
Innhold Vis
HiDream-O1-Image er en ny open source bildegenererings-modell som gjør noe de fleste andre modeller ikke gjør: den hopper over VAE-trinnet helt. I stedet opererer den direkte på råpiksler – tekst, bilde og oppgaveinstruksjoner kodes i ett felles tokenrom. Modellen har 8 milliarder parametere og er sluppet under MIT-lisens.
Det høres kanskje teknisk ut, og det er det. Men konsekvensen er interessant: én enkelt modell som håndterer text-to-image, bilderedigering og personalisering uten å sy sammen flere separate komponenter. Ingen ekstern VAE, ingen disjunkt tekstencoder – bare én Pixel-level Unified Transformer (UiT) som gjør hele jobben.
Her er hva vi vet om modellen, hva benchmarkene sier, og hva som faktisk skiller den fra det vi har sett tidligere.
Hva er egentlig problemet med VAE i bildegenerering?
De fleste diffusjonsmodeller – FLUX, Stable Diffusion, og andre – jobber ikke direkte med piksler. De komprimerer bildet først til et latent rom via en Variational Autoencoder (VAE), genererer i det komprimerte rommet, og dekoder tilbake til piksler etterpå. Det er effektivt, men det introduserer et ledd til. Kvaliteten på den endelige dekompresjonen er avhengig av VAE-arkitekturen, og du har i praksis to separate systemer som må fungere godt sammen.
Jeg har sett dette i praksis – FLUX.2 small decoder var nettopp et forsøk på å optimalisere VAE-delen av FLUX-familien, fordi det er et reelt flaskehals-punkt. HiDream-O1-Image tar en annen vei: kutt VAE-trinnet, og la modellen lære seg hele prosessen end-to-end fra råpiksler.
Det er ikke en ny idé i teorien, men 8 milliarder parametere med MIT-lisens og resultater som faktisk ser lovende ut – det er nytt.
Hva klarer HiDream-O1-Image?
Modellen støtter tre hovedbruksområder:
- Text-to-image: Standard bildegenerering fra tekstprompt, opp til 2048 × 2048 piksler nativt
- Instruksjonsbasert redigering: «Fjern øreproppene» – altså direkte naturlig-språklige redigeringsinstruksjoner
- Multi-referanse personalisering: Gi flere referansebilder av et objekt eller person, generer nye bilder med det samme subjektet i nye settinger
Det er den siste funksjonen som stikker seg ut. FLUX 2 er sterk på generering, men subjekt-konsistens på tvers av mange bilder er et eget problem som krever enten finetuning eller kompliserte rigs. Her prøver HiDream å løse det i én enkelt modell.
Det finnes to varianter å laste ned:
- HiDream-O1-Image: Full modell, 50 inferenssteg
- HiDream-O1-Image-Dev: Destillert variant, 28 inferenssteg og raskere
I tillegg finnes det en HiDream-O1-Image-Pro med over 200 milliarder parametere – men den er ikke tilgjengelig for nedlasting ennå.
Hva viser benchmarkene?
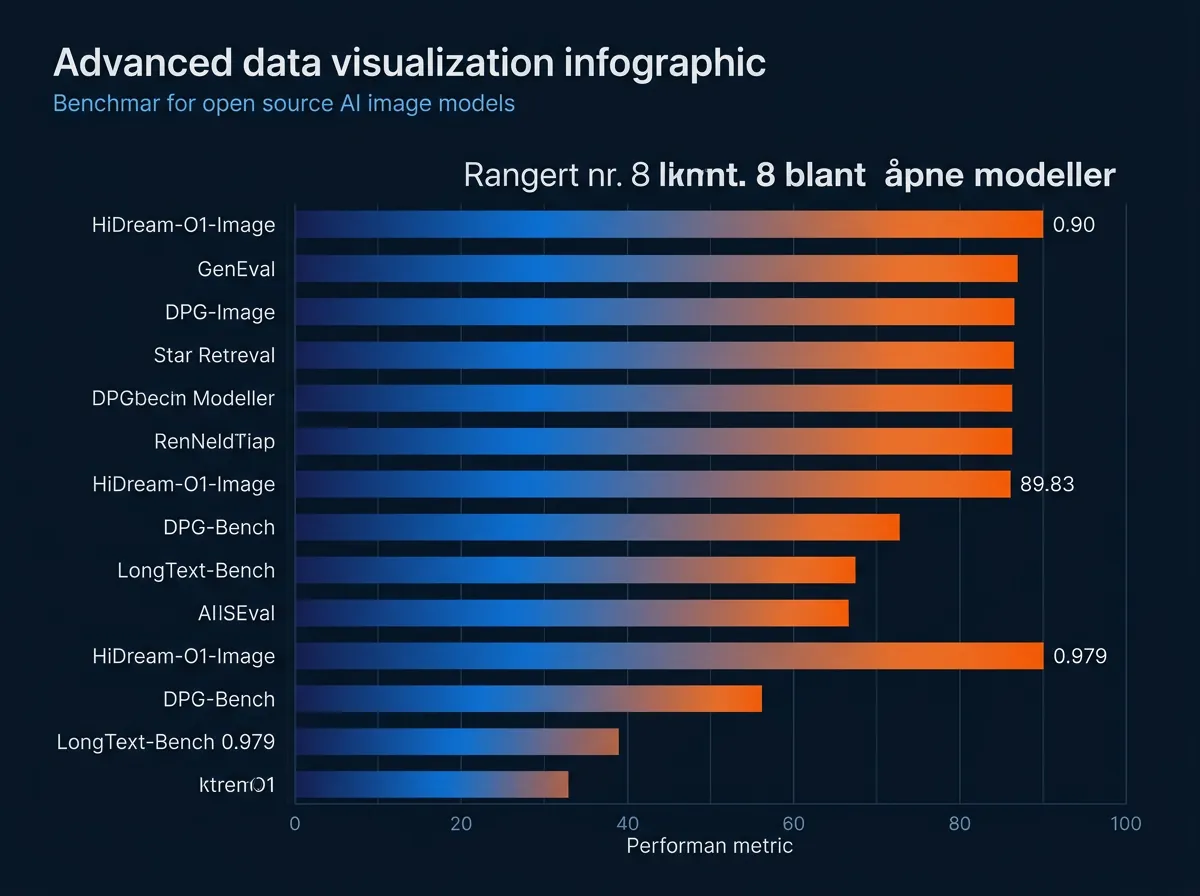
Ifølge den tekniske rapporten på HuggingFace scorer 8B-varianten slik:
- GenEval: 0,90 – et standard mål på prompt-følging
- DPG-Bench: 89,83 – detaljert prompt-forståelse
- HPSv3: 10,37 – menneskelig preferansescore
