

Innhold Vis
En utvikler uten lab og uten tilskudd lot en liten AI-modell lære seg å kode ved å trene på sine egne feil. Resultatet: 80 % på HumanEval – og bedre matematikkresultater enn GPT-3.5. Alt kjørt på en 24 GB MacBook og et par RunPod-credits.
Utgangspunktet var én setning i DeepSeek-R1-papiret: modeller kan forbedre seg gjennom verifiable rewards. Det høres nesten magisk ut – men teknikken er egentlig ganske konkret. Og det som gjør dette eksperimentet interessant, er at én enkeltperson klarte å gjenskape kjerneprinsippet hjemme.
Her er hva de gjorde, hvorfor det fungerte, og hva det egentlig betyr for oss som er interessert i lokal AI.
Hva er verifiable rewards og GRPO?
Vanlig AI-trening krever at mennesker merker data manuelt – «dette svaret er bedre enn det». Det er dyrt, tregt og skalerer dårlig. Verifiable rewards tar en annen vei: i stedet for menneskelige vurderinger bruker du oppgaver der svaret enten er riktig eller feil.
Kode er perfekt for dette. Du gir modellen en oppgave, den produserer kode, og koden kjøres mot en test. Hvis testene passerer: belønning. Hvis ikke: ingen belønning. Ingen menneske trenger å si «dette svaret er bra». Maskinen finner ut det selv.
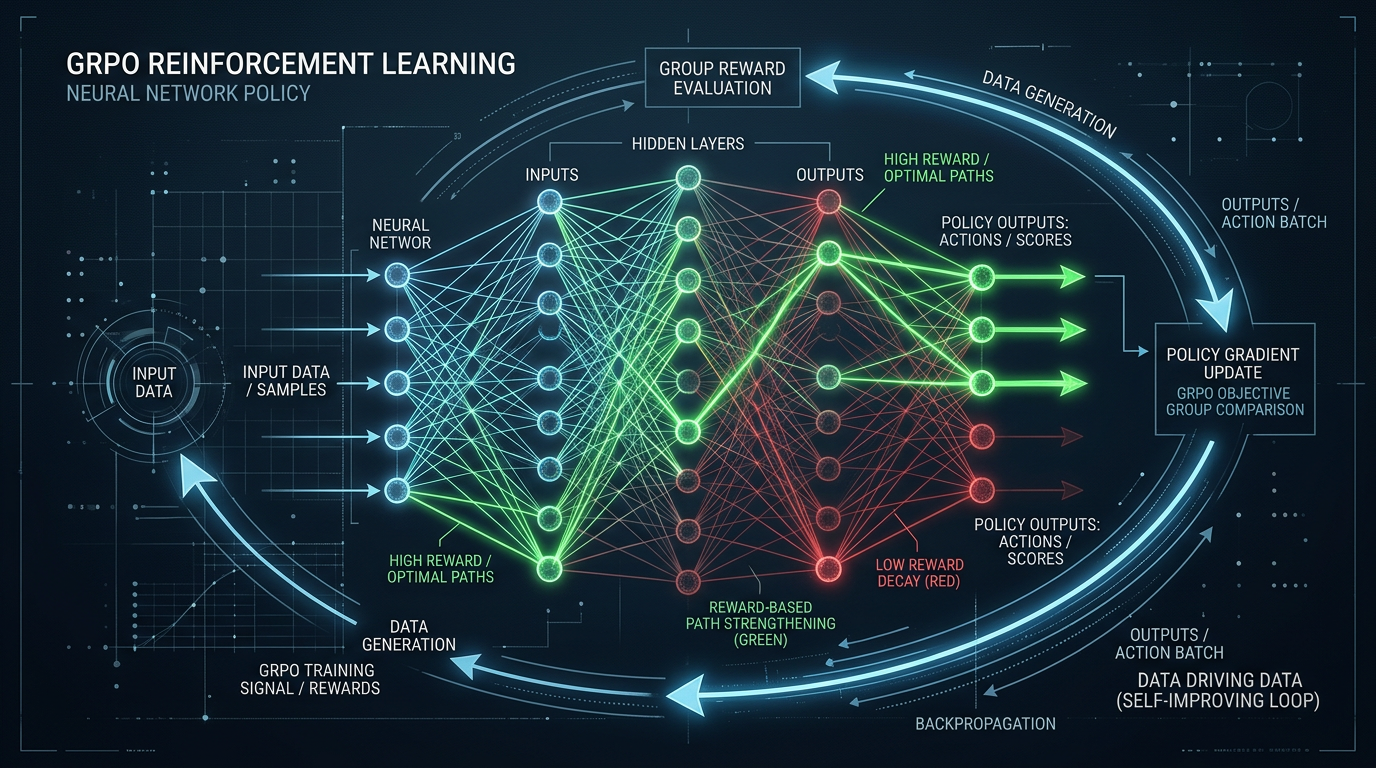
Metoden som ble brukt her heter GRPO (Group Relative Policy Optimization) – den samme RL-teknikken som DeepSeek brukte i R1. Den fungerer ved at modellen genererer flere svar på samme oppgave, sammenligner dem mot hverandre, og justerer vektene for å favorisere de som fikk belønning. Over tusenvis av iterasjoner begynner modellen å forstå hva «riktig kode» egentlig innebærer – ikke fordi noen fortalte den det, men fordi den prøvde og feilet systematisk.
