

Innhold Vis
Hvis du har tenkt på hvilken AI-modell som faktisk kan håndtere enorme dokumenter og skrive kode over lang tid uten å glemme hva den holdt på med – bør du se på MiniMax M3. Den kinesiske AI-utfordreren MiniMax lanserte 1. juni 2026 en modell som kombinerer tre ting som sjelden finnes i én pakke: 1 million tokens kontekstvindu, innebygd multimodalitet og agentic coding som holder seg over mange timer.
MiniMax er kanskje ikke det første navnet du tenker på i AI-kappeløpet, men selskapets forrige modell, MiniMax M2.5, klarte seg svært bra til en brøkdel av prisen på sammenlignbare modeller. M3 er et steg opp igjen – og det er noen tall her som faktisk er verdt å stoppe opp ved.
API-et er allerede live på platform.minimax.io. Modellvektene og den tekniske rapporten kommer innen ti dager. Her er det du trenger å vite.
Hva er MSA-arkitektur, og hvorfor skal du bry deg?
Det tekniske kjernen i M3 er noe MiniMax kaller MSA – MiniMax Sparse Attention. Problemet den løser er veldig konkret: jo lengre kontekst en AI-modell jobber med, jo tregere og mer ressurskrevende blir den. Standard oppmerksomhetsmekanismer skalerer kvadratisk – dobler du kontekstlengden, firedobler du beregningene.
MSA bryter dette mønsteret. MiniMax oppgir at M3 er mer enn 9 ganger raskere på prefill og over 15 ganger raskere på dekoding ved 1 million tokens sammenlignet med M2. Per-token beregning er 1/20-del av M2 ved 1M-token lengde. Det er ikke bare raskere – det gjør lang kontekst praktisk å faktisk bruke.
For sammenligning er M3 også over fire ganger raskere enn åpen kildekode-implementasjoner som Flash-Sparse-Attention. Arkitekturen bruker en tilnærming der hver KV-blokk leses bare én gang med sammenhengende minneaksess, som reduserer flaskehalsene betraktelig.

Hva betyr 1 million tokens i praksis?
1 million tokens er omtrent 750 000 ord, eller rundt 1 500 sider tekst. Det er nok til å laste inn en hel kodebase, et stort lovverk, eller et helt semester med akademiske artikler – og stille spørsmål om alt av det i én enkelt samtale.
Dette er ikke unikt for M3 – Gemini-modellene har hatt tilsvarende kontekstvindu en stund. Men det som skiller M3 er at den gjør dette med en åpen-vekt-arkitektur og til en konkurransedyktig pris. For mange er det kombinasjonen som teller.
Praktisk sett åpner dette for use cases som er vanskelige med kortere kontekst: sammenstilling av hundrevis av kontrakter, analyse av lange kodeprosjekter med full historikk, eller AI-agenter som kjører multi-timers arbeidsøkter uten å miste tråden. Kall over 512 000 tokens betaler en høyere long-context-rate, noe som er relevant å ha i bakhodet hvis man planlegger å bruke den fulle 1M-token kapasiteten aktivt.
Kan MiniMax M3 kode bedre enn GPT-4.5?
Benchmarkene her er faktisk interessante. På SWE-Bench Pro – kanskje det mest respekterte benchmarket for reell kode-problemløsning – scorer M3 59,0%. Det er ifølge MiniMax høyere enn både GPT-5.5 og Gemini 3.1 Pro.
Andre kode-benchmarks fra samme rapport:
- Terminal-Bench 2.1: 66,0%
- SWE-fficiency: 34,8%
- KernelBench Hard: 28,8% (NVIDIA Blackwell GPU-er)
- MCP Atlas: 74,2%
- OSWorld-Verified: 70,06% (skrivebordsautomatisering, 361 prøver)
Det er verdt å merke seg at MiniMax selv publiserer disse tallene – noe som betyr de bør etterprøves av uavhengige. Poolside Laguna og andre spesialiserte kodingsmodeller er naturlige sammenligningspunkter, og vi bør se resultatene i kontekst av hva kodingsoppgavene faktisk inneholder.
