

Innhold Vis
Jeg er genuint blåst avgårde. Kling lanserte sin O1 (Omni One) modell, og dette er ikke bare en ny AI-video-generator. Dette er noe helt annet. Tenk på hvordan Nano Banana endret hvordan vi jobber med bilder – naturlig språk inn, ferdig bilde ut. Nå er det samme skjedd med video.
Det tok meg en halvtime før jeg skjønte hvor radikalt dette egentlig er. Vi snakker ikke om «bedre text-to-video». Vi snakker om at du nå kan si «endre den scenen til solnedgang» eller «fjern den personen fra videoen» – og det bare skjer. Video har blitt like fleksibelt som tekst.
La meg vise deg hvorfor dette er et genuint paradigmeskifte, ikke bare enda en «ny modell».
Hva er Kling O1?
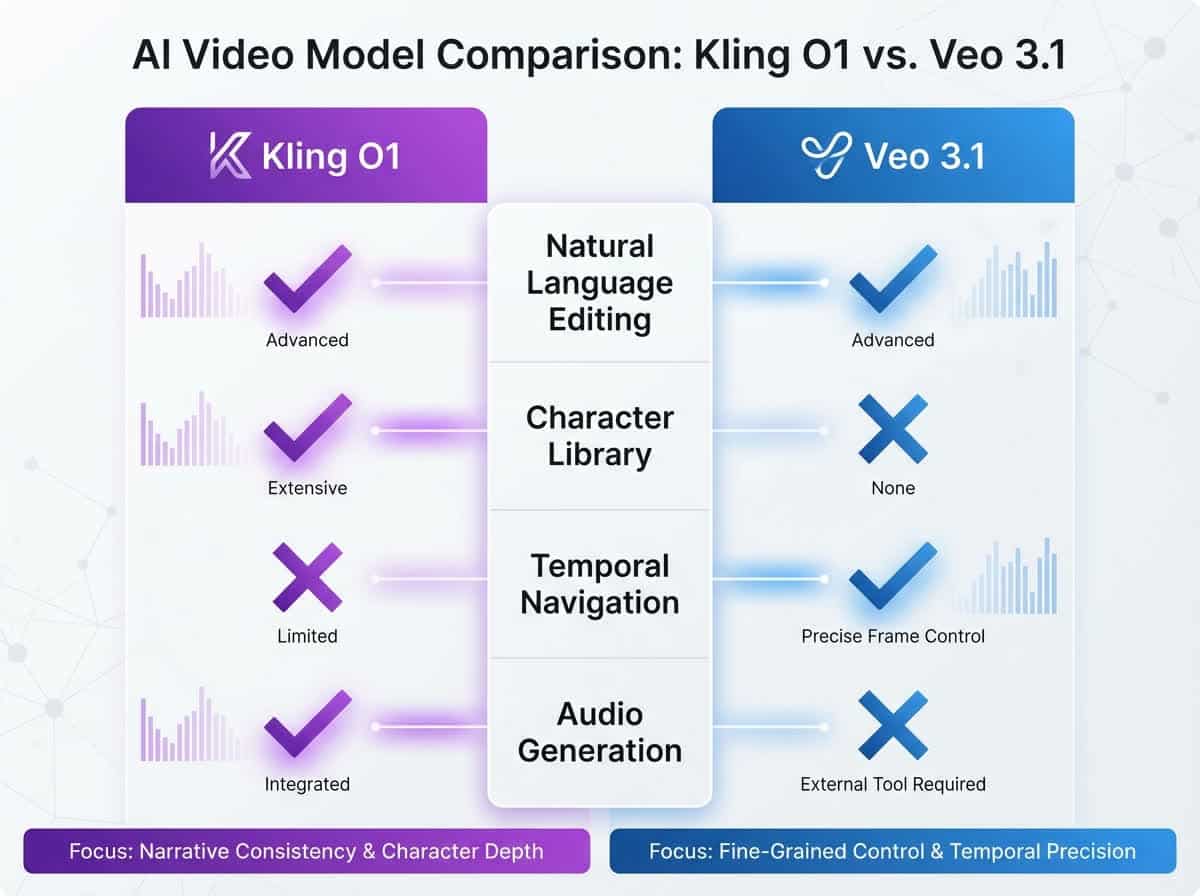
Kling O1 (Omni One) er det kinesiske selskapet Kuaishou sitt svar på Google Veo 3.1 – men med en kritisk forskjell. Der Veo fokuserer på å generere video fra tekst eller bilder, har Kling bygget det de kaller en «unified multimodal video foundation model». I praksis betyr det at én modell håndterer alt:
Text-to-video, image-to-video, video-til-video editing, stylization, object replacement, temporal navigation (før/etter shots), character consistency libraries, location referencing, camera control – alt i ett system. Og det gjør det med en semantisk forståelse som får konkurrentene til å se gammeldagse ut.
