

Innhold Vis
Ovis2.6-80B-A3B er en ny multimodal AI-modell fra AIDC-AI som gjør noe ganske smart: den pakker 80 milliarder parametere inn i en Mixture-of-Experts-arkitektur, men bruker bare rundt 3 milliarder under inferens. Det betyr at du får ytelsen til en stor modell til en brøkdel av kostnaden.
Modellen er en direkte oppfølger til Ovis2.5 og bringer tre store forbedringer: bedre håndtering av lange kontekster og høyoppløsningsbilder, aktiv visuell resonnering der modellen selv kan analysere og beskjære bilderegioner underveis, og vesentlig bedre forståelse av informasjonstette dokumenter. Apache 2.0-lisens, som betyr fri kommersiell bruk.
Jeg synes dette er et interessant eksempel på retningen åpen multimodal AI tar i 2026 – ikke bare større modeller, men smartere bruk av parametere. Her er det som er verdt å vite.
Hva er Mixture-of-Experts, og hvorfor gjør det Ovis2.6 interessant?
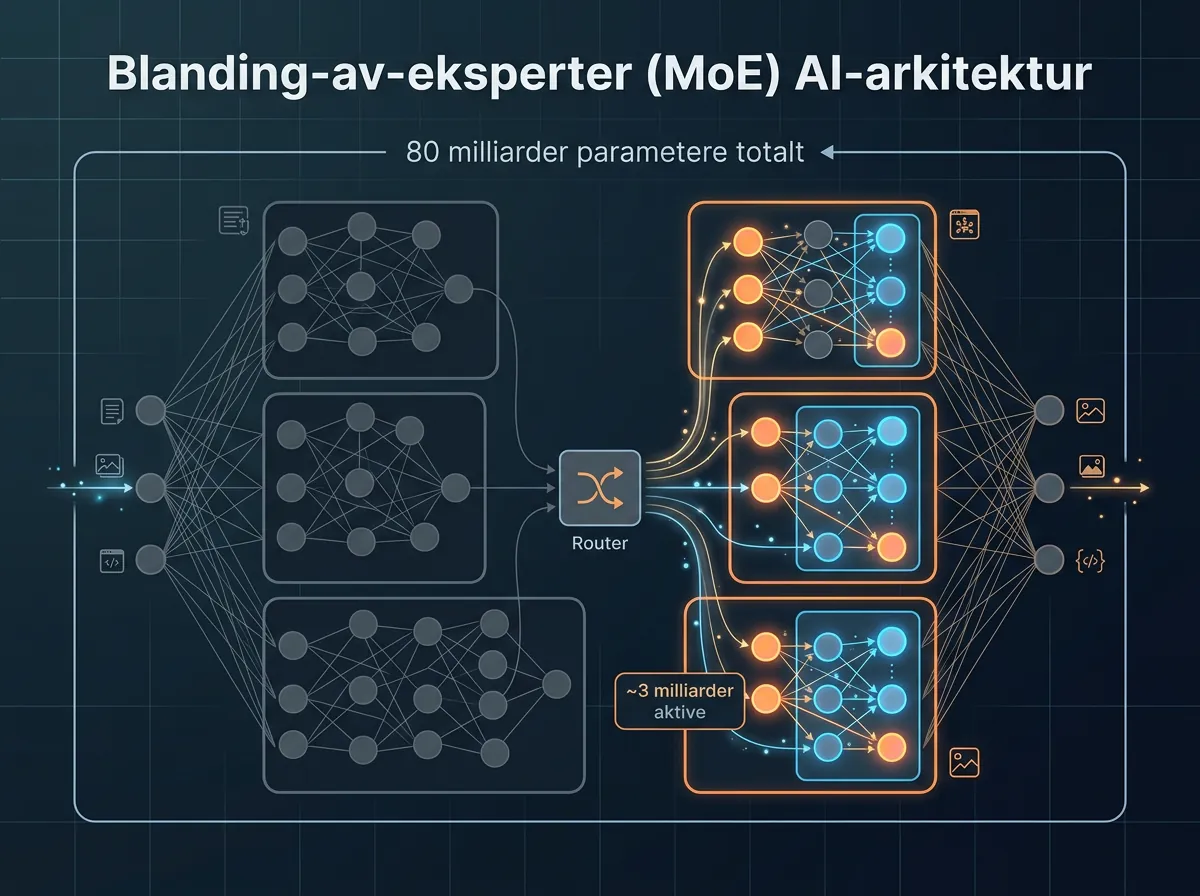
MoE (Mixture-of-Experts) er en arkitektur der modellen aktiverer bare en liten del av parameterne sine for hvert enkelt kall. Ovis2.6-80B-A3B har 80 milliarder parametere totalt, men kun rundt 3 milliarder er aktive per inferens. Resultatet er drastisk lavere serverkostnad uten at du mister evnene til en stor modell.
