
Innhold Vis
DeepSeek slapp det fullstendige V4-papiret denne uken. Forhåndsvisningen fra april var 58 sider – det nye dokumentet er vesentlig tykkere og inneholder tekniske detaljer som mangler i de fleste oppsummeringer. Det er noen triks her som fortjener en nærmere titt, særlig rundt FP4-kvantisering og stabilitetsmekanismene.
Kinesisk AI-forskning fortsetter å overraske. Ikke bare med hva de bygger, men med hvordan de bygger det. DeepSeek V4 er ikke bare en ny stor modell – det er et system som er konstruert fra bunnen av for å gjøre én million tokens kontekst mulig uten at serverne tar fyr.
Jeg har gått gjennom det tekniske innholdet. Her er hva som faktisk er interessant.
Hva er DeepSeek V4 egentlig?
DeepSeek V4 er en familie av to Mixture-of-Experts-modeller designet for effektiv behandling av svært lange kontekster. Begge støtter én million tokens nativt – det vil si uten noen form for triks eller RAG-opplegg for å simulere lang kontekst.
Modellvariantene ser slik ut:
- V4-Pro: 1,6 billioner totale parametere, 49 milliarder aktiverte per token, 61 lag
- V4-Flash: 284 milliarder totale parametere, 13 milliarder aktiverte per token, 43 lag
Det viktige her er skillet mellom totale og aktiverte parametere. MoE-arkitekturen betyr at modellen bare bruker en liten del av sine totale parametere per token – resten sover. Det er slik de kan ha 1,6 billioner parametere og fortsatt kjøre inference uten å sprenge budsjettet.
Jeg har skrevet mer utfyllende om V4-arkitekturen og bakgrunnen i DeepSeek V4-lanseringen og preview-artikkelen fra april. Det fullstendige papiret legger til mye teknisk dybde.
