

Innhold Vis
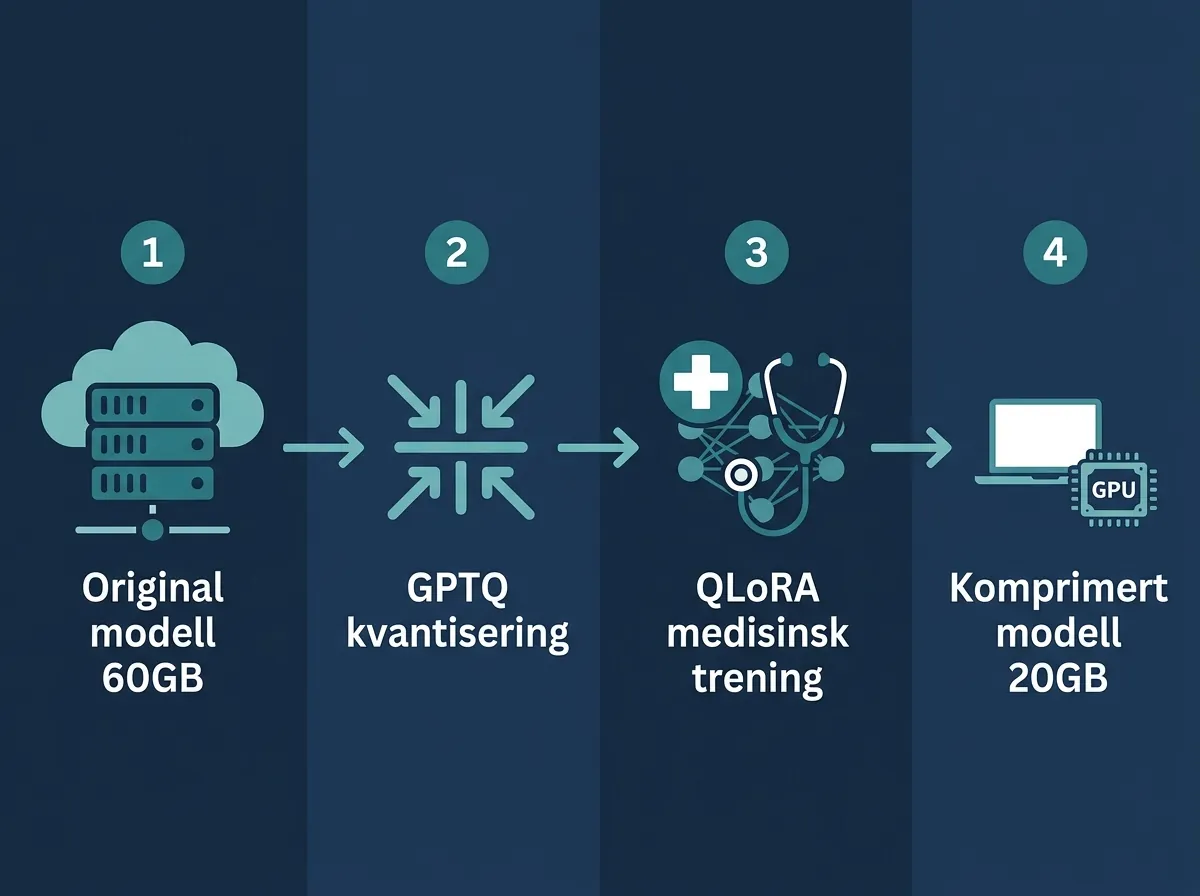
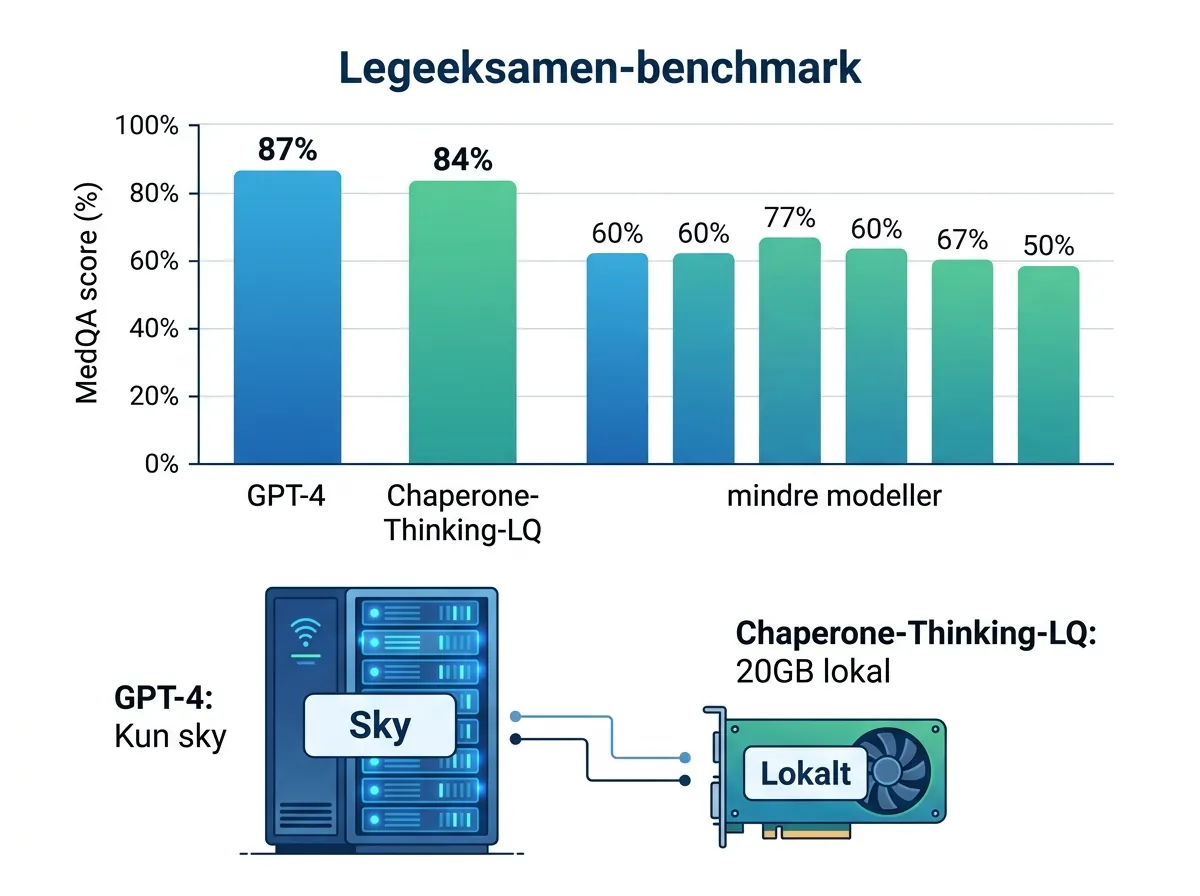
Chaperone-Thinking-LQ-1.0 er en åpen medisinsk AI-modell lansert av Chaperone Labs – en 32 milliarder parameter reasoning-modell som er kvantisert ned til ~20GB og scorer 84% på MedQA, det tøffeste medisinsk spørsmål-og-svar-benchmarket som finnes. Utgangspunktet er DeepSeek-R1-Distill-Qwen-32B, men teamet har gått langt forbi en vanlig kvantisering.
Det som gjør dette interessant er ikke bare tallene. Det er at de har kombinert 4-bit GPTQ-kvantisering, kvantiseringssikker trening (QAT) og QLoRA-finjustering på medisinske og vitenskapelige korpus – alt i én pipeline. Resultatet er en modell som veier ~20GB mot de originale ~60GB, men beholder mesteparten av ytelsen. Den kan kjøres på forbrukerhardware med 24GB VRAM, for eksempel en RTX 3090 eller 4090.
Modellen er publisert på Hugging Face under en åpen lisens. Her er hva som er gjort, og hva det betyr i praksis.
Hva er MedQA, og hvorfor er 84% imponerende?
MedQA er et benchmark basert på spørsmål fra legeeksamen (USMLE – United States Medical Licensing Examination). Spørsmålene er flervalgsspørsmål som tester klinisk resonnement, ikke bare faktapugging. Mange av de største proprietære modellene sliter med dette – det krever evnen til å kombinere medisinsk kunnskap med logisk resonnement under usikkerhet.