Sammenlignet med en tett 80B-modell – som ville kreve enorme mengder GPU-minne og tid – er dette en langt mer praktisk tilnærming for de fleste. Det er samme tankegangen som gjør modeller som Mixtral og DeepSeek effektive. For den som vil kjøre dette lokalt eller via API handler det om veldig mye mer for pengene.
Det er også verdt å merke seg at MoE-arkitekturen her er kombinert med et 64K tokens kontekstvindu og støtte for bilder opptil 2880×2880 piksler. Det er sjeldent å se begge deler samtidig i en åpen modell.
Hva er «Think with Image»?
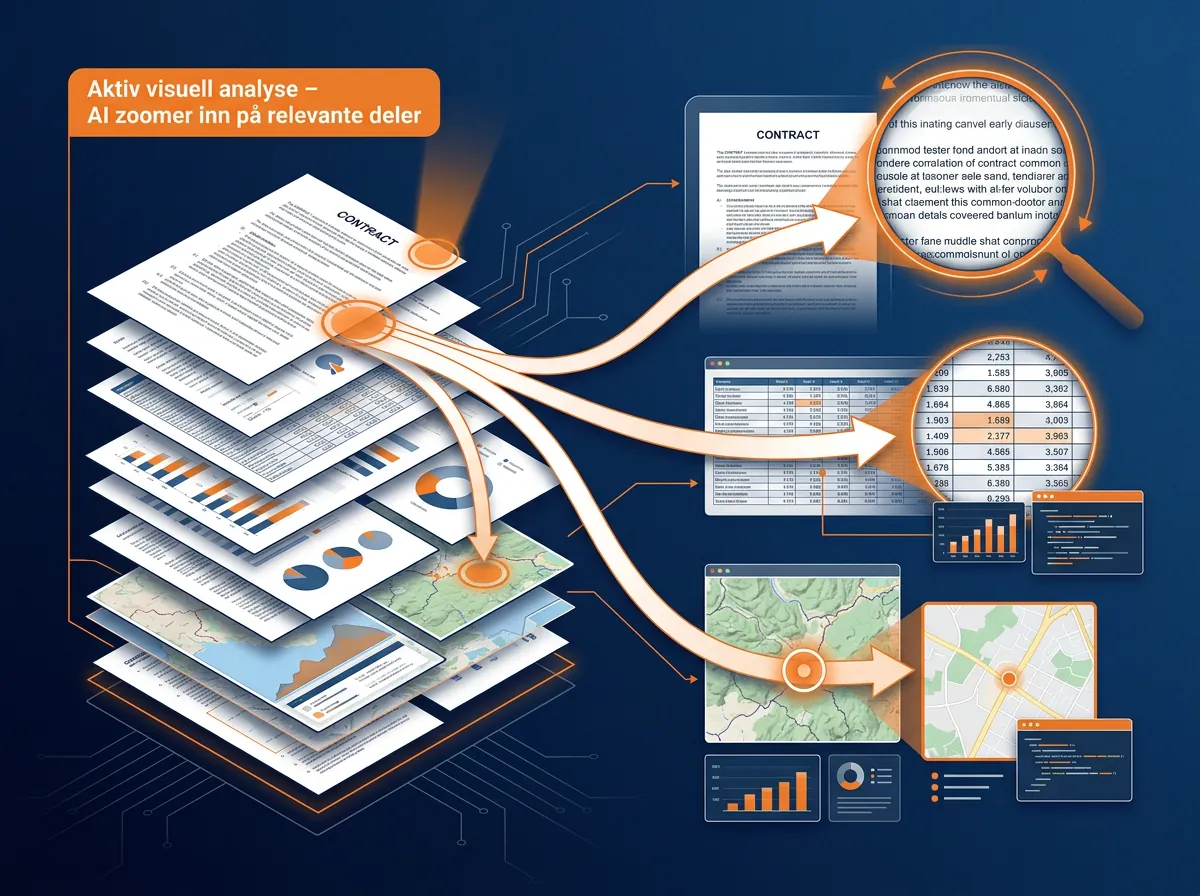
En av de mer spennende nyhetene i Ovis2.6 er det de kaller «Think with Image» – aktiv visuell analyse under resonnering. Konkret betyr det at modellen kan beskjære og rotere bilderegioner mens den tenker seg frem til et svar. Den bruker ikke bare bildet som et statisk inndata, men interagerer med det underveis.
I praksis er dette nyttig for oppgaver der svaret avhenger av å se nøye på en spesifikk del av bildet – et diagram der en liten detalj er avgjørende, en kontrakt der en klausul er delvis skjult, eller et kart der et stedsnavn krever zoom. Modellen kan altså «se nærmere» på det den trenger, ikke bare behandle hele bildet som én blob.