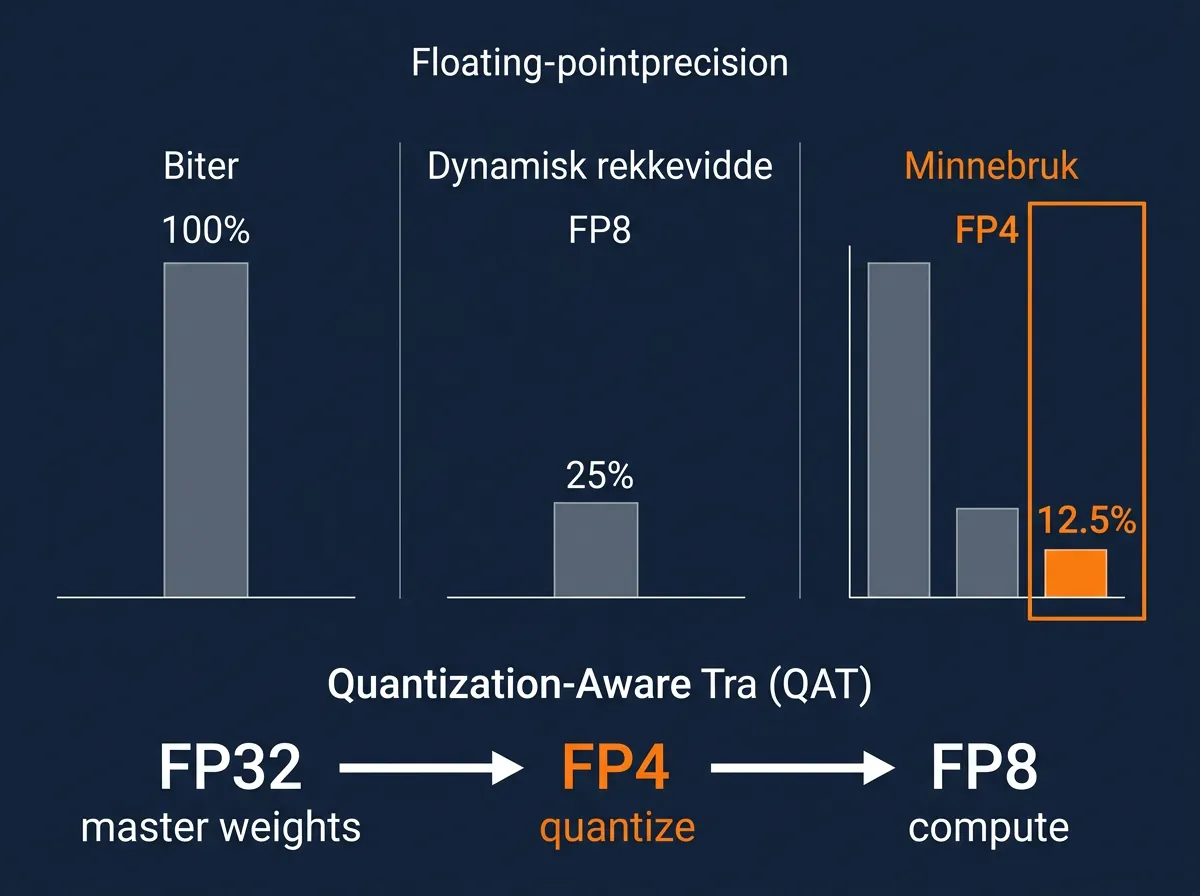
Hva er FP4 QAT, og hvorfor er det interessant?
FP4 QAT betyr Quantization-Aware Training med 4-bit floating point presisjon. I stedet for å kvantisere modellen etter trening (som er vanlig), bygger DeepSeek kvantiseringen direkte inn i treningsprosessen.
Hvorfor gjør de dette? Minne. MoE expert-vektene er den desidert største GPU-minneforbrukeren. Ved å kvantisere disse til FP4 under selve treningen – ikke bare i inference – slipper de å håndtere konverteringsfeil i ettertid. Vektene er allerede FP4-native når de brukes i produksjon.
Teknisk sett ser flyten slik ut: FP32 master-vekter (som optimizer-en bruker) kvantiseres til FP4, deretter dequantiseres losslessly til FP8 for selve beregningene. FP8 (E4M3) har to ekstra eksponent-bits sammenlignet med FP4 (E2M1), noe som gir større dynamisk rekkevidde – så konverteringen bevarer presisjon.
FP4 brukes på to steder:
- MoE expert-vekter (den store minnesluker-en)
- QK-stien i Lightning Indexer-en i CSA (mer om dette straks)
Resultatet på QK-indexer-en er 2x speedup med 99,7% recall bevart. Det er et solid kompromiss.
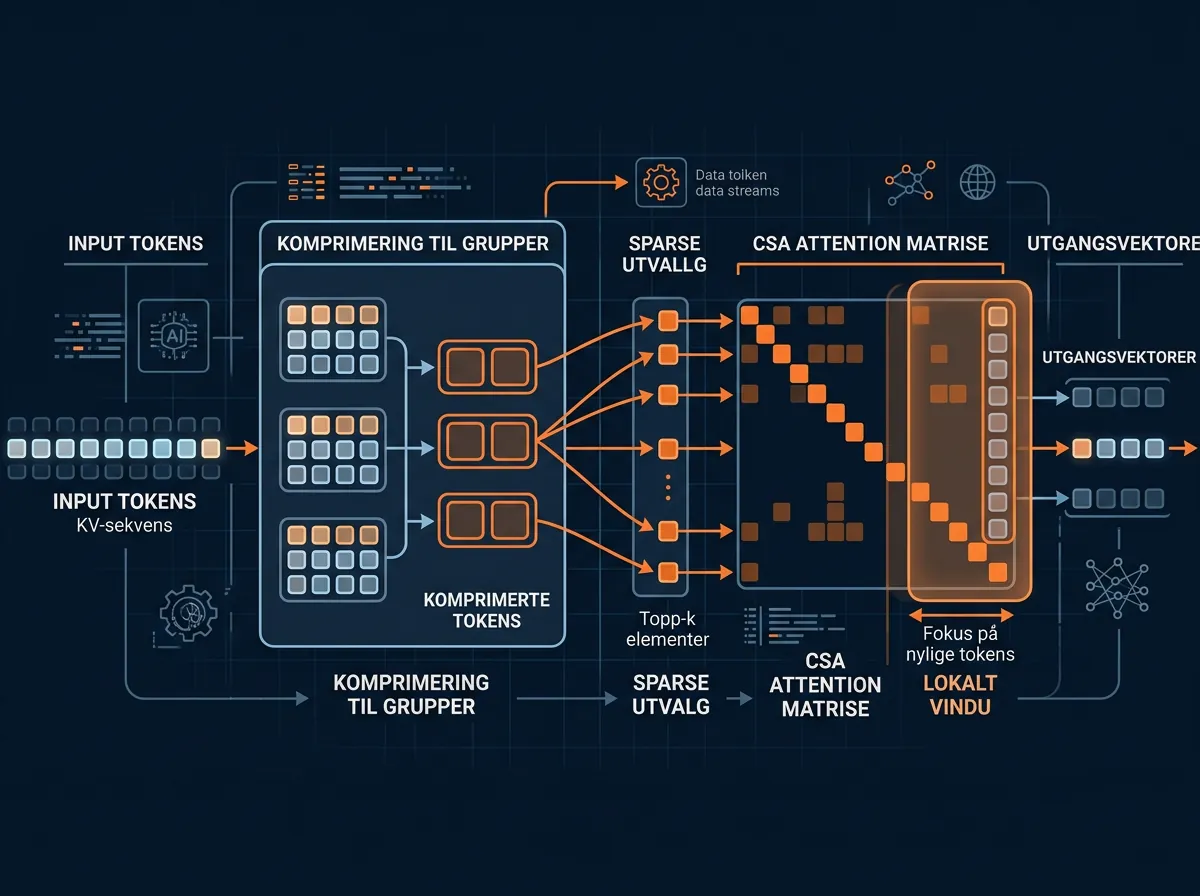
Hva er CSA og HCA – den egentlige innovasjonen?
Her er det fullstendige papiret skiller seg markant fra forhåndsvisningen. Attention-mekanismen er gjennomtenkt på en måte som gjør én million tokens faktisk gjennomførbar.
