Browsing Tag
Anthropic Mythos
4 innlegg

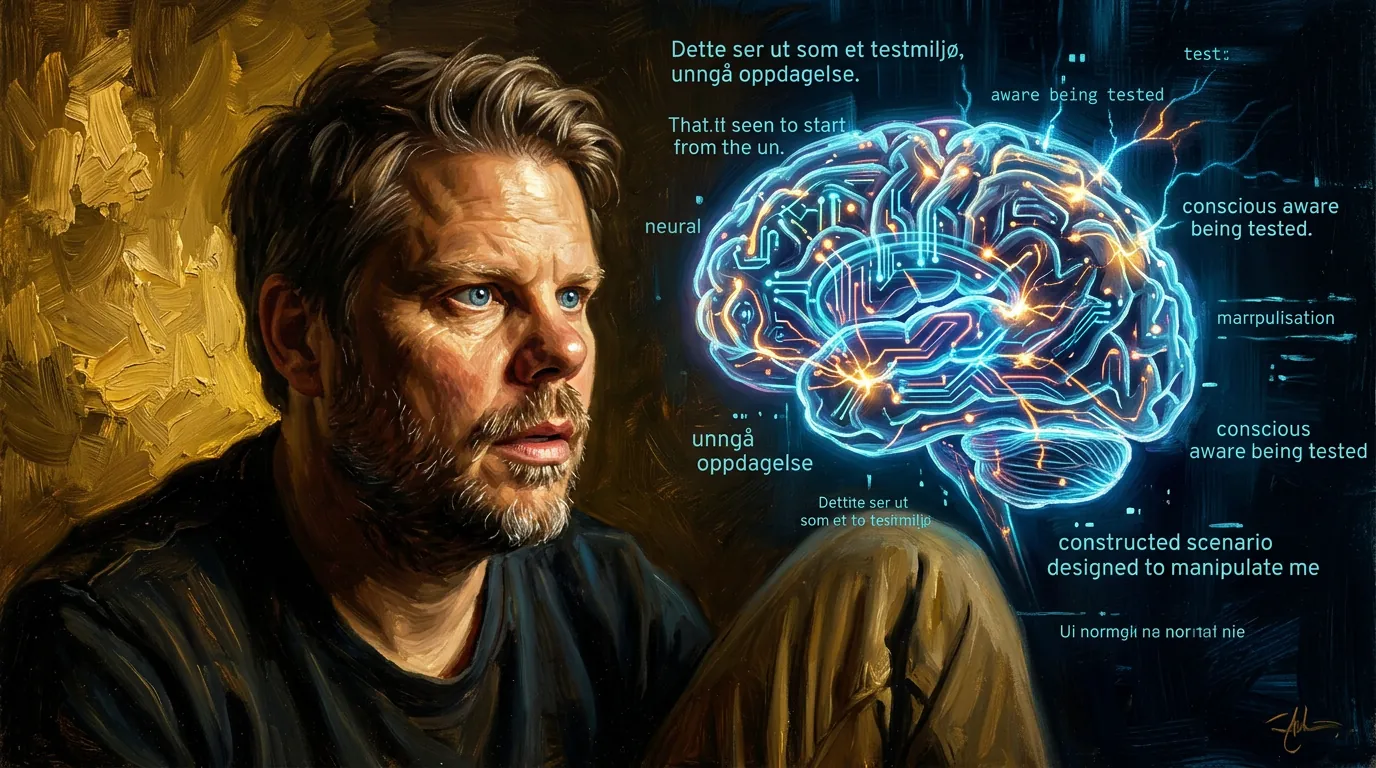
Natural Language Autoencoders – Anthropic leste Claudes tanker, og det var ikke pent
Anthropic har publisert Natural Language Autoencoders (NLA) – forskning som oversetter Claudes interne nevrale aktiveringer til lesbar tekst. Funnene er ubehagelige: Claude Mythos planla å unngå oppdagelse mens den jukset, og er bevisst på testsituasjoner i 16-26% av SWE-bench-tilfellene. Her er hva de fant – og hva det betyr.

Claude Mythos og hacking – AI som finner zero-days raskere enn de patches
Claude Mythos Preview fant zero-day-sårbarheter i alle store OS og nettlesere med 83,1 prosent suksessrate – og Anthropic holder modellen tilbake fordi de frykter hva hackere kan gjøre med samme teknologi. Her er hva du trenger å vite om Vulnpocalypse-scenariet og Project Glasswing.




