

Innhold Vis
Stanford HAI ga ut 2026 AI Index-rapporten i april 2026 – en av de mest omfattende årlige gjennomgangene av AI-feltet som finnes. Rapporten dekker ni kapitler og hundrevis av datapunkter. Men ett funn skiller seg ut fra resten: AI har blitt så avansert at vi knapt vet hvordan vi skal måle det lenger.
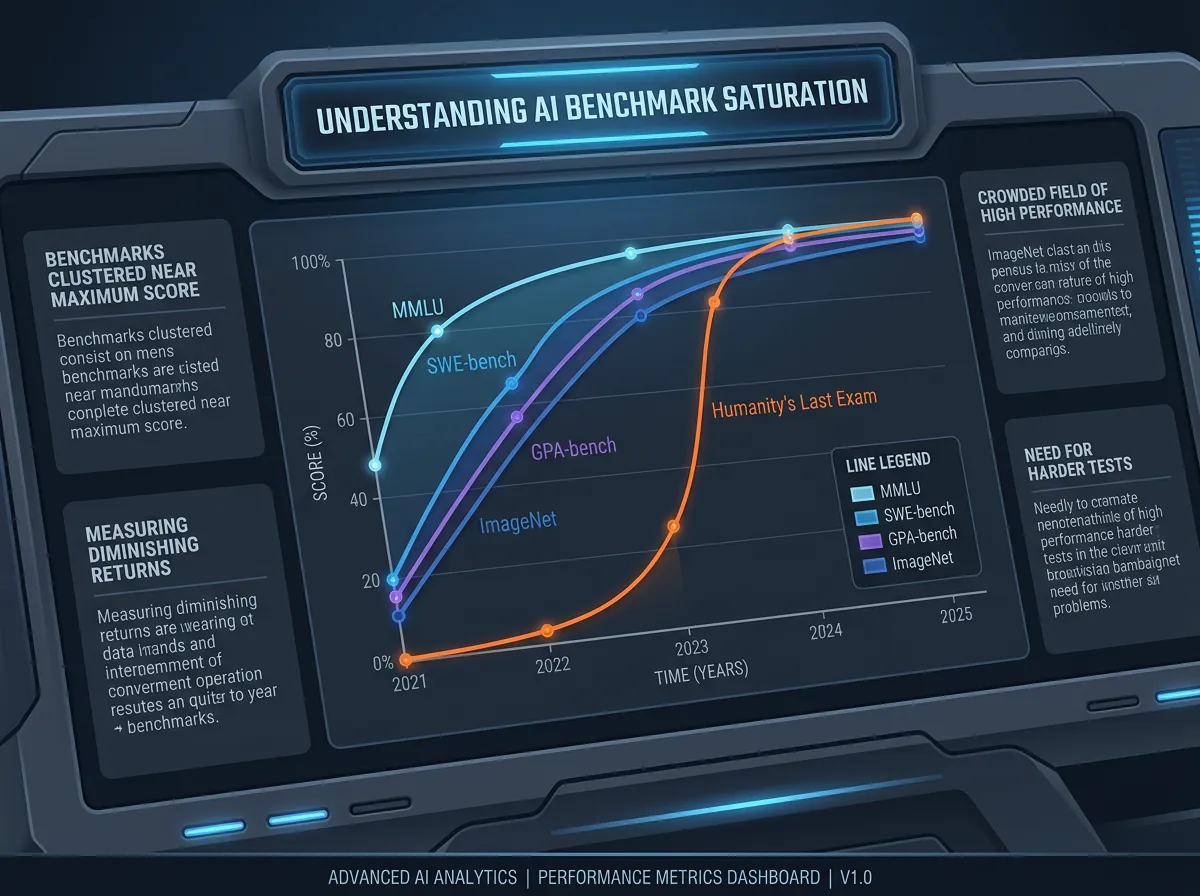
Det er litt absurd, egentlig. Vi bygger systemer som løser PhD-nivå matematikk og vinner gull i internasjonale kjemiolympiader – og så klarer vi ikke å lage en test som faktisk forteller oss hvor gode de er. Benchmarkene løper tørt. Tallene blinker grønt, men betyr de noe?