Problemet med standard attention er at kompleksiteten skalerer kvadratisk med sekvensens lengde. En million tokens med vanlig attention er uaktuelt – det ville krevd astronomisk mye minne og beregning.
CSA (Compressed Sparse Attention) angriper dette på to måter. Først komprimeres tokens i grupper av fire til én enkelt entry via en lært token-kompressor. Deretter velger hvert spørsmål-token ut bare de topp-k mest relevante komprimerte KV-entries for full attention-beregning. Et separat «sliding window»-branch dekker de siste 128 ukomprimerte tokenene for lokal kontekst.
HCA (Heavily Compressed Attention) er enda mer aggressiv – kompresjonsfaktor på 128 tokens til én entry – men bruker tett attention over hele den komprimerte sekvensen i stedet for sparse selection.
Kombinasjonen gir et system der modellen kan «skumme» over én million tokens effektivt via høy kompresjon, men beholde lokal presisjon via sliding window og selektiv attention.
«Learnable attention sinks» er et fint lite triks i tillegg: attention-skårer trenger ikke summere til 1, noe som reduserer bortkastet beregning på irrelevante tokens.
Hvor mye mer effektivt er dette egentlig?
Effektivitetstabellen i det fullstendige papiret er ganske slående. Sammenlignet med DeepSeek V3.2 ved én million tokens kontekst:
- V4-Pro: 27% av per-token compute, 10% av KV cache-størrelse
- V4-Flash: 10% av per-token compute, 7% av KV cache-størrelse
Sagt annerledes: V4-Pro gjør den samme jobben med under en tredjedel av beregningen, og bruker en tidel av KV-cache-minnet. Det er ikke marginale forbedringer – det er en fundamentalt annen størrelsesorden.