Modellen ble lansert akkurat i går, og selv om det er første dag, er kvaliteten og mulighetene absurde. Som noen sa så treffende: «This is the worst it’ll ever be.» På launch day. Det sier alt.

Video som tekst – den store revolusjonen
Her er det jeg mener med paradigmeskifte. Før i dag fungerte AI-video sånn her: Du skrev en prompt, krysset fingrene, ventet 2-5 minutter, og håpet resultatet var brukbart. Hvis ikke? Start på nytt. Helt fra scratch.
Med Kling O1 fungerer det sånn her: Du genererer en baseline-video. Så sier du «actually, change this to sunset». Eller «remove that person». Eller «make this a crane shot instead». Og modellen gjør det – uten å generere hele videoen på nytt, uten å miste konteksten, uten å starte fra null.
Dette er ikke incremental improvement. Dette er video som blir like editerbart som en Google Doc. Du itererer med naturlig språk. Du bygger kompleksitet lag for lag. Du fikser ting etterpå.
La meg gi deg et konkret eksempel som gjorde at jeg måtte ta en pause og bare tenke litt:
En drone-video av Norsk landskap. Dagtid, klar himmel, klassisk Norsk vær. Prompt: «Change it to sunset». Videoen genererer på nytt – samme kamera-movement, samme komposisjon, samme alt. Bortsett fra at det nå er solnedgang. Perfekt lighting, dramatisk himmel, alt annet identisk.
Det tok meg et sekund før det slo meg: Dette er ikke videoredigering. Dette er å beskrive hva du vil endre, og modellen forstår hva som skal forbli likt. Det er semantic understanding på et nivå jeg ikke har sett før i video-AI.
Tre game-changing features jeg må vise deg
La meg bryte ned de tre funksjonene som gjør Kling O1 til noe helt annet enn alt vi har sett før. Eksemplene jeg bruker viser dette bedre enn jeg kan forklare med ord.
1. Natural language video editing
Du tar en eksisterende video – kan være fra Kling selv, kan være fra Veo, kan være live-action footage. Du beskriver hva du vil endre. Det skjer.
Eksempel: En Sora-video med uønskede objekter i bakgrunnen – kanskje en moderne bil i en historisk scene. Prompt: «Remove the white Tesla from the
background in @video1″. Resultatet? Clean video, bilen borte, periode-autentisk scene intact. Ingen artefakter, ingen «ghost» av det som var der.
Et annet: En wide shot av en kvinne som står på en bro. Prompt: «Change to low angle looking up at the subject». Samme scene, nytt perspektiv, smooth
transition.
Dette er ikke «generer en ny video som ligner». Dette er «forstå hva jeg vil beholde og hva jeg vil endre». Det er en fundamental forskjell.
2. Temporal navigation (før/etter shots)
Her blir det virkelig sci-fi. Du kan be modellen om å vise deg hva som skjedde før eller etter din input-video.
Eksempel: En video av en jente som løper ut av en butikk. Prompt: «Generate the previous shot» – hva skjedde før hun løp ut? Modellen genererer en shot av
henne inne i butikken som oppdager noe alarmerende. Dette er ikke bare «reverse the video». Dette er «forstå temporal kontekst og generer logisk foregående
scene».
Eller motsatt: En hund som stirrer intenst på noe utenfor bildet. «Generate the next shot». Kamera svinger rundt og viser en katt på gjerdet. Modellen
forstår narrative flow og skaper en logisk fortsettelse.
Begrensning her: Det er ikke 100% slavish first-frame/last-frame matching. Du må fortelle modellen hva «next» betyr. Men fleksibiliteten er insane når du
først forstår hvordan det fungerer.
