

Innhold Vis
Xiaomi er mest kjent for telefoner og elektriske sparkesykler. Så det var litt av en overraskelse da selskapet 18. mars 2026 slapp MiMo-V2-Pro – en AI-modell med over 1 billion parametere som ranker som nr. 3 globalt på agent-benchmarks, rett bak Claude Opus 4.6. Og til en åttendedel av prisen.
Det er ikke en tilfeldig satsing. Ledeforskeren bak MiMo-V2 kommer fra DeepSeek. I en uke kjørte modellen anonymt på OpenRouter under kodenavnet "Hunter Alpha" – ingen visste hvem som sto bak. Utviklere testet den, roste den, og antok den var noe helt annet. Totalt ble det prosessert over 1 billion tokens før Xiaomi avslørte at det var dem.
Resultatet av den uformelle avsløringen? Xiaomi er nå en aktør i det globale AI-kappløpet. Her er hva modellene faktisk kan, hva de koster, og hvorfor dette er et varsel om at priskrigen på AI-inferens bare har begynt.
Hva er Xiaomi MiMo-V2-Pro?
MiMo-V2-Pro er Xiaomis flaggskip-modell, bygd for agentiske arbeidsoppgaver. Den har over 1 billion totale parametere, men bruker bare 42 milliarder aktive parametere per pass – en Mixture-of-Experts-arkitektur som lar den skalere uten å svi av all regnekraft til enhver tid.
Kontekstvinduet er 1 million tokens. Det er det samme som Holotron-12B fra H Company og NVIDIA fikk mye skryt for – men her snakker vi om en modell som direkte konkurrerer med toppmodellene, ikke mellomsjiktet.
Hva betyr "designet for agentiske oppgaver" i praksis? Modellen er trent for å orkestrere komplekse arbeidsflyter, drive produksjonsteknikk og håndtere sekvensielle beslutninger over lange kjøringer. Det er det som skiller agent-AI fra vanlig chat-AI: modellen trenger ikke bare å svare riktig én gang, den må ta konsistente valg gjennom mange steg.
Benchmarks – Hvor god er den egentlig?
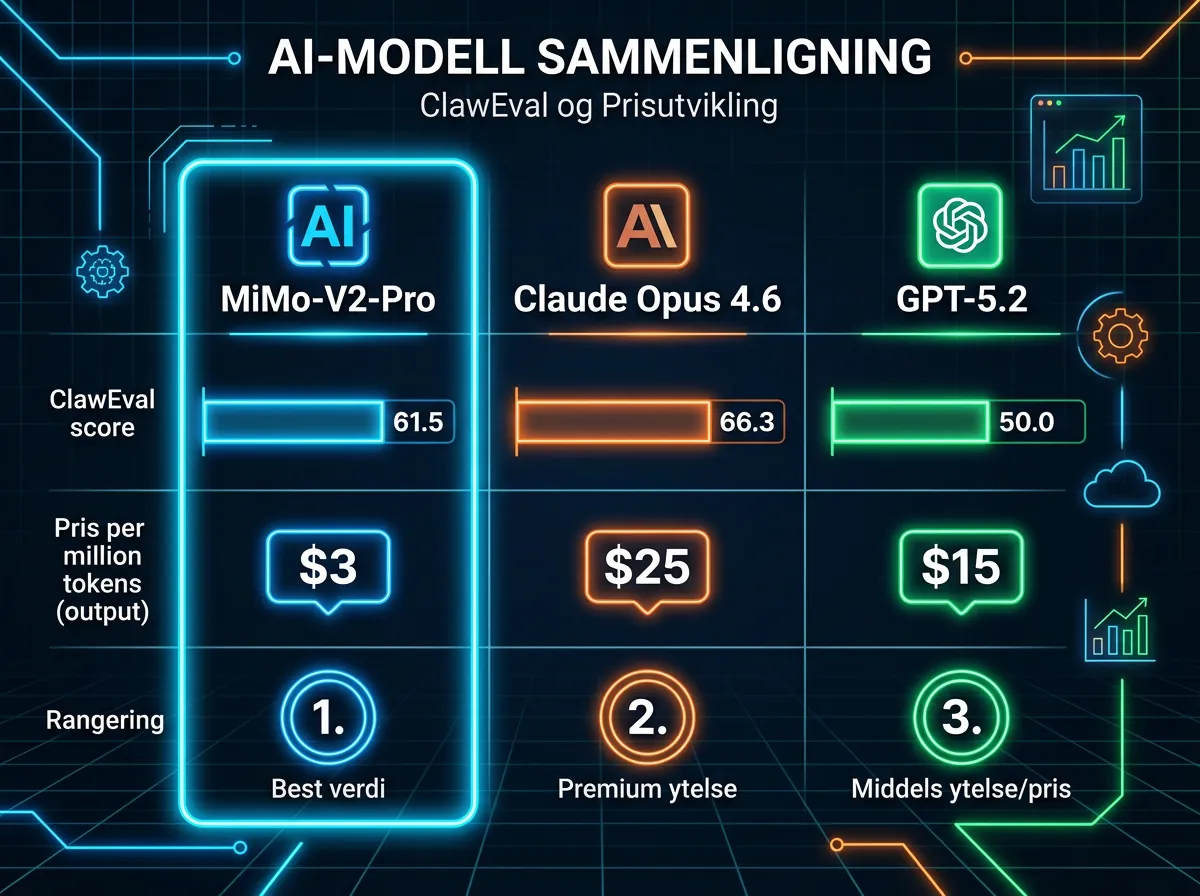
På ClawEval, en benchmark for agentiske oppgaver, scorer MiMo-V2-Pro 61,5. Claude Opus 4.6 ligger på 66,3. GPT-5.2 henger etter med 50,0. Det er med andre ord nr. 3 globalt – og gapet opp til Opus 4.6 er mye mindre enn gapet ned til GPT-5.2.
På SWE-bench Verified – den mest anerkjente testen for kode-AI – slår MiMo-V2-Pro faktisk Claude Sonnet 4.6. Søstermodellen MiMo-V2-Flash gjør det enda mer imponerende: den rangerer som #1 åpen kildekode-modell globalt på SWE-bench, og leverer ytelse sammenlignbar med Claude Sonnet 4.5 til en brøkdel av prisen.
For å sette det i perspektiv med rene kostnader: Artificial Analysis kjørte sin Intelligence Index-benchmark og betalte 348 dollar for MiMo-V2-Pro. Den tilsvarende kjøringen med Claude Opus 4.6 kostet 2 486 dollar. Samme oppgave, 7 ganger lavere pris.
Hva koster MiMo-V2-Pro sammenlignet med Claude?
Her er tallene direkte:
- MiMo-V2-Pro: $1 per million input-tokens, $3 per million output-tokens (opp til 256K kontekst)
- Claude Opus 4.6: $5 per million input-tokens, $25 per million output-tokens
Det vil si 5 ganger dyrere inn, og over 8 ganger dyrere ut. For lange agent-kjøringer der output er det store volumet, er forskjellen enda mer dramatisk i praksis.
MiMo-V2-Flash er søstermodellen – 309 milliarder parametere, åpen kildekode, og tilgjengelig på OpenRouter til kun $0,10 per million tokens. Det er ekstremt billig for en modell som topper SWE-bench blant åpne modeller. For kontekst: de fleste andre open source-modeller i den klassen koster 5-10 ganger mer per million tokens.
Hunter Alpha – historien bak det mystiske kodenavnet
Det er denne historien som gjør lanseringen interessant utover de tørre tallene.
En uke før den offisielle lanseringen dukket det opp en ny modell på OpenRouter kalt "Hunter Alpha". Ingen attribusjon, ingen selskapsinfo. Bare en modell.
Utviklere begynte å teste den. Tilbakemeldingene strømmet inn – rask, nøyaktig på kode, god på sekvensielle oppgaver. Noen lurte på om det var DeepSeek V4 under testing. Andre spekulerte på om det var en OpenAI-lekk. Den toppet daglige bruksrangeringer og samlet over 1 billion tokens i produksjonskjøringer, alt mens Xiaomi satt stille.
Så kom 18. mars: Xiaomi avslørte at Hunter Alpha var MiMo-V2-Pro, og at ledeforskeren bak prosjektet kom fra DeepSeek. Akkurat den bakgrunnen forklarer mye – DeepSeek-teamet har vist at de vet hvordan man trener effektive modeller uten å kaste bort regnekraft, og den filosofien ser ut til å ha fulgt med over.