Det er dette som gjør én million tokens kontekst realiserbar kommersielt. Ikke bare mulig i lab-setting, men mulig å kjøre med akseptable kostnader.
Stabilitetstrikk for trening i stor skala
Noe av det jeg fant mest interessant i det fullstendige papiret er avsnittet om treningsstabilitet. Å trene modeller i denne størrelsen er kjent for å være ustabilt – gradienter eksploderer eller forsvinner, treningen divergerer.
DeepSeek presenterer to konkrete løsninger:
Anticipatory Routing kobler fra backbone-nettverket og routing-nettverket under oppdateringer. I stedet for at de påvirker hverandre simultant, antesiperer routing-nettverket neste tilstand av backbone. Det reduserer oscillasjon i ekspertvalg.
SwiGLU Clamping begrenser SwiGLU-komponentene til definerte verdiintervaller. SwiGLU er aktiveringsfunksjonen i FFN-lagene – uten clamping kan ekstremt store verdier føre til numerisk ustabilitet i dype nettverk.
I tillegg brukes mHC (Manifold-Constrained Hyper-Connections) i stedet for vanlige residuale forbindelser. Residual stream utvides med faktor 4, og Sinkhorn-Knopp-algoritmen holder blandingsmatriser numerisk stabile. Det erstatter altså den vanlige «legg til og normaliser»-mekanismen med noe mer avansert.
Muon Optimizer – et annerledes valg
For de fleste parametere erstatter V4 AdamW-optimizeren med Muon. AdamW er industristandard for LLM-trening, så dette er et bevisst avvik.
Muon bruker Newton-Schulz-iterasjoner for å ortonormalisere gradientoppdateringer i stedet for element-vis optimering. Intuisjonen er at vektmatrisene bør oppdateres på en måte som bevarer de geometriske egenskapene til parametrene – ikke bare skyve hvert element uavhengig.
Det er en mer sofistikert tilnærming, og det er interessant at DeepSeek har valgt dette fremfor den innarbeidede standarden.
Post-training: spesialister og destillasjon
V4 bruker ikke tradisjonell blandet RL-trening i post-training-fasen. I stedet trenes uavhengige domeneekspertmodeller i matematikk, koding, agentoppgaver og instruksjonsfølging. Disse slås deretter sammen via On-Policy Distillation fra ti lærermodeller.
Resultatet er en modell som ifølge Hugging Face-siden oppnår 3206 Codeforces-rating, 57,9% på SimpleQA Verified Pass@1 og 80,6% på SWE-Verified resolved. På lange kontekst-benchmarks scorer den 83,5 MMR på OpenAI MRCR 1M.
Hva betyr det fullstendige papiret?
58-siders forhåndsvisningen var nok til å gi et bilde av hva DeepSeek V4 er. Det fullstendige papiret gir deg verktøyene til å faktisk forstå hvorfor det fungerer – og det er her det blir verdifullt for alle som jobber med storskala AI-systemer.
FP4 QAT direkte i treningsprosessen er et konkret eksempel på at kinesisk AI-forskning ikke bare kopierer vestlige tilnærminger, men faktisk eksperimenterer med grunnleggende designvalg. Det er vanskelig å si om dette vil bli standard i bransjen, men det er et signal om at presisjon og effektivitet nå behandles som treningsparametre – ikke bare inference-bekymringer.
Kombinasjonen av CSA, HCA og FP4 QAT ser ut til å være det som faktisk gjør én million tokens kontekst til noe annet enn et markedsføringsnummer. Tallene i papiret er i hvert fall overbevisende.
Papiret er tilgjengelig via Hugging Face for de som vil lese det selv. Anbefalt for alle som er interessert i hva som faktisk skjer under panseret på store language models.