For dokumentanalyse, OCR og teknisk bildegjennomsyn er dette en praktisk fordel. Det minner litt om måten mennesker faktisk leser – vi skanner, så zoomer vi inn på det som virker viktig.
Hva er Ovis2.6 god til i praksis?
Modellen presterer spesielt godt på fire kategorier basert på det tekniske grunnlaget:
- Dokumentforståelse – Flersidede PDF-er, tabeller, kontrakter og rapporter der innholdet er tett og strukturert
- OCR og tekstekstraksjon – Hente ut tekst fra bilder, skjemaer og skannede dokumenter med høy nøyaktighet
- Diagram- og kartanalyse – Tolke visuelle fremstillinger av data, prosessdiagrammer og geografiske kart
- Visuell resonnering – Spørsmål som krever at modellen «tenker gjennom» det visuelle innholdet, ikke bare gjenkjenner det
Modellen støtter også multi-bilde-inferens og videoanalyse (via frame-sampling), noe som gjør den mer fleksibel enn modeller begrenset til ett bilde om gangen. 64K tokens kontekstvindu betyr at du kan mate inn store dokumenter uten å måtte klippe og lime.
Er du interessert i andre åpne modeller som gjør mye for lite, kan det være verdt å lese om Mistral Small 4 – en modell som gjør jobben til tre. MoE-tilnærmingen er den samme tanken, bare i et annet format.
Tekniske spesifikasjoner
For den som vil vite nøyaktig hva de har med å gjøre:
- Totale parametere: 81 milliarder
- Aktive parametere under inferens: ~3 milliarder
- Kontekstvindu: 64K tokens
- Maksimal bildeoppløsning: 2880×2880 piksler
- Presisjon: BF16 (bfloat16)
- Lisens: Apache 2.0
- Modellformat: Safetensors
Apache 2.0-lisensen betyr at du kan bruke dette kommersielt, modifisere det og distribuere det videre uten å betale noe. Det er den typen lisens som faktisk gjør åpen kildekode brukbar i praksis – ikke de halv-åpne variantene som forbeholder seg retten til å trekke tilbake tilgangen.
Kan du kjøre Ovis2.6-80B lokalt?
Ærlig svar: med mindre du har veldig seriøs hardware, er dette ikke noe du kjører på en vanlig gaming-PC. 80 milliarder parametere i BF16 er rundt 160 GB bare for vektene. Selv med aggressiv kvantisering ned til 4-bit snakker vi fortsatt om 40+ GB VRAM.
Det mer praktiske alternativet er API-tilgang via plattformer som OpenRouter, eller å bruke en av de mindre Ovis-modellene. AIDC-AI tilbyr hele serien fra 1B til 80B, og de mindre variantene (7B, 14B) er langt mer tilgjengelige for lokal kjøring. Vil du ha en oversikt over hva som faktisk er mulig å kjøre lokalt, er guiden min om lokale AI-modeller et greit utgangspunkt.
For de som vil prøve via kode er installasjonskommandoene publisert på Hugging Face-siden til modellen. Transformers-biblioteket støtter den, og det finnes eksempelkode for alt fra enkeltbilde-inferens til videoanalyse.
Hvordan er Ovis-serien sammenlignet med andre åpne multimodale modeller?
Det er mange aktører i dette feltet om dagen. InternVL, Qwen-VL, LLaVA-serien og nå Ovis – alle kjemper om å være den beste åpne multimodale modellen. Det som skiller Ovis2.6 er kombinasjonen av MoE-effektivitet og det aktive visuelle resonneringssteget. De fleste konkurrenter behandler bildet som passivt inndata, mens «Think with Image» gir modellen mulighet til å interagere med bildet dynamisk.
GLM-4V fra Zhipu er en annen modell i denne kategorien det er verdt å kjenne til – GLM-5 dekket jeg her med fokus på den enormt store tekstmodellen, men den visuelle kapasiteten er også solid. Det finnes faktisk ganske mange interessante åpne alternativer til de proprietære.
Jeg er litt skeptisk til kinesiske modeller generelt, men det betyr ikke at jeg overser de tekniske kvalitetene. Ovis2.6 ser genuint interessant ut på papiret, særlig for dokumentarbeidsflyter der du ikke vil betale per kall til GPT-4o Vision. Apache 2.0 er uansett en tillitserklæring – den åpne lisensen gir deg kontroll over hva du bruker og hvordan.
Er du nysgjerrig på hva åpne LLM-er generelt kan brukes til i en norsk kontekst, har jeg en oversikt over topp 3 open source LLM-modeller for artikkelskriving som gir et godt bilde av tilstanden i åpen AI.
Kortversjon: Ovis2.6-80B-A3B er et solid teknisk løft i multimodal åpen AI, spesielt for dokumenttunge arbeidsflyter. Hva tenker du – er dette noe du ville testet for OCR eller dokumentanalyse?







