsummeringer av hva som skjedde i en kontekst. «Bruker debug-session 14. mai: fant minnelekk i Redis-koblingen, løste det med connection pooling.»
L3 Persona er brukerprofilen – en persona.md-fil som genereres automatisk for hver 50. lagrede minne. Langsiktig profil: preferanser, arbeidsmetoder, teknologivalg.
Når agenten søker etter kontekst, spørres L3 Persona først. Finner den treff der, drilles det ned til L1 og L0 for detaljer. Systemet lagrer L2 og L3 som lesbar Markdown under ~/.openclaw/memory-tdai/, så du kan faktisk åpne og lese hva agenten vet om deg.
Hva er symbolsk korttidsminne – og hvorfor er det smart?
Den andre hoveddelen av systemet er det de kaller symbolsk korttidsminne, og her er det de gjør noe genuint interessant. En typisk lang agentkjøring – si en softvare-engineering-oppgave på noen timer – genererer massive mengder verbose verktøylogger. Disse loggene spiser opp kontekstvinduet raskt.
Løsningen: fulle verktøylogger offloades til egne referansefiler (refs/*.md), mens tilstandsoverganger kodes i Mermaid-syntaks – et kompakt grafspråk. Agenten resonnerer over en symbolsk tilstandsgraf i konteksten, ikke over råtekst. Trenger den detaljene, refererer den til node_id og henter den spesifikke råteksten.
Det er analogt med hvordan vi mennesker husker ting: du husker ikke ord for ord hva kollegaen sa på møtet, men du husker hva møtet handlet om og kan slå opp notatene hvis du trenger spesifikke tall.
Hvilke benchmarkresultater viser systemet?
Tencent presenterer resultater fra fire benchmarks. Tallene er interessante, men vær som alltid skeptisk til benchmarks fra selskapet som laget produktet – de er best brukt som retningsgivende, ikke som absolutte sannheter.
På WideSearch (langhorisontsesjonssøk) øker pass-rate fra 33 % til 50 % – en forbedring på 51,52 %. Tokenforbruk reduseres med 61,38 %. På SWE-bench (software engineering) forbedres score fra 58,4 % til 64,2 %, og tokenforbruk faller 33 %. PersonaMem (personahusking over tid) viser den mest dramatiske forbedringen: nøyaktighet fra 48 % til 76 %, altså en økning på 59 %.
Det interessante er at målingene er gjort over langhorisontsesjonene, ikke enkeltsvinger. Det gir mer realistiske tall for agenter som faktisk brukes over tid, ikke bare kortvarige demo-oppgaver.
Hvordan installerer og bruker du det?
Systemet leveres på to måter: som OpenClaw-plugin og som Hermes Docker-image.
OpenClaw-pluginen installeres med:
npm install @tencentdb-agent-memory/memory-tencentdbKrav: Node.js 22.16 eller nyere. Aktiveres med ett konfigurasjonsflag i ~/.openclaw/openclaw.json. Hvis du allerede bruker OpenClaw lokalt – og jeg har tidligere skrevet om hvilke lokale modeller som passer best til OpenClaw – er dette den enkleste inngangen.
Hermes Docker-image bundler Hermes Agent, minnespluginen og TDAI Memory Gateway. Standardmodellen er Tencents DeepSeek-V3.2, men du kan bytte til hvilken som helst OpenAI-kompatibel modell via MODEL_PROVIDER=custom. Minnedata lagres i et dedikert hermes_data-volum.
Backend er SQLite og sqlite-vec som standard. Vil du bruke Tencents skybaserte vektordatabase (TCVDB) i stedet, kan det konfigureres, men for lokal bruk er SQLite-stien det enkleste.