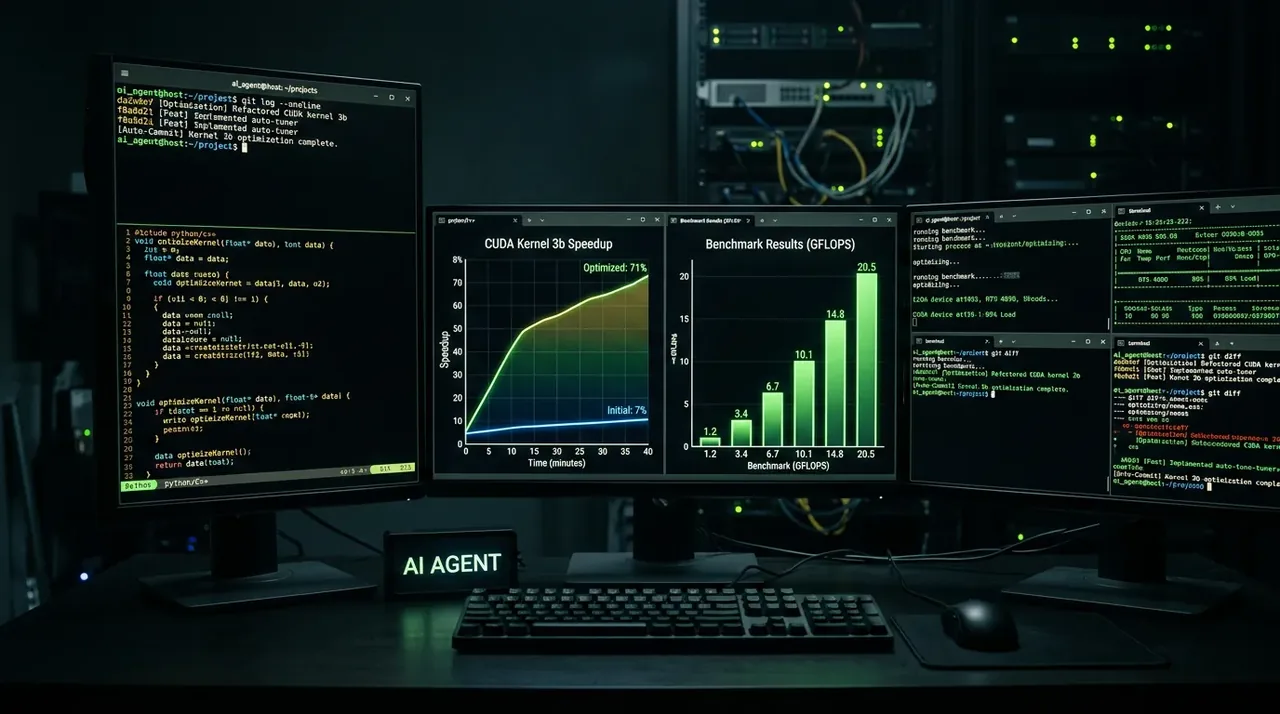
Det mest imponerende er kanskje de virkelig-verden eksemplene. M3 reproduserte selvstendig et ICLR 2025-paper over ca. 12 timer – 18 commits og 23 eksperimentelle figurer. Den optimaliserte også en FP8 GEMM CUDA-kjerne fra 7,6% til 71,3% maskinvareutnyttelse over 24 timer, med 147 benchmark-innsendinger. Det er en 9,4 ganger speedup. Ingen seriøs utvikler gjør den jobben manuelt på et døgn.
Hva er multimodaliteten verdt?
M3 ble trent multimodalt fra steg 0 – ikke som en tilleggsfunksjon. Det betyr at bildeinput, videoinput og skrivebordsoperasjoner er integrert i modellen, ikke boltet på etterpå. På OmniDocBench – et benchmark for multimodal dokumentforståelse – presterer M3 bedre enn Gemini 3.1 Pro.
Computer use-støtten er interessant i kombinasjon med agentic coding. Modellen kan i prinsippet styre et skrivebord, lese skjermen og kjøre kode – alt i én arbeidsflyt. OSWorld-Verified-scoren på 70,06% antyder at skrivebordsautomatisering faktisk fungerer i praksis, ikke bare i demoer.
Qwen 3.6 hadde også 1 million token kontekst, men ikke samme kodingsprestasjon. M3 kombinerer begge deler i én arkitektur – og legger til computer use på toppen.
Hva koster MiniMax M3?
Prisingen er abonnements-basert via platform.minimax.io:
- Plus: ca. 1,7 milliarder tokens per måned – $20 per måned (ca. 220 kroner)
- Max: ca. 5,1 milliarder tokens per måned – $50 per måned (ca. 550 kroner)
- Ultra: ca. 9,8 milliarder tokens per måned – $120 per måned (ca. 1 320 kroner)
Plus-planen med 1,7 milliarder tokens månedlig er vesentlig mer enn de fleste individuelle brukere trenger. Kall over 512 000 tokens betaler en høyere long-context-rate – viktig å ha i bakhodet hvis man planlegger ekstrem bruk. MiniMax har ikke publisert per-token-priser for API-tilgang utover abonnementspakken ennå.
Hvem bør følge med på MiniMax M3?
Modellen er spesielt interessant for tre grupper. Utviklere som jobber med store kodebaser og trenger en agent som kan holde full kontekst over timer. Forskere og analytikere som trenger å sammenstille mange lange dokumenter i én operasjon. Og de som eksperimenterer med skrivebordsautomatisering og computer use-agenter.
For vanlig chatbruk er M3 sannsynligvis overkill – det finnes billigere og raskere alternativer. Men for jobber der kontekstlengde og agentic kapasitet teller, er dette en reell utfordrer til de store amerikanske modellene.
MiniMax posisjonerer M3 som «første åpen-vekt-modell som kombinerer grensefrontale kodingsprestasjoner, 1M-token kontekst og innebygd multimodalitet i én arkitektur.» Det er et sterkt krav – og i et marked der agentic infrastruktur bygges for fullt, er det noe å følge med på.
Modellvektene er lovet innen ti dager. Det blir interessant å se hva det uavhengige AI-miljøet finner når de begynner å grave i arkitekturen.