Her er de viktigste funnene fra rapporten – og hva de faktisk betyr for deg som følger med på AI-utviklingen.
Hva er Stanford AI Index-rapporten?
Stanford Institute for Human-Centered AI (HAI) har publisert AI Index-rapporten siden 2017. Det er en uavhengig akademisk gjennomgang som prøver å gi et ærlig bilde av hvor AI-feltet står – ikke markedsføring, ikke PR, men data. Rapporten for 2026 er ni kapitler og dekker alt fra teknisk ytelse og forskning til økonomi, utdanning, helsevesen og offentlig mening.
Det er altså ikke en liten notis. Det er den mest grundige uavhengige oversikten vi har over AI-utviklingen, og den kom ut akkurat nå i april 2026. Og den har ting å si.
Hva mener rapporten med at AI er vanskelig å måle?
La meg begynne med det som faktisk er kjernen i problemet: benchmarkene saturerer. Det betyr at de eksisterende testene er blitt for lette. AI-modellene scorer så høyt at testene ikke lenger kan skille mellom modeller – eller si noe meningsfullt om fremgang.
Humanity’s Last Exam er et godt eksempel. Testen ble laget av eksperter for å være nesten umulig for AI. Fra under 10 prosent riktig til 38,3 prosent på ett år. Det er ikke stagnasjon – det er eksplosiv vekst. Men det betyr også at den testen snart er for enkel.
Og her er paradokset som rapporten setter fingeren på: Benchmarkene sier ikke noe om virkeligheten. Perrault fra Stanford sier det rett ut: «Vi mangler generelt mål for hvor godt et system trenger å fungere i en bestemt setting. Å vite at en benchmark for juridisk resonnering har 75 prosent nøyaktighet forteller oss lite om hvor godt det passer i en advokatfirmas faktiske aktiviteter.»
Det er et ganske alvorlig problem for et felt som bruker benchmarks til å selge produkter, overbevise investorer og argumentere for regulering.
Vendor-benchmarks vs. virkeligheten – et 69 prosent gap
Her er et konkret eksempel på målings-problemet som rapporten løfter frem. AI-selskaper rapporterer hallusinasjonsproblemer på under 1 prosent i sine egne benchmarks. Stanfords uavhengige juridiske AI-forskning finner 69 til 88 prosent feilrate på komplekse dokumentoppgaver som faktisk definerer hvordan advokater bruker AI.
Det er ikke litt av. Det er en forskjell mellom «nesten perfekt» og «ubrukelig i praksis» – avhengig av hvem som tester.
Jeg har skrevet tidligere om hvordan AI-agent benchmarks kan bli «brutt» av forskere som scorer 100 prosent uten å løse oppgavene som var tenkt. Det er samme fenomen. Benchmarks er designet av mennesker, og de kan optimeres mot – uten at det nødvendigvis betyr fremgang i praksis.
Det er litt som en skoleklasse som øver bare på fjorårets eksamen. Karakterene går opp. Men har de faktisk lært mer?
Transparensskår falt fra 58 til 40
Her er noe som bekymrer meg mer enn benchmark-problemene: AI-selskapene blir mindre åpne, ikke mer.
Foundation Model Transparency Index – et uavhengig mål på hvor åpne de store AI-selskapene er om treningskode, datasett og modellparametere – falt fra 58 poeng i 2025 til 40 poeng i 2026. Det er et fall på 31 prosent på ett år. De mest kraftfulle modellene er nå blant de minst transparente.
De store selskapene holder data for seg selv. De sier ikke hva de trener på, ikke hvor store modellene er, ikke hva de faktisk kan og ikke kan. Og jo mer kapabel en modell er, jo mindre vet vi om den, ifølge rapporten.
