

Innhold Vis
NVIDIA har sluppet en detaljert guide for å fine-tune Cosmos Predict 2.5 med LoRA og DoRA – og resultatene er overraskende gode. Modellen går fra å hallusinere menneskehender til å generere korrekte robotbevegelser, og det trengs bare 92 treningsvideoer for å komme dit.
Cosmos Predict 2.5 er en 2-milliard-parameter world model som genererer fysisk plausibel video fra tekst, bilder eller videosekvenser. Den er bygget for Physical AI – altså systemer der AI-modeller må forstå og simulere den fysiske verden. Robotikk er det mest åpenbare bruksområdet.
Det interessante her er ikke bare at det fungerer, men at treningsprosessen er overraskende tilgjengelig. Du trenger ikke 100 millioner videoer og et datasenter. Du trenger et gjennomtenkt datasett og tålmodighet – eller tilgang til 8 H100-er hvis tålmodigheten er begrenset.
Hva er Cosmos Predict 2.5?
Cosmos Predict 2.5 er NVIDIAs world model – en videomodell spesialisert for å forstå og generere fysisk korrekte scener. Den består av tre komponenter: en VAE som koder video til latent-representasjoner, en text encoder som koder tekstprompter, og en DiT (Diffusion Transformer) som gjennomfører selve diffusjonen i latent-rommet.
Treningsparadigmet heter rectified flow – modellen lærer å predikere hastigheten som transporterer støy mot ren data. Det gir bedre geometrisk stabilitet enn eldre diffusjonsteknikker, noe som er kritisk når du vil at en robot-arm faktisk skal treffe objektet den plukker opp.
Cosmos Predict 2.5 er tilgjengelig via Hugging Face og integrert med Diffusers-biblioteket. Det betyr at alt standard fine-tuning-verktøy fra Hugging Face-økosystemet fungerer direkte.
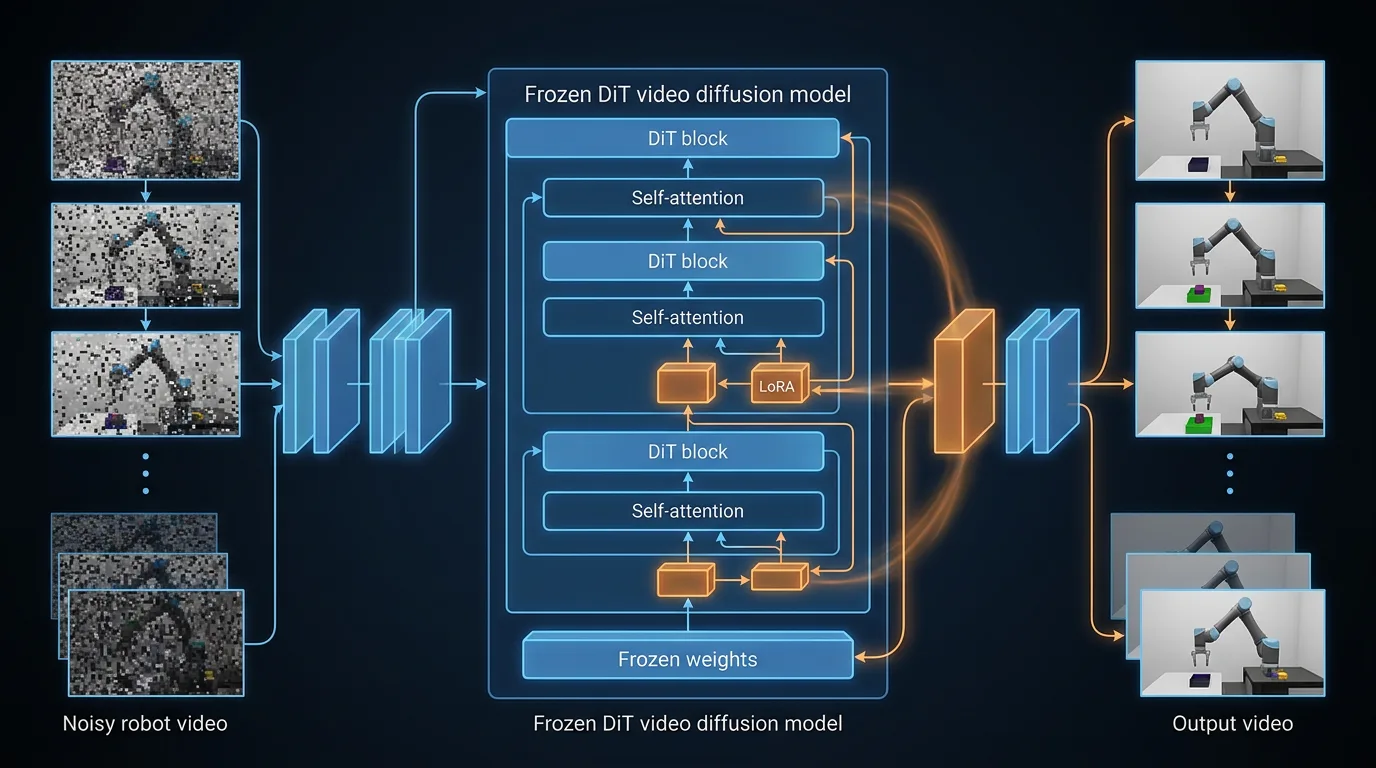
Hva er LoRA og DoRA – og hvorfor er det relevant her?
LoRA (Low-Rank Adaptation) er en teknikk for å fine-tune store modeller uten å måtte trene alle parameterne. I stedet injiseres små adapter-moduler i den frosne basemodellen. Adaptere er kompakte og bærbare, og du kan bytte mellom domener ved inference ved å laste inn forskjellige adapter-filer.