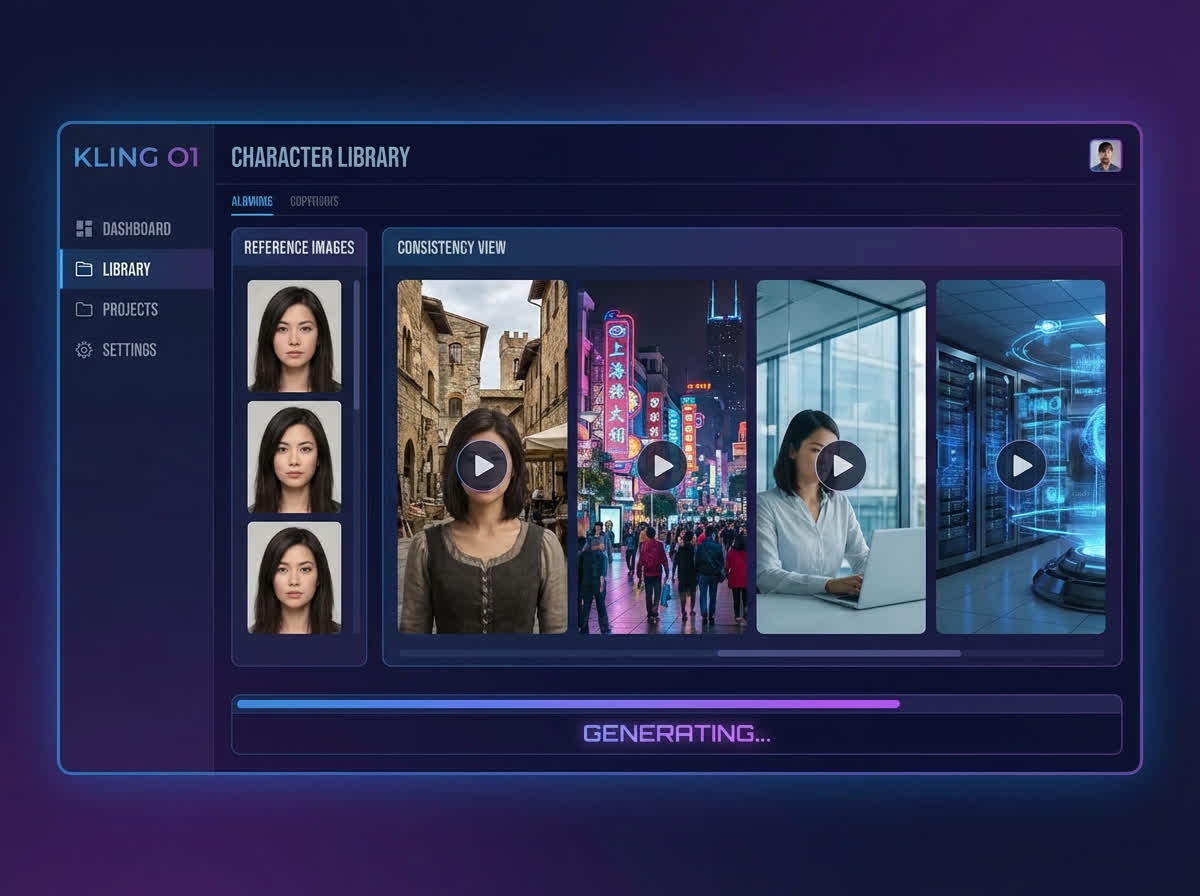
3. Character library for consistency
Dette er kanskje den mest praktiske featuren for content creators. Du kan bygge ditt eget asset library av karakterer og locations, og gjenbruke dem på
tvers av videoer.
Slik fungerer det: Du genererer (eller laster opp) referansebilder av en karakter – front view, side view, full body. Du gir karakteren et navn (f.eks.
«Cyber Detective»). AI-en lager automatisk en beskrivelse, eller du skriver din egen. Så kan du si i hvilken som helst prompt: «Replace character in
@video1 with Cyber Detective».
Eksempel: En syntetisk karakter kalt Cyber Detective ble brukt i en futuristisk neon-setting, på en forblåst ørken-planet, i en noir-aktig gatescene – og
han så identisk ut hver gang. Ikke «tilnærmet lik». Identisk.
Dette slår Sora 2s Cameo-funksjon, ifølge flere testere. Spesielt for syntetiske karakterer (AI-genererte, ikke real photos). Hvorfor? Ukjent, men det
fungerer.
Jeg testet Kling O1 – mine 3 favoritteksempler
Eksempel 1: Viking Barista (layering complexity)
Et bilde av en mann. Prompt 1: «Man walks through forest and discovers cabin». Resultatet? En tracking shot fra en helt annen vinkel enn input-bildet, han
går mellom trær, hytta eksisterer ikke engang i det originale bildet. Dette er ikke tradisjonell image-to-video hvor første frame = input. Dette er
semantic direction.
