

Innhold Vis
llama.cpp slapp 10. mai 2026 versjon b9095 – og for deg som har to Blackwell PCIe-kort er dette oppdateringen du har ventet på. For første gang fungerer -sm tensor på dual consumer Blackwell uten NCCL-biblioteket som tidligere blokkerte hele oppsettet.
Problemet med NCCL (NVIDIAs Collective Communications Library) er at det lenge har vært en forutsetning for tensor-parallell inferens på tvers av to GPU-er. Men NCCL er laget for datacenter-hardware. Consumer Blackwell-kort som RTX 5060 Ti, 5070 og 5080 kjører på PCIe – ikke NVLink – og der har NCCL historisk vært ustabilt eller rett og slett ikke fungert. b9095 bytter ut NCCL med en intern AllReduce-implementasjon som er bygget spesielt for denne situasjonen.
Her er hva endringen betyr i praksis, hvordan du aktiverer det, og hva du bør forvente av ytelse.
Hva er NCCL-Free Tensor Parallelism?
Tensor-parallellisme er måten llama.cpp deler en stor modell mellom to GPU-er. I stedet for å laste halve modellen på hvert kort (row split), kjører tensor-modus beregninger parallelt på begge kortene og synkroniserer etterpå. Det krever konstant kommunikasjon mellom GPU-ene – og det er her AllReduce-operasjonen kommer inn.
Tidligere var llama.cpp avhengig av NCCL for denne kommunikasjonen. NCCL er effektivt, men det er designet for NVLink-tilkoblede datacenter-GPU-er (A100, H100, H200). På Blackwell PCIe-kortene som de fleste av oss faktisk bruker, oppsto det intermittente hengelokker – maskinen ble stående og henge uten feilmelding. Ikke akkurat ideelt.
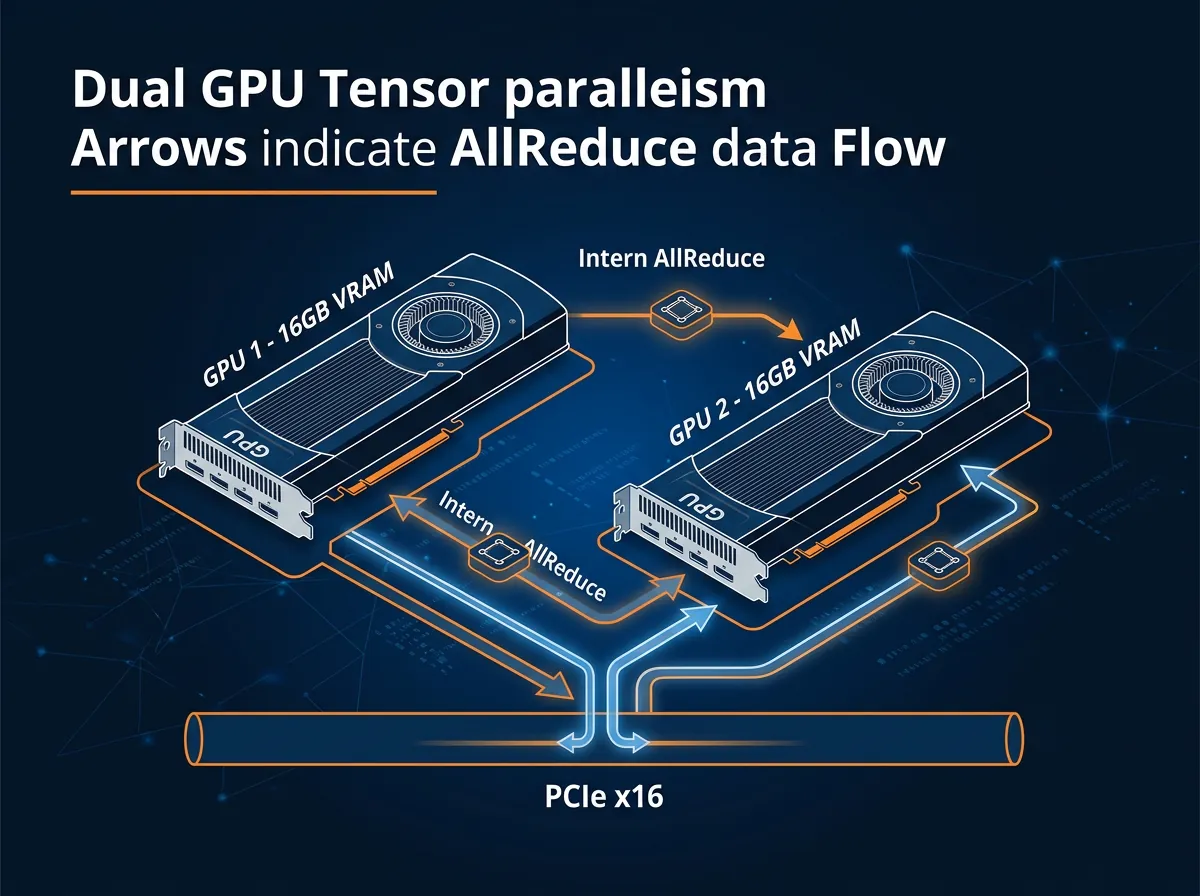
b9095-releasen introduserer en intern CUDA-kernel som håndterer AllReduce-operasjonen direkte, uten NCCL. Kommunikasjonen skjer via pinned memory og volatile flags som begge kortene leser. I tillegg er det lagt til __threadfence_system() som sikrer at data er globalt synlig for peer-GPU-en før flagget settes – det var den manglende bitsen som forårsaket hengelåsene på Blackwell PCIe.
