

Innhold Vis
Hvis du har fulgt med på Physical AI – altså AI som skal fungere i den virkelige verden – er NVIDIA Cosmos 3 verdt å kjenne til. Det er den første åpne omni-modellen for fysisk AI-resonnering og handling, og den gjør noe vi ikke har sett før: kombinerer video-generering, språkresonnering og robothandlinger i én og samme modell.
Tidligere måtte du bruke separate modeller for å forutsi hva som skjer i en scene, generere syntetisk treningsdata og planlegge robotbevegelser. Cosmos 3 gjør alt dette i en enkelt forward pass. Det er ikke en liten oppdatering – det er en arkitekturell endring i hvordan Physical AI-systemer kan bygges.
Modellen ble sluppet 1. juni 2026 på Hugging Face, er åpen, og er tilgjengelig i to varianter: Nano (8 milliarder parametere) og Super (32 milliarder parametere). Her er hva du trenger å vite.
Hva er egentlig en omni-modell?
En omni-modell er en enkelt, samlet modell som håndterer oppgaver som tidligere krevde separate systemer. I Cosmos 3 sin tilfelle betyr det at én modell kan ta inn tekst, bilde, video og handlingsdata – og spytte ut video, tekst eller konkrete robothandlinger avhengig av hva du trenger.
Tidligere Cosmos-varianter (Predict, Transfer, Reason, Policy) var separate modeller med spesialiserte roller. Cosmos 3 slår dem sammen. Det gjør systemet enklere å deploye, og det åpner for at modellen kan koble reasoning og generering tettere – den kan tenke gjennom en situasjon og generere en video av hva som vil skje, i ett steg.
Arkitektonisk bruker den en Mixture-of-Transformers-tilnærming (MoT) med to separate sekvenser: en autoregressive del for resonnering og en diffusjonsbasert del for generering. De to delene kommuniserer via felles attention-mekanismer, noe som gjør at modellen kan blande «tenke» og «vise» uten å skifte mellom systemer.
Hva kan Cosmos 3 faktisk gjøre?
Det er fem hoveddingene modellen støtter, og kombinasjonen er det som gjør den interessant for Physical AI:
Den kan generere video fra tekst, bilder eller eksisterende video – nyttig for å lage syntetiske treningsdata. Den fungerer som en Vision Language Model og kan resonnere om hva som skjer i en video med tekstsvar. Den kan forutsi fremtidige handlingssekvenser basert på hva en robot ser (forward dynamics), og den kan gjøre det motsatte: se en video og trekke ut hvilke handlinger som ble utført (inverse dynamics). Og den kan kombinere bilde og tekst til å generere både video og konkrete handlingskommandoer – det NVIDIA kaller policy-modus.
For robotikk betyr dette at du kan bruke én modell til å lage syntetisk treningsdata, validere at roboten gjør noe fornuftig, og generere handlingsplaner – alt uten å bytte system.