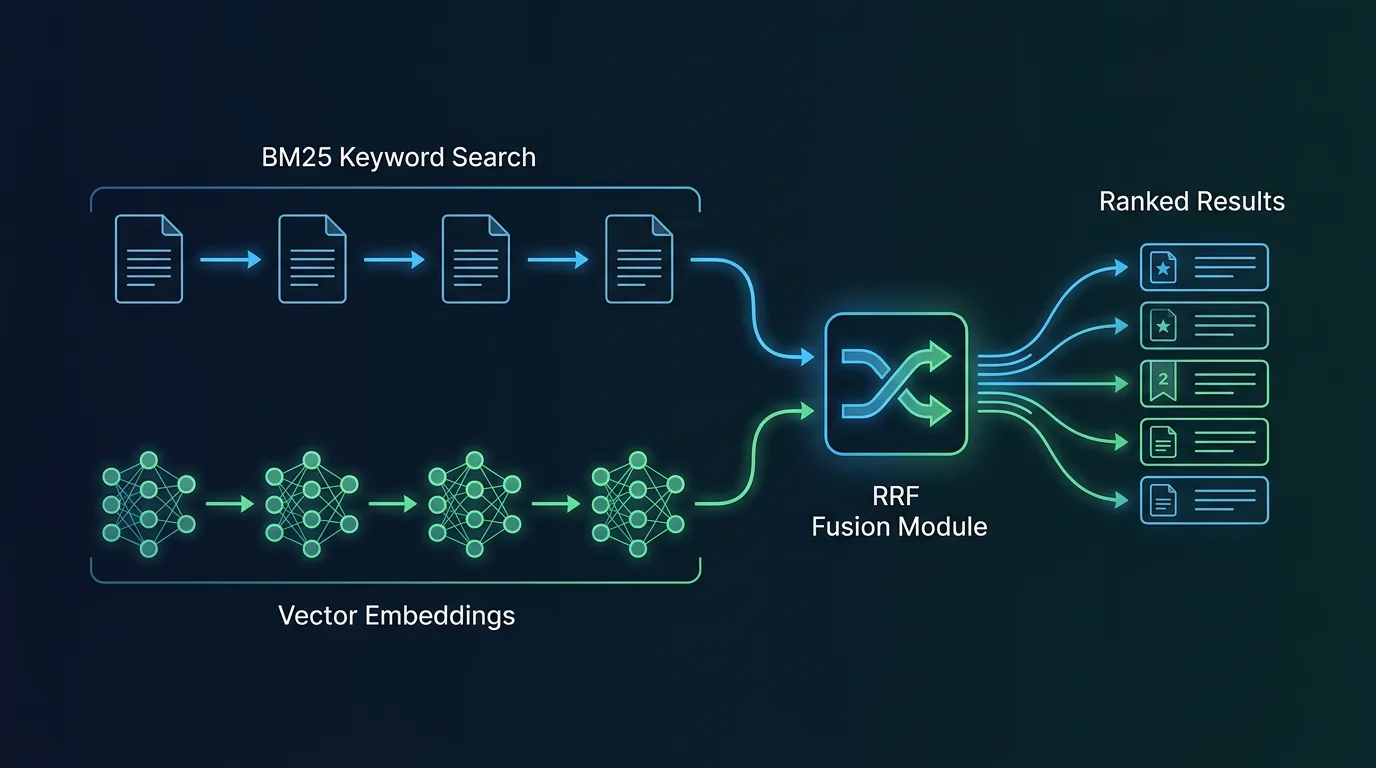
Hva er gjenfinningsstrategien – og hva kan du justere?
Systemet bruker hybrid gjenfinning som standard: BM25-nøkkelordssøk kombinert med vektorinnbygginger, fusjonert med Reciprocal Rank Fusion (RRF). Det er en velprøvd kombinasjon – BM25 er bra på eksakte termer, vektorsøk er bra på semantisk likhet, og RRF veier resultatene fra begge.
Vil du ha ren nøkkelord- eller ren embeddings-modus, kan det konfigureres. BM25 støtter jieba for kinesisk tekst, men fungerer fint for norsk og engelsk uten tilleggskonfigurasjon.
Standardinnstillingene gir et godt utgangspunkt: L1-minneekstraksjon hvert 5. steg, personagenerering hvert 50. minne, 5 resultater returneres per søk, og 5 sekunders timeout (agenten hopper over minneinjeksjon heller enn å blokkere).
To verktøy eksponeres for agenten: tdai_memory_search for å søke i L1, L2 og L3, og tdai_conversation_search for å søke i L0 samtalehistorikk. Begge returnerer node_id og result_ref for sporbarhet.
Er dette bedre enn Octopoda eller Cog?
Det er naturlig å sammenligne med andre lokale minneløsninger. Jeg har tidligere skrevet om Octopoda – persistent minnelag for lokale AI-agenter og Cog – kognitiv arkitektur for Claude Code. Hva skiller TencentDB Agent Memory?
Den viktigste forskjellen er abstraksjonsnivåene. Octopoda og Cog lagrer og gjenfinne informasjon, men de har ikke TencentDB-systemets fire-lags hierarki der abstraksjonsnivå velges automatisk basert på søkekontekst. PersonaMem-benchmarken – der nøyaktigheten øker fra 48 % til 76 % – antyder at L3 Persona-laget gjør en reell forskjell over tid.
Ulempen er kompleksiteten. TencentDB Agent Memory er mer å sette opp enn Cog (som bruker ren Markdown-tekst) eller Octopoda. OpenClaw-bindingen begrenser også hvem som kan bruke det direkte – det er ikke en løsning du plugger inn i Claude Code eller en hvilken som helst agent uten ekstra arbeid.
For agenter som kjøres i OpenClaw-miljøet, og særlig for langhorisonts engineering-oppgaver, ser dette ut til å være den mest gjennomtenkte minnearkitekturen som er tilgjengelig i dag – og den er gratis og lokal. For enklere brukstilfeller er Cog eller Octopoda fortsatt enklere innganger.
Kildekoden ligger på GitHub under MIT-lisens. Du trenger ikke sende data til noen server, og du eier alt som lagres. For de av dere som har fulgt mine tanker om lokale AI-løsninger kjenner dere igjen mønsteret – det er den retningen verktøyene beveger seg, og dette er et solid steg i den retningen.