DoRA (Directional Low-Rank Adaptation) er en variant som dekomponerer vektene i magnitude og retning før den lav-rang-oppdateringen gjøres. I praksis er det bare å sette use_dora=True – ingen kodeendringer ellers. DoRA gir bedre stabilitet ved veldig lave rang-verdier, mens resultatene ved rang 32 er tilnærmet identiske med vanlig LoRA.
For Cosmos Predict 2.5 er det bare DiT-en som adapteres – attention- og feedforward-projeksjonene. VAE og text encoder holdes frosne. Det er en gjennomtenkt arkitekturvalg: VAE-en og text encoderen er allerede gode nok, det er videomodelleringsevnen som trenger domenespesifikk tilpasning.
Med LoRA rang=32 er det snakk om omtrent 50 millioner trenbare parametere, mot de 2 milliardene i basemodellen. Minnet som trengs halveres dramatisk, og adapter-filen som produseres er liten og enkel å distribuere. Se også AI-ordlisten for forklaring på flere begreper som diffusion, fine-tuning og embeddings.
Hva krever det å trene?
Her er det ærlig talt krevende. Minimum er én GPU med 80 GB VRAM – altså en A100 eller H100. Anbefalt oppsett for rask iterasjon er 8× H100-er. En enkelt H100 bruker omtrent 17 timer på 100 epoker; 8 H100-er gjennomfører samme jobb på 2,5 timer.
Det finnes ikke noe alternativ for RTX 4090 eller lignende consumer-hardware her – 80 GB er minimumskravet, og det er ikke oppfylt av noe forbrukerkort på markedet i dag. Dette er produksjonsverktøy for selskaper med tilgang til cloud-GPU eller dedikert hardware. NVIDIAs open source videomodell SANA-WM er et mer tilgjengelig alternativ om du vil eksperimentere med videomodeller lokalt.
Selve treningskommandoen ser slik ut:
accelerate launch --mixed_precision="bf16" train_cosmos_predict25_lora.py \
--pretrained_model_name_or_path="nvidia/Cosmos-Predict2.5-2B" \
--lora_rank 32 --lora_alpha 32 \
--num_train_epochs=500 \
--height 432 --width 768Treningsskript og evalueringsskript ligger i Diffusers examples/cosmos på GitHub.

Hvilke data ble brukt?