Prompt 2: «A Viking warrior is standing outside the cabin. Man approaches cautiously». Samme video, nå med en viking-kriger. Prompt 3: «Change Viking in
@video1 to @image1″ (et annet viking-bilde). Ny viking, samme scene, samme timing.
Hva dette viser: Du kan iterere og bygge kompleksitet lag for lag. Dette er ikke «one shot and pray». Dette er creative iteration.
Eksempel 2: Tokyo Street rain (vær-kontroll)
Jeg nevnte denne tidligere, men den fortjener sin egen seksjon fordi implikasjonene er enorme. Tracking shot av travle Tokyo-gater, clear weather. «Add
heavy rain and wet reflections». Perfekt rain effects, våte refleksjoner på asfalt, alt annet forblir identisk.
Hva dette betyr: Du kan shoot en scene én gang og generere multiple versjoner for forskjellige værforhold. Ingen reshoots. Ingen VFX-team. Bare naturlig
språk.
Eksempel 3: Sora til live-action (cross-model workflow)
Dette var det mest kreative. En realistisk Veo-output (to astronauter på Mars-overflate) ble tatt gjennom en multi-step workflow. Steg 1: Bruk Kling O1
image model til å legge til alien structures i bakgrunnen. Steg 2: Generer video med de modifiserte frames. Steg 3: Legg til en holografisk AI-guide som
mid-scene reference (ikke last frame!).
Resultatet? En hybrid sci-fi video med spektakulær hologram reveal. Dette var ikke bare én modell. Dette var en workflow på tvers av Veo og Kling som låser
opp noe ingen av dem kan gjøre alene.
Hva dette viser: Vi er ikke lenger begrenset til én modells capabilities. Vi kan kombinere styrker på tvers av systemer.
Kling O1 vs Veo 3.1 – hvem vinner?
Google lanserte Veo 3.1 for noen uker siden, og det var stort. Multimodal, high quality, native audio generation. Men etter å ha sett Kling O1 i dag, føles Veo 3.1 allerede… gammeldags? Det er rart å si det om en modell som er uker gammel, men her er vi.
Der Kling O1 vinner klart:
Video-til-video editing med naturlig språk. Veo kan ikke dette. Du må generere på nytt hver gang. Custom subject library for character consistency. Veo har ikke dette. Temporal navigation (før/etter shots). Veo kan ikke dette. Multi-element consistency (flere karakterer/locations samtidig). Veo struggeler her.
Community consensus fra testers er at Kling O1 har bedre character retention og mer presis kontroll. Feedback fra AI Inc, flux-ai.io, DeeVid, og flere testers på X/Twitter bekrefter dette.
Der Veo 3.1 fortsatt har fordelen:
Native audio generation. Kling O1 har ikke lyd enda (men det kommer sannsynligvis). Google ecosystem integration – hvis du allerede bruker Google-verktøy, er Veo enklere å integrere. Muligens mer tilgjengelig (Google scale vs Kuaishou).
Min take? For ren generering av video fra scratch: Veo 3.1 og Kling O1 er omtrent like gode, avhengig av use case. Men for iteration, editing, creative control? Kling O1 er i en helt annen liga. Dette er ikke engang en konkurranse.
Og husk: Dette er dag 1. Som noen sa så treffende: «This is the worst it’ll ever be.»
Hva dette betyr for norske content creators
La meg skissere noen konkrete use cases som faktisk er relevante:
Content creators og YouTubere: Fikse gamle Veo eller Sora outputs. Fjerne uønskede objekter, forbedre framing, endre lighting – uten å generere på nytt.
Bygge character consistency på tvers av video-series. Teste shot compositions raskt uten reshoots.
Markedsføringsbyråer: Quick seasonal variations (samme ad, forskjellig vær/tid på dagen). Product placement (swap objekter i eksisterende footage). A/B
testing av visuelle stiler uten å produsere flere versjoner.
Filmstudenter og indie-filmskapere: Pre-vis med faktisk video, ikke bare storyboards. Character design iteration uten skuespillere. Teste narrative flow
(hva skjer før/etter denne scenen?).
Hobbyister og eksperimentelle creators: Hybrid workflows på tvers av Sora, Veo, Kling. Stylization (turn live-action animated, eller motsatt). Accessible
filmmaking uten crew eller utstyr.