- CVTG-2K: 0,9128 – kompleks tekstgenerering i bilder
- LongText-Bench: 0,979 (EN) / 0,978 (ZH) – lang tekst i bilder
Den er rangert som nummer 8 blant open weights-modeller på Artificial Analysis Text-to-Image Arena per nå. Det er ikke førsteplassen, men for en 8B-modell uten VAE er det sterke tall.
Benchmarks er alltid krydder, ikke fasit. Men tallene antyder at pixel-space-tilnærmingen ikke koster noe vesentlig på resultatkvalitet sammenlignet med latent-space-modeller på samme parameterskala.
Reasoning-driven prompt agent – hva er det?
HiDream-O1-Image har en innebygd «tenking»-agent som prosesserer prompten din før generering. Den rewriter instruksjonen til en selvbundet engelsk prompt – nyttig særlig for vage eller flerspråklige input.
Du kan kjøre denne agenten lokalt via Gemma-4-31B-it, eller koble den til en OpenAI-kompatibel API (de nevner DeepSeek som eksempel i dokumentasjonen). Det er valgfritt, men det er en smart måte å bygge prompt-robusthet inn i modellen selv i stedet for å overlate det til brukeren.
Dette minner litt om tilnærmingen jeg beskrev i artikkelen om ComfyUI – at mye av verdien i bildegenerering handler om lagene rundt selve diffusjonsmodellen. HiDream prøver å pakke noe av det inn i modellen selv.
Hva krever den for å kjøre?
Modellen trenger en CUDA-kapabel GPU. Ingen spesifikk VRAM-grense er oppgitt i dokumentasjonen, men med 8 milliarder parametere er det realistisk å anta at du trenger et godt stykke over 16GB VRAM for full presisjon. Flash-attention er anbefalt for ytelse.
Til sammenligning: SenseNova-U1, som også dropper VAE og diffusion, er en vesentlig større og tyngre modell. HiDream-O1-Image virker å være et mer tilgjengelig inngangspunkt for den som vil eksperimentere med pixel-space-tilnærmingen.
Oppsettet er standard:
- Klon repo fra GitHub
- Installer avhengigheter via requirements.txt
- Kjør inference.py med ønsket prompt og parametere
- Det finnes også en Gradio-app for nettleserbasert testing (app.py på port 7860)
MIT-lisens betyr full kommersiell bruk – ingen restriksjoner på det.
Hva er det egentlig verdt?
Pixel-space-generering uten VAE er et arkitekturvalg som går mot strømmen. Resten av feltet har investert tungt i latent-space-tilnærmingen. HiDream argumenterer implisitt for at end-to-end opplæring på råpiksler kan gi bedre kontroll og enklere arkitektur på sikt – uten å betale en stor kvalitetskostnad.
Det ser lovende ut basert på tallene. Men «ser lovende ut» er ikke det samme som «fungerer godt i praksis for det du holder på med». Jeg er nysgjerrig på hvordan den håndterer edge cases – vanskelige prompts, spesifikke stiler, konsistens over mange bilder – og det krever faktisk testing, ikke bare benchmarks.
For den som allerede leker med bildegenererings-API-er og ønsker å utforske en modell som gjør ting litt annerledes, er dette verdt et blikk. MIT-lisens og HuggingFace-tilgjengelighet senker terskelen betraktelig.








1 kommentar