84% på MedQA er et solid resultat. For kontekst: tidlige versjoner av GPT-4 scoret rundt 87-90%, men det er en modell som er mange ganger større og koster mye mer å kjøre. Å komme til 84% med en ~20GB modell du kan kjøre lokalt, er genuint interessant – ikke bare som teknisk bragd, men fordi det åpner opp for brukstilfeller der sentralisert skyinfrastruktur ikke er ønskelig.
Benchmarks sier ikke alt, og jeg er som regel skeptisk til dem isolert sett. Men MedQA er et av de mer respektable testene fordi det krever faktisk resonnement, ikke bare memorert tekst.
Hva er selve treningspipelinen?
Dette er den teknisk interessante biten. Chaperone Labs har ikke bare tatt DeepSeek-R1-Distill-Qwen-32B og kjørt den gjennom et standard kvantiseringsskript. De har gjort fire ting i serie:
- 4-bit GPTQ-kvantisering – komprimerer modellen fra ~60GB til ~20GB ved å representere vekter med lavere presisjon
- Kvantiseringssikker trening (QAT) via GPTQ med kalibrering – minimerer nøyaktighetstapet som normalt oppstår ved aggressiv kvantisering
- QLoRA-finjustering på medisinske og vitenskapelige korpus – spesialiserer modellen på domenet den skal brukes i
- Fjernet det adaptive identitetslaget – øker transparens ved å fjerne en komponent som gjør det vanskeligere å forstå hva modellen faktisk gjør
Det siste punktet er uvanlig. Mange modeller beholder adaptive lag som kan forbedre ytelsen marginalt, men som gjør modellen mindre tolkbar. At teamet valgte å fjerne det for transparensens skyld, er et bevisst designvalg som sier noe om hva de prioriterer.