Et ord om GDPR og data: Kuaishou er et kinesisk selskap (samme folk bak Kwai, TikTok-konkurrenten). Hvis du jobber med sensitive data eller klienter med
strenge compliance-krav, bør du være obs på data sovereignty. Ingen eksplisitt GDPR compliance info er tilgjengelig ennå. For hobbybruk eller content
creation? Sannsynligvis ikke et problem. Men vær klar over det.
Slik kommer du i gang (praktisk guide)
Ok, du vil prøve dette. Her er min anbefaling for hvordan du starter.
Steg 1: Gå til app.klingai.com
Registrer deg hvis du ikke har konto. Jeg har en affiliate-link som gir deg 50% bonus credits (opptil 5000 credits) første måneden. Jeg
får også en provisjon hvis du bruker linken. Dette er helt frivillig – du kan registrere deg direkte hvis du heller vil det. Men hvis du skal teste
uansett, hvorfor ikke få ekstra credits?
Registrer en Kling AI konto på klingai.com nå!
Når du er inne: Naviger til O1-fanen – dette er separat fra de gamle Kling 1.0/2.0 modellene (de er fortsatt tilgjengelige, men O1 er der magien skjer).
Steg 2: Start enkelt
Ikke hopp rett til advanced workflows. Test text-to-video med en klar, spesifikk prompt. Eksempel: «Drone shot flying over Norwegian fjord at sunset, 16:9, cinematic». Se hva du får. Lær hvordan modellen tolker prompts.
Steg 3: Test image-to-video MED location reference
Dette er kritisk: Providing en location image reference gir massiv quality boost. Uten det? Generic, flat lighting, karakterer ser pasted in ut. Med det? Dynamic camera, proper color grading, integrerte karakterer.
Eksempel: «Standing on busy Shanghai street» uten referanse = meh. Samme prompt med «@image3 (Shanghai street photo)» = professional output.
Steg 4: Bygg character library
Bruk Kling O1 image model til å generere referansebilder (front, side, full body). Gi karakteren et navn og beskrivelse. Nå kan du gjenbruke den i hvilken som helst video. Pro tip: Syntetiske karakterer (AI-genererte) holder bedre consistency enn real photos. Hvorfor? Ingen vet, men det er sånn det er akkurat nå.
Steg 5: Eksperimenter med video editing
Last opp en gammel video (Veo output, Sora output, hva som helst). Prøv enkle edits: «Remove that object», «Change lighting to sunset», «Make this a wide shot instead». Se hvordan modellen interpreterer instruksjonene dine.
Steg 6: Utforsk temporal navigation
Generer en scene. Be om «the previous shot» eller «the next shot». Vær spesifikk om hva «previous» eller «next» betyr – modellen trenger context. Men når det funker? Mind-blowing.
Pro tips: Always reference location images. Iterate med naturlig språk – bygg kompleksitet lag for lag. Forvent å måtte color-correcte character swaps (minor quirk, ikke deal-breaker). Start med 16:9 for familiarity. Vær tålmodig – dette er dag 1, bugs og quirks er forventet.
Konklusjon – paradigmeskiftet er her
Jeg har dekket AI-verktøy i over et år nå. Jeg har sett GPT-4, Claude 3.5 Sonnet, Gemini 2.0 Flash, DALL-E 3, Midjourney, Nano Banana, Sora, Veo – hele greia. Og jeg er genuint blåst avgårde av Kling O1 på en måte jeg ikke har vært siden ChatGPT droppet i 2022.
Dette er ikke «bedre text-to-video». Dette er en helt ny kategori: natural language video editing. Video er nå like malleabelt som tekst. Du kan si «endre den scenen til solnedgang» eller «fjern den personen» og det bare skjer.
Før Kling O1: Generer video, kryss fingrene, håp det er riktig. Hvis ikke? Start på nytt.
Etter Kling O1: Generer baseline. Iterer med naturlig språk. Bygg kompleksitet lag for lag. Fikse ting etterpå.
For norske creators er dette en gold mine. Null norsk coverage ennå. Engelsk community går amok. Use cases er endless. First-mover advantage for de som hopper på nå.
Og husk: Dette er dag 1. Dette er the worst it’ll ever be. Tenk på det.
Hva tenker du? Er dette noe du kommer til å teste? Hva er ditt første use case? Del gjerne i kommentarfeltet – jeg er genuint nysgjerrig på hvordan norske creators kommer til å bruke dette.
Jeg skal nå teste dette videre selv. Mer kommer sikkert etterhvert som jeg får mer erfaring med modellen. Vi sees på den andre siden av paradigmeskiftet.







