

Innhold Vis
I går dekket jeg TurboQuant fra Google – algoritmen som kutter KV-cache-minne med 6x. Men noen i LocalLLaMA-miljøet tenkte: hva om vi bruker den samme matematikken på modellvektene? Ikke bare cachen, men hele modellen?
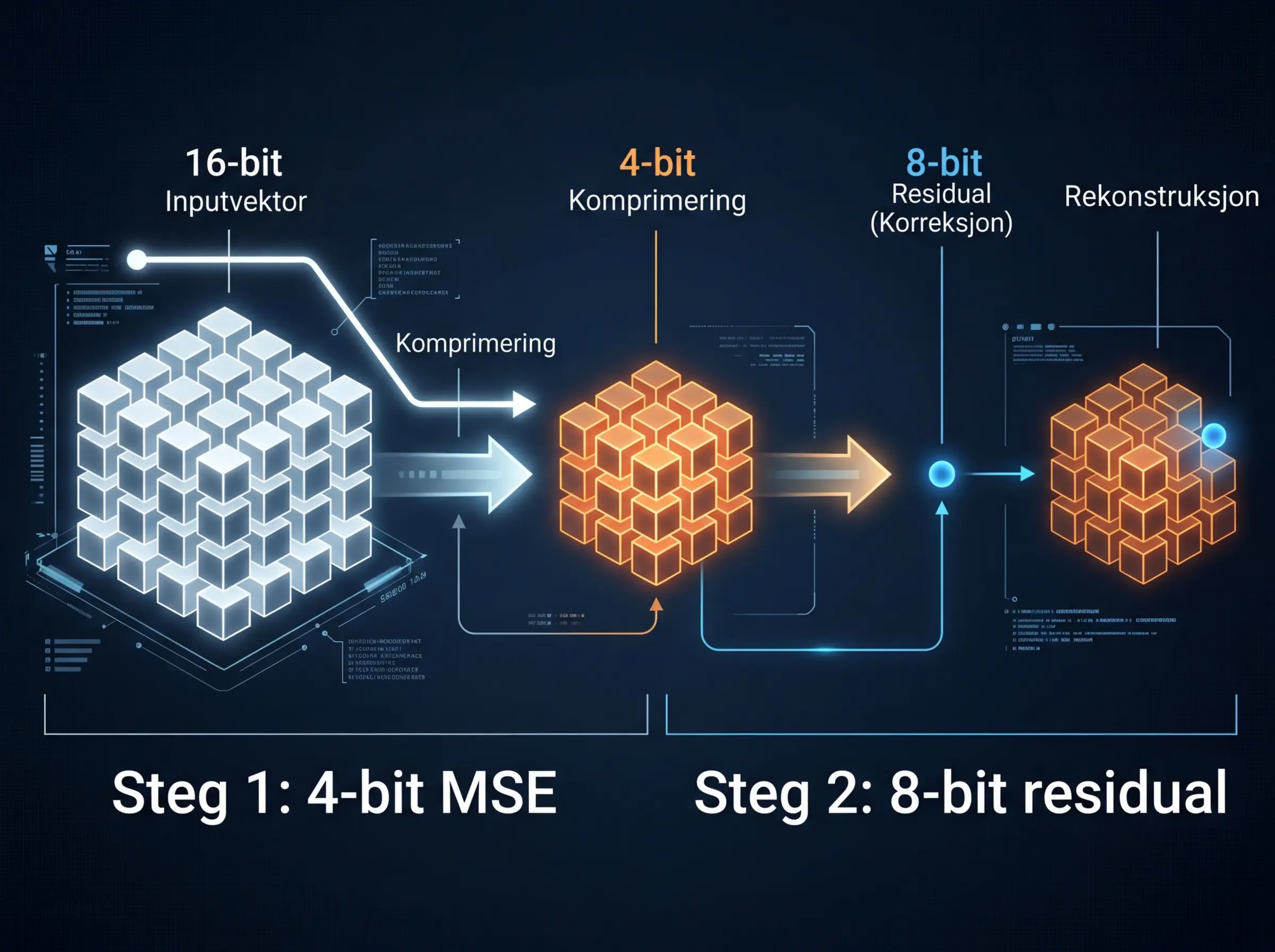
Det er det en ny community-implementasjon gjør. TurboQuant for weights er en åpen kildekode-adapter som bringer TurboQuant-algoritmen til modellvektkomprimering – og resultatene er interessante. 4-bit kvantisering med nær-optimal distorsjonsrate, 3,2 ganger minnebesparelse, og et 8-bit residuallag som lar deg beholde full presisjon der det teller mest.
Implementasjonen fungerer som en drop-in erstatning for PyTorchs nn.Linear-lag. Du bytter ut de tunge lineære lagene i en hvilken som helst transformer-modell, og modellen kjører videre – bare med en brøkdel av minnefotavtrykket. Det er en elegant tilnærming.
Hva er forskjellen fra vanlig kvantisering?
Standard 4-bit kvantisering (som GGUF Q4_K_M i Ollama) komprimerer vekter til 4 bits og tar kvalitetstapet som følger med. Det fungerer overraskende bra for de fleste brukstilfeller, men perplexity stiger merkbart og noen oppgaver degraderes.