NVIDIA brukte GR1-100 – et datasett med bare 92 robot-manipulasjonsvideoer. Det er ikke mye. Videoene viser pick-and-place-oppgaver med tilhørende tekstprompt som beskriver hva roboten gjør.
Datasettformatet er enkelt: en mappe med videoer, en mappe med metadata, og en CSV-fil. Noe som gjør det realistisk å bygge egne domene-spesifikke datasett uten måneder med innsamlingsarbeid. 92 videoer er ikke mye mer enn en dedikert helg med et kamera og en robot. Evalueringssettet – PhysicalAI-Robotics-GR00T-Eval – inneholder 50 bilde-prompt-par som tester generalisering.
Hva ble resultatene?
Resultatene er tydelige. Basemodellen scoret 2,1 på instruction following (skala 1-5, målt av en annen AI-modell). Med LoRA rang=8 gikk scoren til 3,2, og med rang=32 til 3,8. DoRA rang=32 matchet LoRA rang=32.
Kvalitativt er forbedringen mer iøynefallende: basemodellen hallusinerer menneskehender i stedet for robotarmer, bruker feil hånd, og har merkbar jitter mellom frames. Etter fine-tuning vises korrekte robotarmer, riktig håndbruk per prompt, og videoen er temporalt stabil.
Temporal Sampson Error – et geometrisk konsistens-mål – forbedret seg for alle varianter. Rang=8 er best på å bevare geometriske priors fra basemodellen; rang=32 er best på instruction following. Det er en reell avveining, ikke bare «mer er bedre».
100 epoker gir allerede substansiell forbedring. 500 epoker (standard i treningskommandoen) er anbefalt for produksjonskvalitet.
Slik bruker du en ferdig LoRA-adapter
Inference er rett frem via Diffusers. Du laster inn basemodellen, laster inn LoRA-vektene, og kaller pipe.fuse_lora() for å eliminere inference-overhead. Deretter genererer du video på vanlig måte:
from diffusers import Cosmos2_5_PredictBasePipeline
pipe = Cosmos2_5_PredictBasePipeline.from_pretrained(
"nvidia/Cosmos-Predict2.5-2B",
torch_dtype=torch.bfloat16,
device_map="cuda"
)
pipe.load_lora_weights("/path/to/lora/checkpoint")
pipe.fuse_lora(lora_scale=1.0)Videoen genereres med 93 frames ved 432×768 og 16 fps – omtrent 5,8 sekunder video per inference-kjøring. Antall inference-steg er 36, noe som gir god kvalitet uten for lang ventetid.
Physical AI-agenter som bruker slike videomodeller til simulering og planlegging er et tema som vokser raskt. Humanoide roboter er der mye av interessen er nå, men manipulasjonsroboter for industri og lager er nærmere kommersielt gjennombrudd. Se også Gemini Robotics-ER 1.6 for et annet eksempel på robotikk-AI i rask utvikling.
Hvem er dette relevant for?
Robotikk-selskaper som jobber med manipulasjonsoppgaver er den åpenbare målgruppen. World models som Cosmos er i ferd med å bli en standard komponent i robot-trenings-pipelines – ikke for å erstatte ekte robot-erfaringsdata, men for å utvide det og generere syntetiske treningsscenarier.
Akademiske grupper innen robotikk og Physical AI kan bruke dette som en stabil baseline for eksperimenter. NVIDIA har gjort verktøyet tilgjengelig med Diffusers-integrasjon og åpne datasett, noe som senker terskelen betraktelig.
For rene programvareutviklere uten tilgang til robotikk-hardware er dette foreløpig akademisk interessant. Men det er verdt å følge med – slike verktøy beveger seg raskt fra «krevende forskning» til «tilgjengelig produktverktøy». Asimov v1 open source humanoid robot er et tegn på at hyllevare-robotikk nærmer seg.
Fine-tuning av videomodeller for domene-spesifikke oppgaver er ikke lenger noe bare de 10 største AI-laboratoriene kan gjøre. Med 92 videoer og en H100 er det mulig å bygge noe nyttig. Det er et godt tegn for feltet – og for alle som jobber med robotikk og Physical AI.








1 kommentar