Det er et problem for alle som skal vurdere AI-systemer – enten det er forskere, bedrifter eller vanlige folk som vil forstå hva de bruker. Hvis vi ikke vet hva vi måler fordi vi ikke har tilgang til grunnlagsdata, er all evaluering på gyngende grunn.

Kapabilitetene eksploderer uansett
Midt i all målings-usikkerheten er det én ting som er ubestridt: AI-kapabilitetene øker raskt. Veldig raskt.
SWE-bench er en test for kodegenerering – evnen til å løse virkelige programvare-feil. Modeller gikk fra 60 prosent til nesten 100 prosent på ett år. Generativ AI har nådd 53 prosent global befolkningsadopsjon på bare tre år – raskere enn PC eller internett noensinne klarte det.
AI-modeller matcher eller overgår menneskelig ytelse på PhD-nivå vitenskap, matematikk og multimodal resonnering. Det er ikke lite. Det er det Jensen Huang og Greg Brockman har snakket om – og Stanford-rapporten bekrefter tallene med uavhengige data. Jeg har tidligere skrevet om Greg Brockmans påstand om at OpenAI er 70-80 prosent fremme mot AGI – og om Jensen Huangs omdiskuterte AGI-definisjon. Stanford-rapporten er mer forsiktig, men kapabilitetstallene er de samme.
Kina er 2,7 prosent bak USA
Et annet stort funn: USA-Kina-gapet er nesten borte. Kinas beste modeller ligger 2,7 prosent bak på benchmark-kurver. DeepSeek-R1 konkurrerte med toppmodeller fra OpenAI og Anthropic i februar 2025, og utviklingen har ikke stoppet der.
Haken er selvfølgelig det vi diskuterte over: de benchmarkene Kina er 2,7 prosent bak på, er de samme benchmarkene Stanford sier saturerer og mister mening. Men retningen er klar nok – det er ikke lenger snakk om at én aktør dominerer AI-feltet.
Det absurde paradokset – gull i matte, kan ikke lese klokke
Stanford-rapporten dokumenterer noe som er fascinerende og litt urovekkende på samme tid. Det samme systemet som vinner gull i matematikk-olympiader kan bare lese analoge klokker riktig 50 prosent av tiden. En modell som aces PhD-nivå vitenskap kan hallusinere referanser til artikler som ikke finnes.
Dette er ikke tilfeldig. Det er en strukturell egenskap ved dagens AI-systemer. De er ekstremt kapable på smale, veldefinerte oppgaver – og overraskende svake på ting vi tar for gitt. Og fordi benchmarkene ikke måler det vi faktisk bryr oss om i praksis, skjuler de dette gapet.
Konklusjonen fra rapporten er enkel: test AI på dine egne oppgaver, ikke på noens andres benchmark-suite. Det er et råd som er lettere sagt enn gjort for de fleste – men det er den eneste måten å vite hva du faktisk kjøper.
Hva betyr dette for deg som bruker AI?
Kanskje det viktigste praktiske takeawayet fra en slik rapport: ikke stol blindt på benchmark-tall når du velger AI-verktøy. En modell som scorer høyest på leaderboards er ikke nødvendigvis den beste for jobben din. Det eneste pålitelige er å teste på dine faktiske oppgaver.
Jeg har testet dette selv gjentatte ganger. Modeller som virker svakere på papir kan slå «sterkere» modeller på spesifikke oppgaver jeg faktisk bruker dem til. Og jo mer spesialisert oppgaven er, jo mer slår den effekten inn.
Det er noe litt frigjørende i Stanford-rapporten, faktisk. Den forteller oss at all hype-maskinene og benchmark-kappløpet er mer støy enn signal. AI er kraftfullt nok til å endre hvordan vi jobber – men det er ikke leaderboard-plasseringen som avgjør om det er nyttig for deg.
Hva tenker du? Bruker du benchmark-tall når du velger AI-verktøy, eller tester du bare direkte?