Hva er begrensningene?
Den interne AllReduce-implementasjonen er god, men den har foreløpig noen grenser du bør kjenne til:
- Maks 2 GPU-er: Støtter kun dual-GPU-oppsett per nå. Tre eller flere kort faller tilbake til CPU-reduksjon.
- FP32 og tensorer opp til 256 KB: For større reduksjoner brukes fallback til CPU-modus. I praksis treffer du sjelden dette taket med vanlige GGUF-modeller.
- PCIe, ikke NVLink: Løsningen er eksplisitt bygget for PCIe-kortene. Har du datacenter-hardware med NVLink kan NCCL fortsatt være raskere.
For de aller fleste med dual 5060 Ti, dual 5070 eller dual 5080 PCIe-oppsett er disse begrensningene uproblematiske. Du laster typisk 30B- til 70B-modeller der tensor-splitting er relevant, og innenfor de grensene holder implementasjonen seg.
Hvordan aktiverer du det?
Kommandoen er den samme som før, men nå faktisk fungerer:
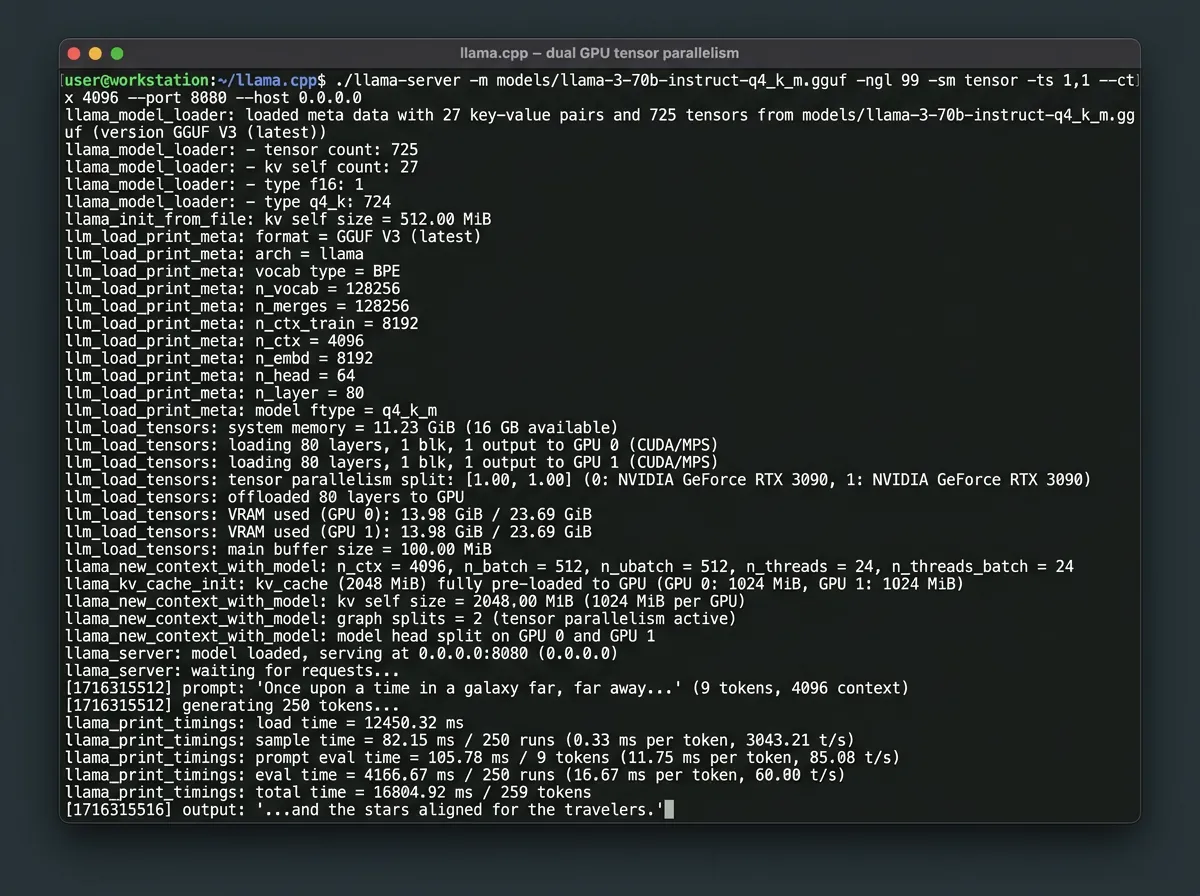
llama-server -m /sti/til/modell.gguf -ngl 99 -sm tensor -ts 1,1Flagget -sm tensor aktiverer tensor-splittmodus. -ts 1,1 fordeler last likt mellom de to kortene. -ngl 99 sender alle lag til GPU.