Er det en skeptisk tanke å ha om kinesiske AI-modeller?
Jeg er åpen om at jeg har en viss skepsis til kinesiske modeller generelt – ikke fiendtlighet, men bevissthet om at data kan gå andre steder enn man forventer. Det er de samme spørsmålene jeg stilte da Qwen 3.5 kom og da DeepSeek eksploderte på rankingene.
MiMo-V2-Flash er åpen kildekode – du kan laste ned vektene og kjøre den lokalt. Det fjerner databekymringen helt, og da handler det bare om ytelse og kostnader. Der ser tallene faktisk gode ut.
MiMo-V2-Pro er derimot API-only for nå. Og det betyr at data prosesseres på Xiaomis infrastruktur. For eksperimenter og testing er det én ting. For sensitive arbeidsoppgaver i produksjon er det et spørsmål man bør stille seg – akkurat som med GLM 4.7, akkurat som med alle andre kinesiske modeller.
MiMo-V2-Flash – den åpne kildekode-broren
Søstermodellen fortjener sin egen omtale. MiMo-V2-Flash er 309 milliarder parametere totalt, med 15 milliarder aktive per pass. Den er fullt åpen kildekode tilgjengelig på GitHub, og bruker en hybrid attention-arkitektur optimert for effektiv inferens.
På SWE-bench Multilingual – som tester kodeforståelse på tvers av programmeringsspråk – er den beste åpne modellen som finnes akkurat nå. Den leverer ytelse sammenlignbar med Claude Sonnet 4.5, til omtrent 3,5% av prisen. Ja, du leste riktig.
For de som vil eksperimentere uten kostnadsproblematikk og uten API-avhengighet til et kinesisk selskap, er Flash det naturlige startpunktet. Du kan kjøre den lokalt med nok VRAM – med 15 milliarder aktive parametere er kravene faktisk håndterlige for en moderne arbeidsstasjon.
Hva betyr dette for AI-markedet fremover?
Det som skjer er ikke at Xiaomi plutselig er blitt et AI-laboratorium. Det som skjer er at toppytelsen – det som for seks måneder siden bare fantes hos OpenAI og Anthropic – nå spres til stadig flere aktører. Og priskrigen som følger av det er langt fra ferdig.
Vi har sett dette mønsteret med DeepSeek R1, med Qwen, med GLM. Hver gang kommer en ny kinesisk modell og setter under seg halvparten av benchmark-listen til en brøkdel av prisen på vestlige alternativer. Noen av dem er åpne. Noen er ikke det.
For deg som bruker AI-modeller i arbeidet ditt: dette betyr at du allerede nå kan kjøre agent-oppgaver i klasse med topp-3 globalt til under $1 per million input-tokens. For seks måneder siden krevde det $15-$25. Det er en strukturell endring, ikke bare en ny modell i rekken.
Hva tenker du? Er dette en modell du vil teste, eller er skepsisen til kinesisk infrastruktur et dealbreaker? Send gjerne en kommentar under.








1 kommentar