

Innhold Vis
TurboQuant er nå tilgjengelig som Python-bibliotek – en open source implementasjon av forskningspapiret som komprimerer høydimensjonale vektorer til 1-4 bits per koordinat uten kalibreringsdata. En utvikler brukte to dager på å implementere hele algoritmen, og resultatet er nå tilgjengelig på GitHub og PyPI.
Jeg skrev om TurboQuant-forskningen nylig – den tekniske siden, hva Google oppnår med KV-cache-komprimering, og hvorfor det er imponerende. Men det er forskjell på et akademisk papir og noe du faktisk kan installere og kjøre. Nå er vi der.
Dette er relevant om du jobber med LLM-inferens, vektordatabaser, eller bare er nysgjerrig på hva «near-optimal distortion rate» faktisk betyr i praksis.
Hva er TurboQuant, kort fortalt?
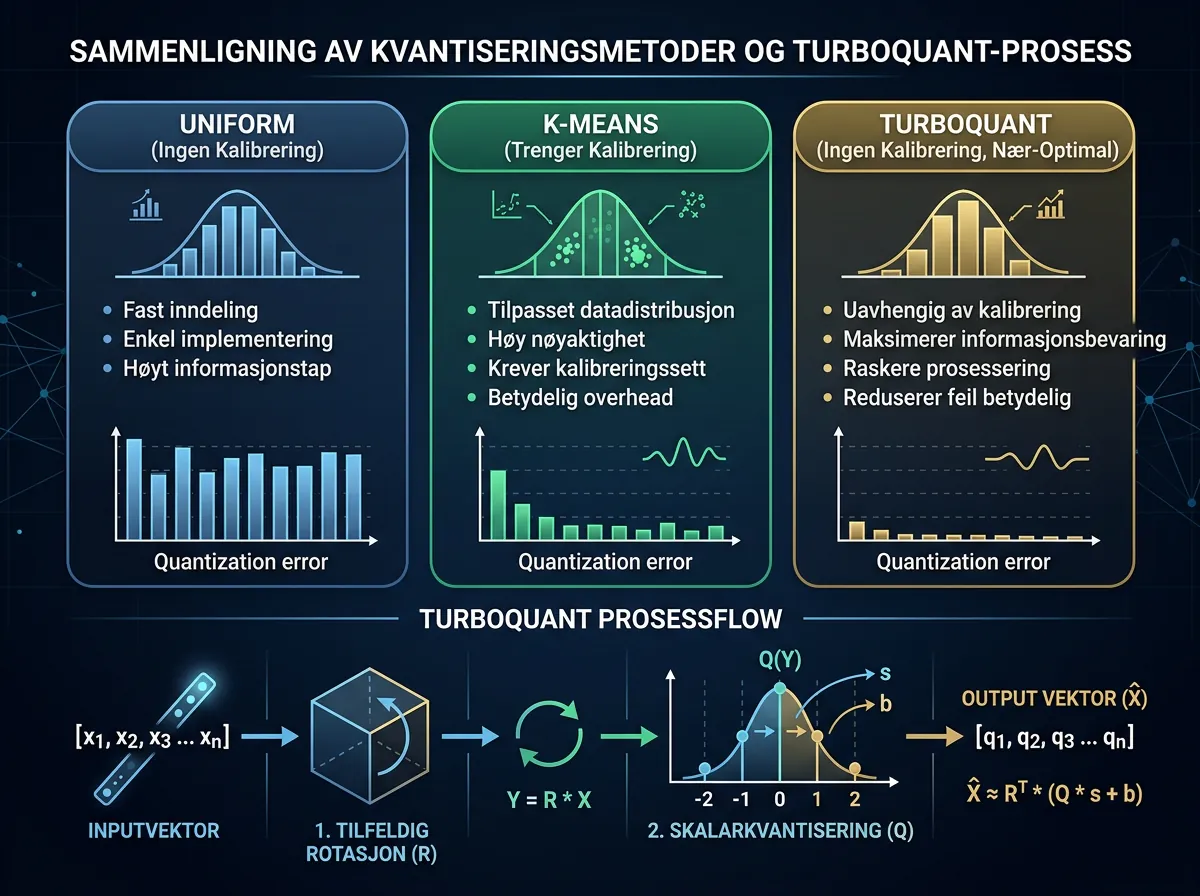
De fleste kvantiseringsmetoder for AI-modeller faller i én av to kategorier: enten trenger de kalibreringsdata (k-means, klipperange-estimering osv.), eller de bruker enkel uniform kvantisering og godtar et kvalitetstap. TurboQuant gjør ingen av delene.