Cosmos 3 Nano vs. Super – hvilken er for deg?
NVIDIA tilbyr to varianter med ganske ulike krav til maskinvare:
Cosmos 3 Nano har 8 milliarder parametere i reasoner-delen og 8 milliarder i generator-delen. Den er optimert for effektiv inferens og skal kjøre på en RTX PRO 6000 – det er workstation-nivå maskinvare, ikke datasenterklasse. Modellen ligger på Hugging Face som nvidia/Cosmos3-Nano og hadde over 6 200 likes allerede ved lansering.
Cosmos 3 Super har 32 milliarder parametere i begge deler og er designet for storskala syntetisk datagenerering. Den krever NVIDIAs Hopper eller Blackwell-arkitektur – det vil si H100 eller nyere. For de fleste utviklere er Nano den realistiske startvarianten, mens Super er for organisasjoner som trenger å generere store mengder treningsdata.
Begge er integrert med Hugging Face Diffusers-biblioteket, noe som betyr at du kan bruke dem med vanlig Python uten å forholde deg til NVIDIAs egne rammeverk hvis du ikke vil.
Hvem er dette faktisk nyttig for?
Cosmos 3 er ikke en chat-modell eller et billedverktøy for kreative. Det er et verktøy for folk som jobber med Physical AI – primært robotikk, autonome kjøretøy og smarte miljøer.
For robotikk-teams er det to konkrete brukstilfeller som peker seg ut: syntetisk datagenerering og policy-evaluering. Å trene roboter krever enorme mengder data, og å samle det i den virkelige verden er dyrt og tregt. Cosmos 3 kan generere realistiske videoer av robotsituasjoner – pick and place, lagerhåndtering, manipulasjonsoppgaver – som kan brukes som treningsdata uten å kjøre en fysisk robot i måneder.
For autonome kjøretøy er brukstilfellet å simulere sjeldne og farlige situasjoner. Du kan ikke samle nok data av en bil som kjører ut for en bane i regn på glatt is til å trene en robust modell – men du kan generere syntetiske videoer av det i stor skala.
NVIDIA slipper også seks åpne syntetiske datasett med modellen, inkludert datasett for embodied robotsimuleringer, fysikkinteraksjoner fra Isaac Sim, spatial reasoning og menneskelig bevegelse. Det gjør det lettere å komme i gang uten å generere alt selv.
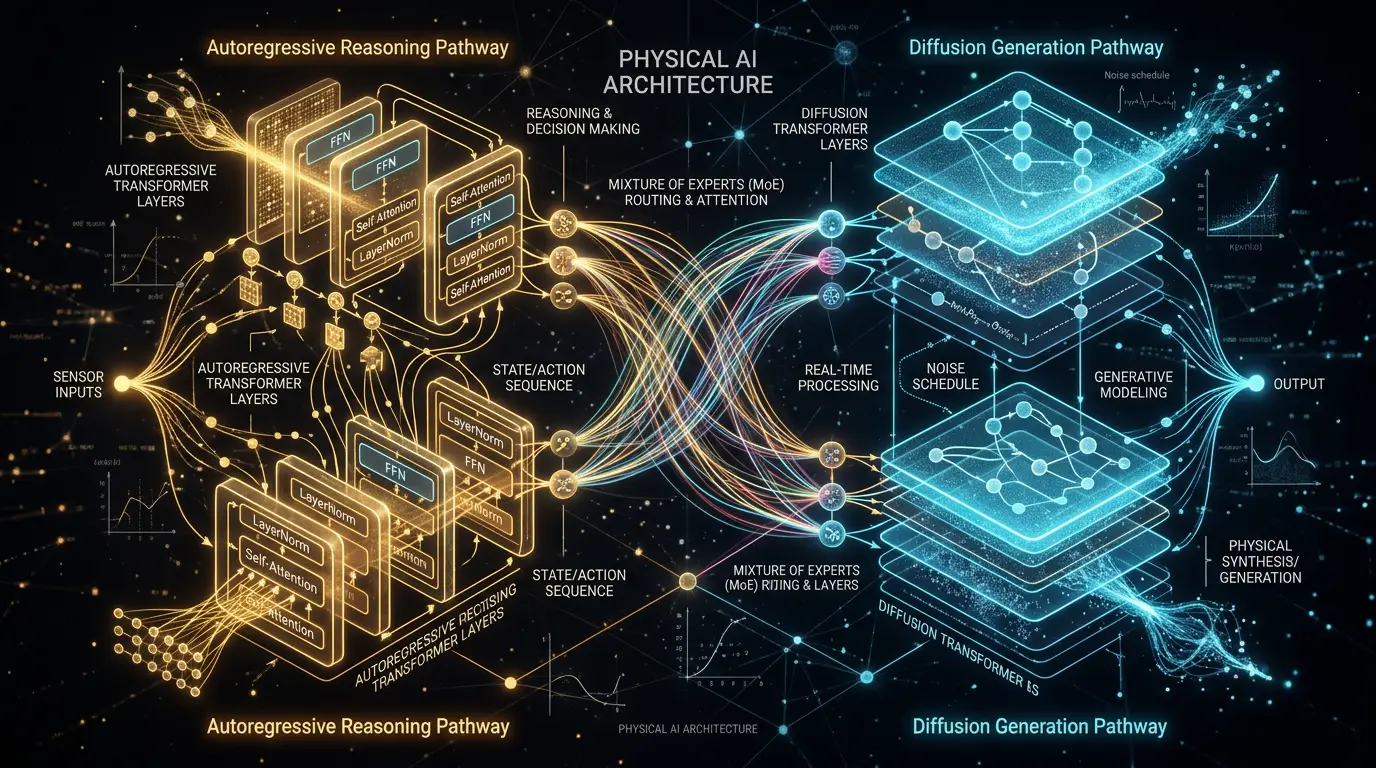
Hvordan bruker du Cosmos 3 i praksis?
Integrasjonen med Hugging Face Diffusers gjør at du kan laste inn modellen med et par linjer Python. Et enkelt text-to-image-eksempel bruker Cosmos3OmniPipeline fra Diffusers, laster inn nvidia/Cosmos3-Nano med bfloat16-presisjon og sender inn en tekstprompt. Resultatet er en video (eller enkeltbilde) med 720p-oppløsning som standard.
For mer avansert bruk – som post-training på egne robotdata eller fine-tuning til et spesifikt domene – bruker du Cosmos Framework på GitHub. Der finner du inferensscripter, post-training-guider og det NVIDIA kaller «agent skills» for raskere utvikling.
Du kan også kjøre modellen via NVIDIA NIM (microservices) hvis du ikke vil hoste den selv. Det er sannsynligvis det enkleste alternativet for teams som ikke har dedikert GPU-infrastruktur.
Hva med åpenheten – er dette faktisk open source?
Cosmos 3 er åpen i den forstand at modellvektene er tilgjengelig på Hugging Face uten betalingsmur. Det er ikke fullt open source etter FSF-definisjonen – det er sannsynligvis lisensrestriksjoner knyttet til kommersiell bruk, slik vi har sett med mange andre «åpne» NVIDIA-modeller. Les lisensbetingelsene på Hugging Face-siden før du bruker den i kommersielle produkter.
Det er uansett et steg frem fra lukkede world foundation models. Fellesskapet på Hugging Face viste tydelig interesse – modellen hadde allerede over 200 bidragsytere fra NVIDIA-teamet og tusenvis av likes ved lansering 1. juni 2026.
Cosmos 3 er ikke noe du laster ned og leker med på en vanlig laptop. Det er et seriøst verktøy som krever seriøs GPU-kraft. Men for de som jobber med robotikk og Physical AI er dette en av de mer interessante modellene vi har sett i det åpne landskapet – særlig fordi den kombinerer resonnering og generering i ett system. Tidligere lignende arbeid, som NVIDIA Cosmos Predict 2.5, krevde separate pipelines for dette. Cosmos 3 rydder opp i den kompleksiteten.
Vil du grave dypere er det verdt å se på NVIDIAs øvrige open source AI-satsing, og hvis du er nysgjerrig på hva Physical AI faktisk betyr i praksis er artikkelen om humanoide roboter og iPhone-øyeblikket et godt sted å starte.








1 kommentar