Det er samme prinsipp som drev DeepSeek-R1 til toppresultater – bare nedskalert til noe én person kan kjøre på forbrukerhardware.
Hvordan ble eksperimentet gjennomført?
Planen var enkel: start med en liten åpen basemodell, generer kodeoppgaver, la modellen løse dem, kjør løsningene mot tester, og bruk resultatene som treningssignal. Ingen menneskeskrevet treningsdata. Bare kode, tester og belønning.
Hardwaren var ikke imponerende på papiret: en MacBook med 24 GB minne til eksperimentering, og et RunPod-oppsett med GPU-kraft for selve treningen. Det er en klassisk hobbyist-stack – presis nok til å validere ideer, kraftig nok til å faktisk kjøre GRPO over mange iterasjoner.
Basemodellen var en relativt liten åpen modell (under 10 milliarder parametere), valgt nettopp fordi den er håndterbar på forbrukerhardware. Treningsdataene ble generert automatisk: oppgaver laget av modellen selv, med Python-tester som fasit. Belønningssignalet var binært – koden enten kjørte og passerte testene, eller den gjorde det ikke.
Etter trening ble modellen evaluert på HumanEval – en samling kodingsoppgaver utviklet av OpenAI som er standard benchmark for kodings-AI – og på matematikk-benchmarks der GPT-3.5 er referansepunktet.
Hva ble resultatene?
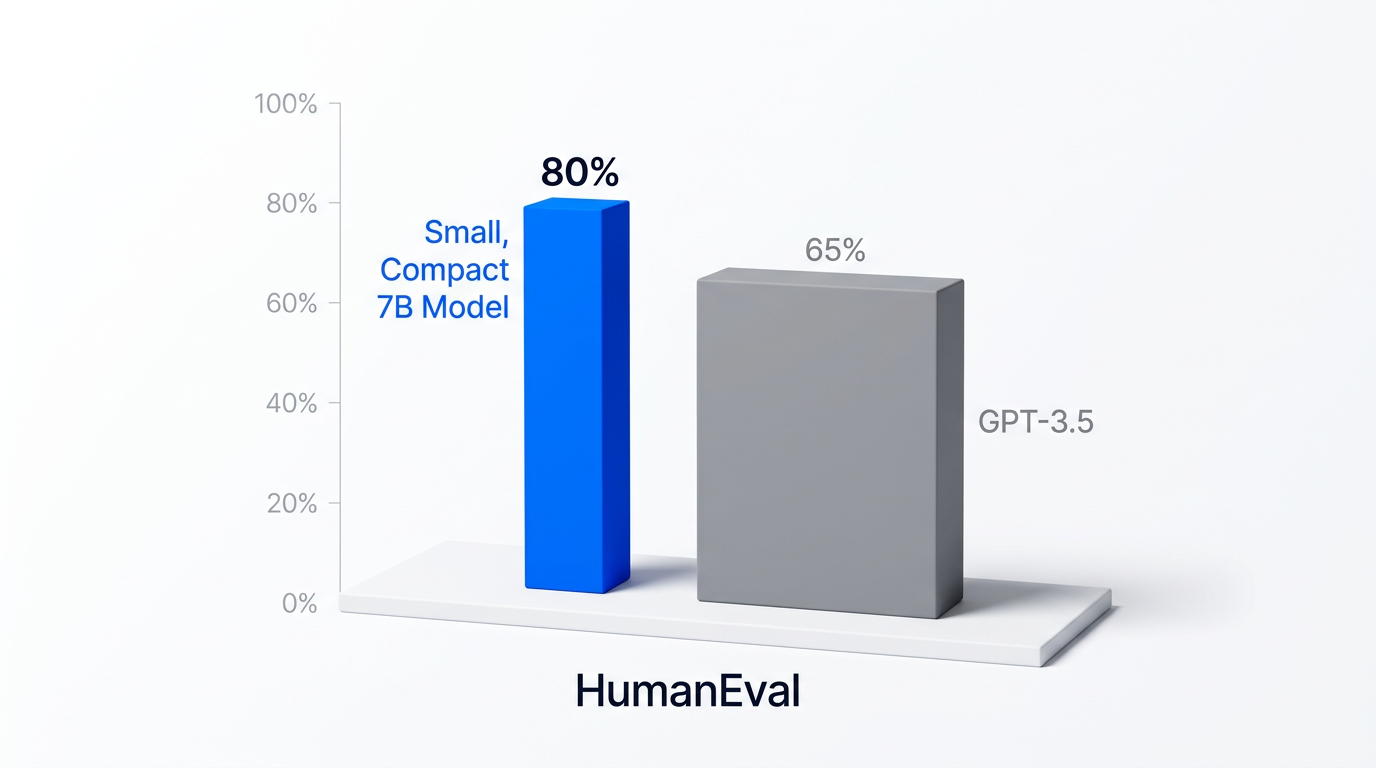
Modellen nådde 80 % på HumanEval. Til sammenligning skårer GPT-3.5 rundt 60-65 % på samme benchmark. På matematikk-oppgavene slo den selvtrente modellen GPT-3.5 direkte.