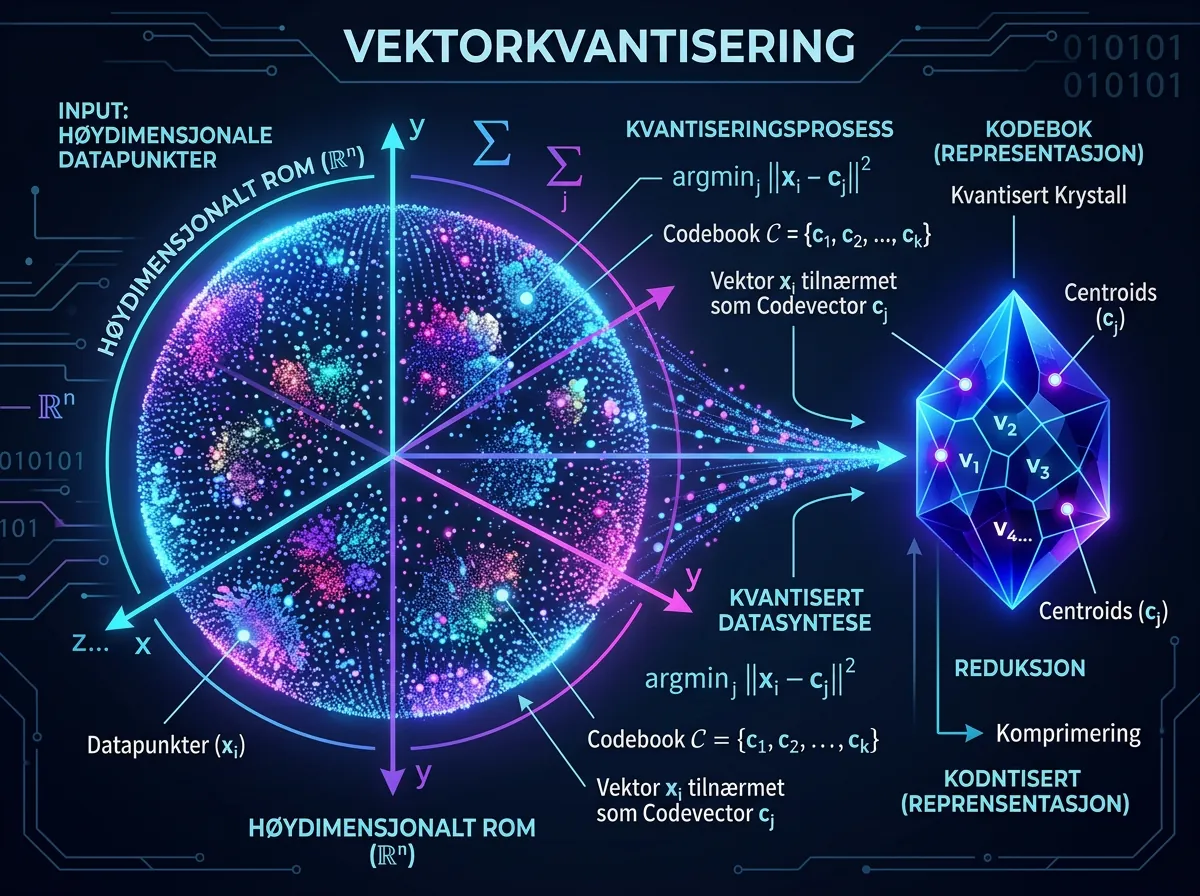
Ideen er elegant: ta en høydimensjonal vektor, roter den med en tilfeldig ortogonal matrise, og kvantiser deretter koordinatene uavhengig. Rotasjonen gjør at koordinatene får en konsentrert Beta-fordeling og oppfører seg nesten uavhengig av hverandre. Deretter kan vanlig skalarkvantisering brukes på hver koordinat – og du ender opp med nær-optimal komprimering uten å ha sett ett eneste datasample.