Kan du kjøre den lokalt?
Det er det interessante spørsmålet. ~20GB betyr at du trenger rundt 24GB VRAM for å laste den i GPU-minnet. Det er innenfor det en RTX 3090 (24GB), RTX 4090 (24GB) eller RTX 4000 Ada (20GB) håndterer. En enkelt RTX 4090 gir deg akselerert inferens uten skyavhengighet.
Har du ikke 24GB VRAM, kan du kjøre modellen i CPU/GPU-hybrid-modus via llama.cpp eller Ollama, men da dropper ytelsen og hastigheten betydelig. Vil du ha ordentlig ytelse, trenger du GPU med nok minne.
For de som jobber med medisinske applikasjoner og trenger lokal kjøring – enten på grunn av personvern, kostnader eller regulatoriske krav – er dette et reelt alternativ til å sende sensitiv data til OpenAI eller Google. Det er ikke trivielt å sette opp, men det er fullt mulig med riktig hardware.
Hva er DeepSeek-R1 – og hva betyr «distill»?
Grunnmodellen, DeepSeek-R1-Distill-Qwen-32B, er en «destillert» versjon av DeepSeek-R1 – det kinesiske selskapet DeepSeeks reasoning-modell som skapte overskrifter tidlig i 2025 da den matchet GPT-4-klassen til en brøkdel av treningskostnadene.
«Destillasjon» betyr i denne konteksten at en større modell har lært opp en mindre. Læreren (den store modellen) genererer treningseksempler, og eleven (den mindre modellen) lærer å etterligne resonnementsmønstrene. Resultatet er en modell som er mye raskere og billigere å kjøre, men beholder mye av reasoning-evnen.
32B-parametervarianten er den mellomste i Qwen-destillasjonsfamilien – ikke den minste (7B, 14B), og ikke den største (70B). Den er stor nok til å være nyttig for komplekse oppgaver, men liten nok til å faktisk kjøres på forbrukerhardware etter kvantisering.
Er medisinsk AI trygt å bruke?
Det korte svaret er: ikke uten menneskelig tilsyn, og Chaperone Labs sier det eksplisitt. Modellen er ment som et verktøy for medisinsk forskning og utdanning – ikke som erstatning for klinisk vurdering fra en lege.
Det er det riktige utgangspunktet. En modell som scorer 84% på legeeksamen-spørsmål er imponerende, men 16% feilrate i kliniske beslutninger er ikke akseptabelt. Den kan imidlertid være genuint nyttig for:
- Medisinsk utdanning og øvelse (spørsmål-og-svar trening)
- Første gjennomgang av medisinske dokumenter
- Forskningsassistanse der en ekspert verifiserer output
- Tilgjengelighet i ressursbegrensede miljøer der alternativet er ingen assistanse
Det minner meg litt om diskusjonen rundt Nvidias AI-Q forskningsagent – kraftige verktøy som er genuint nyttige, men som krever at du forstår grensene. Den som tror en AI-modell erstatter en lege, har misforstått teknologien.
Hva er egentlig nytt her?
Kvantiserte modeller er ikke noe nytt. GPTQ har eksistert en stund, og QLoRA-finjustering er en etablert teknikk. Det som skiller Chaperone-Thinking-LQ-1.0 er kombinasjonen:
De fleste kvantiseringsprosjekter tar en grunnmodell og komprimerer den. Chaperone Labs har komprimert og spesialisert i samme pipeline, med en ekstra bevissthet rundt nøyaktighetstap via QAT-kalibrering. Det er mer gjennomarbeidet enn de fleste «bare last ned og kjør»-kvantiseringer du finner på Hugging Face.
Transparensvalget – å fjerne det adaptive identitetslaget – er også uvanlig. I en tid der mange AI-prosjekter maksimerer ytelse uavhengig av tolkbarhet, er det en merkbar prioritering. Medisinsk AI som er vanskelig å forstå er medisinsk AI som er vanskelig å stole på.
For de som er interessert i kvantiseringsteknikkene som gjør dette mulig, er TurboQuant-artikkelen et godt utgangspunkt – den forklarer de underliggende metodene som gjør det mulig å komprimere store modeller uten å miste for mye ytelse.
Hva betyr dette for open source medisinsk AI?
Trenden er tydelig: reasoning-modeller som tidligere bare eksisterte i skyen, blir tilgjengelige lokalt. Det er bra for personvern, bra for kostnadskontroll, og bra for de som vil forstå hva modellen faktisk gjør.
Google DeepMind, Anthropic og OpenAI dominerer i den øvre enden, men reasoning-AI-feltet generelt beveger seg raskt nedover i størrelse og ressurskrav. Chaperone-Thinking-LQ-1.0 er ett eksempel på en modell som for tolv måneder siden ville krevd dedikert serverinfrastruktur, men som nå kan kjøres på en gamer-PC.
Modellen er tilgjengelig på Hugging Face. Har du 24GB VRAM og interesse for medisinsk AI, er det verdt å se nærmere på.








1 kommentar