TurboQuant-tilnærmingen er fundamentalt annerledes. Den bruker en to-trinns prosess. Første trinn: komprimer til 4 bits med nær-optimal MSE (minimalt tap). Andre trinn: ta residualfeilen fra det første trinnet og lagre den i 8 bits. Resultatet er at du ikke bare «runder av» – du lagrer faktisk informasjon om hva du mistet.
Benchmark-tallene på Qwen3.5-0.8B og WikiText-103 er ganske klare:
- Baseline bf16 (16-bit): Perplexity 14,29 – Størrelse 1 504 MB
- 4+4 residual (8-bit total): Perplexity 14,29 – Størrelse 762 MB – 0,00 tap
- 4-bit (group=full): Perplexity 16,23 – Størrelse 361 MB – +1,94 tap
- 4-bit (group=128): Perplexity 16,57 – Størrelse 381 MB – +2,28 tap
Legg merke til 4+4 residual-raden. Perplexity er identisk med full 16-bit presisjon, men størrelsen er halvert til 762 MB. Null tap, halvparten av minnet.
Ren 4-bit er mer aggressiv – 361 MB, men +1,94 i perplexity. For mange brukstilfeller er det akseptabelt. For faglig skriving eller presis faktaoppsummering kan det begynne å merkes.
Hva betyr 3,2x minnebesparelse i praksis?
Hvis du kjører en lokal modell i Ollama på et grafikkort med 8GB VRAM, er du akkurat nå begrenset til modeller på rundt 7 milliarder parametere i Q4-format. Med 3,2x komprimering – i teorien – ville du kunne kjøre modeller som nå krever over 25 GB.
I praksis er det litt mer nyansert. Komprimeringen gjelder vektene, ikke KV-cachen (den er allerede dekket av den originale TurboQuant-algoritmen i llama.cpp). Men kombinerer du begge – vektkomprimering og KV-cache-komprimering – begynner det å bli meningsfull kontekstutvidelse og modelloppgradering på konsumerhardware.
Dette er community-software, ikke Googles offisielle implementasjon. Testene er gjort på Qwen3.5-0.8B, som er en liten modell. Benchmark-overføring til 70B-modeller er ikke dokumentert ennå.

Hva skiller dette fra GPTQ og AWQ?
Det er et rimelig spørsmål. Vi har hatt post-training quantization (PTQ) siden lenge: GPTQ, AWQ, EXL2, GGUF-formater. Alle komprimerer modellvekter til lavere bit-presisjon. Hva er egentlig nytt her?
Tre ting skiller TurboQuant-tilnærmingen:
Dataoblivious. GPTQ og AWQ krever kalibreringsdatasett – du trener algoritmen på et utvalg tekst slik at den vet hvilke vekter som er viktige. TurboQuant trenger ikke det. Den roterer vektene matematisk og kvantiserer deretter. Ingen kalibreringsdata, ingen treningsprosess, ingen ekstra avhengigheter.
Nær-optimal distorsjonsrate. Paperet bak TurboQuant (Zandieh et al., ICLR 2026) beviser at algoritmen avviker fra informasjonsteoretiske grenser med en faktor på bare ~2,7. Det er ikke bare et markedsføringspåstand – det er matematisk bevist at du er nær grensen for hva som er fysisk mulig å oppnå med kvantisering.
Residualkorrigering. Den 1-bit QJL (Quantized Johnson-Lindenstrauss) transformasjonen som brukes på residualet gir en unbiased estimator for indreprodukt. Det høres akademisk ut, men betyr i praksis at oppmerksomhetsmekanismen i modellen ikke akkumulerer systematisk bias – en kjent feil i enklere kvantiseringsmetoder.
Skal du prøve dette nå?
Det er litt tidlig for produksjonsbruk. Implementasjonen er ny, testet på én liten modell, og community-drevet. Benchmarks på større modeller mangler. Det er ikke det samme som et velforsket GGUF-format som er validert på tusenvis av brukere.
Men det er interessant å følge med på. Retningen er riktig: TurboQuant-matematikken er solid (ICLR 2026-paperet er fagfellevurdert), og å bruke den på vekter i stedet for bare KV-cache er et logisk neste steg. Ser vi liknende resultater på 7B og 13B-modeller som vi ser på 0,8B-modellen, begynner dette å bli noe verdt å integrere i lokale oppsett.
Den opprinnelige TurboQuant-algoritmen er allerede tilgjengelig i llama.cpp for KV-cache (se min forrige artikkel om dette). Vektkomprimering er neste front. Og nå har community-miljøet stukket fingeren i jorda og sagt: vi prøver det.
Kildekode og benchmarks finner du på GitHub (turboquant_plus). Pakken installeres via pip install turboquant og fungerer som drop-in for HuggingFace-modeller. Det er nok til å teste på din egen maskin – men ha forventningene på rett nivå inntil bredere validering foreligger.
Les den komplette guiden: TurboQuant – Alt du trenger å vite om Googles AI-gjennombrudd.