Algoritmen garanterer distorsjonsrate innenfor ~2,7 ganger Shannons informasjonsteoretiske nedre grense, uavhengig av bitbredde eller dimensjon. Det er et sterkt teoretisk resultat.
Hva gjør Python-implementasjonen?
Repoet er bygget på Python 3.9+, NumPy og SciPy – ingen exotic dependencies. Det støtter 1-4 bits kvantisering per koordinat og to varianter:
- TurboQuant (MSE): Minimerer gjennomsnittlig kvadratisk feil – brukes for KV-cache-lagring der du vil rekonstruere vektoren
- TurboQuantProd: Optimalisert for indre produkt-estimering – brukes for vektordatabasesøk der du vil finne nærmeste nabo
TurboQuantProd bruker en tosjedsanpasset tilnærming: MSE-kvantisering etterfulgt av et 1-bit Quantized Johnson-Lindenstrauss-transform på residualet. Resultatet er ubiased estimering av indre produkter mellom komprimerte vektorer.
En interessant detalj: implementasjonen støtter streaming – den prosesserer vektorer én om gangen. Du trenger ikke hele datasettet i minnet for å kvantisere. Det er praktisk i LLM-kontekst der KV-cache-tokens ankommer sekvensielt.
Kjente begrensninger i denne versjonen
Implementatoren er ærlig om hva som ikke er på plass ennå:
- Ingen GPU-akselerasjon (kun CPU via NumPy)
- Virker ikke for dimensjoner over 4096
- Støtter ikke fraksjonale bitbredder (f.eks. 2,5 bits)
- Forutsetter unit-norm input – vektorer må normaliseres først
For akademisk eksperimentering og forståelse av algoritmen er dette mer enn godt nok. For produksjonskjøring på store LLM-er – der du faktisk trenger GPU-ytelse og 2,5 bits-modus – er det ikke der ennå.
Hva er forskjellen fra det jeg skrev om tidligere?
Artikkelen min om Googles TurboQuant-forskning handlet om hva algoritmen gjør og hvorfor resultatet er imponerende – 6x minnereduksjon, 8x raskere KV-cache-operasjoner på H100, og den teoretiske begrunnelsen bak.
Dette repoet er noe annet: det er selve implementasjonen du kan installere med pip og kjøre lokalt. To forskjellige ting. Forskningen er ett; å ha kode som faktisk gjør beregningene er noe du kan ta på.
Det er ikke uvanlig at slike implementasjoner dukker opp kort tid etter at en interessant paper publiseres. ML-miljøet er kjent for å omsette akademisk forskning til kjørbar kode raskt – og det er et godt tegn på at algoritmen er tilstrekkelig velforklart til at folk kan reimplementere den.
Hvem er dette nyttig for?
Konkret: hvis du kjører egne LLM-er lokalt eller i skyen og sliter med KV-cache-minnebruk, kan dette være verdt å undersøke. KV-cachen vokser lineært med kontekstlengden – for en 70B-modell med lang kontekst kan det raskt bli problematisk. En 4x minnereduksjon (fra float16 til 4-bit) kan være forskjellen mellom at noe kjører på eksisterende hardware eller ikke.
For vektordatabasebruk er argumentet annerledes: du sitter på millioner av vektorer, vil gjøre nearest-neighbor søk raskt, og vil ikke bruke mye indekseringstid. TurboQuantProd krever null treningsdata og er ifølge paperet bedre enn product quantization på recall i benchmark-tester. Det er et sterkt argument.
Hobbyister og studenter som vil forstå vektorkvantisering fra bunnen av: repoet er en fin måte å se algoritmen i faktisk kode, ikke bare matematikk på papir. Selve random-rotation-ideen er enkel nok at du kan lese gjennom implementasjonen på en kveld.
Koden finner du på GitHub, og pakken kan installeres med pip install turboquant-py via PyPI. Det teoretiske grunnlaget er beskrevet i originalpapiret på arXiv.
Les komplett oversikt: TurboQuant – Alt du trenger å vite om Googles AI-gjennombrudd.
Les komplett oversikt: Open source AI – komplett guide (2026).