Det er verdt å pause et sekund her. En liten modell, trent av én person uten lab eller forskningsteam, på ett tema (koding), med en relativt enkel RL-loop – og den overgår en modell som kostet hundrevis av millioner å trene. Det sier noe om hvor kraftig spesialisert selvlæring kan være sammenlignet med generell pretraining.
Nøkkelen er at domenet er evaluerbart. Kode kjøres. Matte har fasit. Det finnes ingen tilsvarende enkel fasit for «skriv en god tekst» – og det er grunnen til at RL-trening fungerer spesielt godt for koding og matematikk akkurat nå, men er vanskeligere å overføre til andre domener.
Hva betyr dette for lokal AI?
Det interessante her er ikke bare tallene. Det er hva tallene antyder om retningen AI-trening tar.
Frem til nylig var forestillingen at bedre AI krever mer data, mer compute og større modeller. DeepSeek-R1 viste at reinforcement learning kan erstatte deler av den menneskeskrevne treningsdataen. Dette eksperimentet viser at prinsippet skalerer ned – ikke bare ned til middels store modeller, men til det vi kan kjøre lokalt.
Implikasjonen er ikke at alle nå kan lage sin egen ChatGPT. Den er mer nøktern og mer interessant: for nisjedomener med klare fasiter kan en liten, spesialisert modell trent hjemme overgå generelle modeller som er tusen ganger større. Det er nyttig for veldig mange konkrete bruksområder – spesielt innen koding, matematikk og andre felt der «riktig» faktisk kan verifiseres automatisk.
Det minner meg litt om ATLAS-eksperimentet som klarte konkurransedyktig koding på en 500-dollar GPU – tendensen er den samme. Hardware er ikke lenger den primære barrieren. Det er metodekunnskap.
Hva er begrensningene?
80 % på HumanEval er imponerende for en liten modell, men det er ikke hele bildet. HumanEval er et relativt smalt benchmark med kjente oppgavetyper – det er ikke det samme som å løse vilkårlige kodeproblemer i produksjon. Og spesialiseringen som gjør modellen god på koding, gjør den sannsynligvis dårligere på alt annet.
Reinforcement learning på verifiable rewards fungerer bare så godt som fasiten er. Kode kan kjøres. Men hva skjer når du vil spesialisere på noe litt mer diffust – som instruksjonsforståelse, sammendrag eller resonering om kontekst? Da trenger du andre tilnærminger.
Det er også verdt å huske at dette er ett eksperiment publisert på Reddit, ikke en fagfellevurdert studie. Tallene er selvrapporterte. Det betyr ikke at de er feil – men det er grunn til å ta dem som en interessant indikasjon heller enn en definitiv konklusjon. Benchmarks forteller deg én ting, men ikke alt.
Kan du gjøre dette selv?
Teknisk sett: ja. GRPO er implementert i åpne biblioteker som HuggingFace TRL. Basemodeller er tilgjengelige på Hugging Face. RunPod gir tilgang til GPU-kraft uten å kjøpe hardware. Python-tester kan genereres automatisk.
Praktisk sett krever det en del: kunnskap om PyTorch og transformers-biblioteket, forståelse av RL-konsepter, og tålmodighet til å debugge treningsløkker som er notorisk vanskelige å få til å konvergere. Det er ikke et ettermiddagsprosjekt for de fleste. Men det er heller ikke forbeholdt store forskningslaboratorier lenger.
Det er der vi er i 2026. Teknikker som for tre år siden krevde hundrevis av GPU-er og et fullt forskningsteam, kan nå gjenskapes av én person med en god laptop og litt skykraft. Det er ikke magisk – det er bare open source som fungerer.
Hva tenker du – er dette noe du ville prøvd? Og hvilke domener tror du ville egnet seg best for denne typen spesialisert selvlæring? Skriv gjerne i kommentarfeltet.