Du kan også styre AllReduce-provider eksplisitt via miljøvariabelen:
GGML_CUDA_ALLREDUCE=internal llama-server -m modell.gguf -ngl 99 -sm tensor -ts 1,1Verdiene er internal (ny implementasjon) og nccl (gammelt system). For Blackwell PCIe er internal default og det du vil ha. Det er også lagt til en watchdog-mekanisme via GGML_CUDA_AR_WATCHDOG – et sikkerhetsnett som fanger hengelåser og rapporterer dem i stedet for å henge i det uendelige.
Hvilke modeller drar nytte av dette?
To 5060 Ti-kort gir deg totalt 32 GB VRAM. Det er nok til å kjøre store modeller du ikke kunne kjøre på ett kort alene:
- Llama 3 70B Q4_K_M: Passer komfortabelt på 32 GB med tensor-split
- Qwen 3 30B A3B (MoE): Effektiv utnyttelse av begge kortene
- Mistral 22B: Kjapp og god kvalitet innenfor rammen
- DeepSeek-R1 32B: Populær reasoning-modell som profiterer på dual VRAM
Tensor-parallellisme gir generelt raskere tokens per sekund enn row split for disse modellstørrelsene, fordi beregningene kjøres simultant i stedet for sekvensielt mellom kortene. Som referanse: en konfigurasjon med dual 5060 Ti og Qwen3.6 27B rapporterte rundt 60 tokens per sekund med tensor-modus aktivert – det er brukbart tempo for en modell av den størrelsen.
Hvordan oppdaterer du llama.cpp?
Hvis du kjører en forhåndsbygget versjon, last ned b9095 fra GitHub Releases. Finn pakken for CUDA + Windows eller Linux avhengig av oppsettet ditt.
Bygger du fra source:
git pull
cmake -B build -DGGML_CUDA=ON
cmake --build build --config Release -j $(nproc)Ingen nye avhengigheter – den interne AllReduce er ren CUDA, ingen ekstra biblioteker å installere.
Er dette starten på bedre dual-GPU-støtte i llama.cpp?
Det ser slik ut. Tensor-parallellisme uten NCCL er en arkitektonisk endring som gjør hele multi-GPU-staken mer robust for consumer-hardware. Foreløpig er det begrenset til 2 GPU-er og FP32, men kodebasen er lagt opp til å utvide dette. Neste naturlige steg er støtte for 4 GPU-er og BF16/FP16-reduksjoner – begge deler vil gjøre løsningen enda mer praktisk.
Jan Sverre er spent på å se hva folk rapporterer tilbake med dual 5060 Ti-oppsett spesielt. Det er et rimelig konfigurasjonsalternativ: to kort til rundt 4-5 000 kroner stykket gir deg 32 GB VRAM og nå også fungerende tensor-parallellisme. Sammenlignet med en enkelt RTX 5090 (14 000+ kr) med 32 GB VRAM er det et interessant valg – du betaler kanskje litt mer totalt, men du beholder fleksibiliteten til å bruke kortene til andre ting også.
Hvis du har kjørt inn i hengelåsproblemer med -sm tensor på Blackwell PCIe tidligere, er b9095 verdt en ny runde. Og hvis du vurderer et dual GPU-oppsett for lokal inferens, er dette oppdateringen som gjør det til et reelt alternativ – ikke bare et teoretisk one. Relatert lesning: Intel Arc Pro B70 til lokal LLM er en god referanse for hva god software-støtte faktisk betyr i praksis, og open source AI-guiden gir bredere kontekst for lokal kjøring av modeller. Ollama-guiden er fortsatt relevant hvis du heller vil ha et enklere oppsett uten manuell llama.cpp-konfigurasjon. For deg som ser på PCIe-båndbredde som flaskehals mellom kortene, er torch-nvenc-compress-artikkelen interessant lesning.







