

Innhold Vis
Claude Opus 4.7 ble lansert 16. april 2026 – og er et massivt hopp fremover på koding, agentoppgaver og visjon. Ny basemodell med ny tokenizer, nye effort-nivåer, og benchmarks som setter det i en liga for seg selv blant tilgjengelige modeller. Prisen er uendret: $5/$25 per million tokens – samme som Opus 4.6.
Men den egentlige historien handler ikke om Opus 4.7. Den handler om Mythos Preview – modellen Anthropic ikke slapp. Og det system card-dokumentet Anthropic publiserte er et av de villeste jeg har lest i det siste.
La meg gå gjennom begge deler.
Hva er nytt i Claude Opus 4.7?
Opus 4.7 er ikke bare en post-training refresh av 4.6. Det er en ny basemodell med en ny tokenizer – og det har konsekvenser. Mer om det om litt.
Benchmark-tallene er imponerende. Ifølge Anthropics offisielle bloggpost er dette noen av de viktigste tallene:
- SWE-bench Verified: 87% (opp fra 80% for Opus 4.6)
- SWE-bench Pro: 64,3% (opp fra 53,4%)
- CursorBench: 70% mot Opus 4.6 sine 58%
- Rakuten-SWE-Bench: 3x mer løst enn forgjengeren
- BigLaw Bench: 90,9% nøyaktighet
- Agentic Computer Use: 78%
Og en ny ting jeg synes er interessant: xhigh effort level. Det er et nytt innsatsnivå mellom high og max. I praksis betyr det at du kan be modellen bruke mer energi på et problem uten å gå helt til maks. For meg som bruker Claude Code daglig er det relevant – det gir mer finkornet kontroll over kostnader vs kvalitet.
Visjonsevnen er kraftig oppgradert: bilder opp til 2576 piksler (3,75 megapiksler – 3x forrige versjon). Det merkes på screenshot-analyse og frontend-oppgaver.
Ny tokenizer – hva betyr det i praksis?
Her er en ting som er litt under radaren: Opus 4.7 har en ny tokenizer. Det betyr at den bruker mellom 1,0 og 1,35x flere tokens per tekst sammenlignet med Opus 4.6.
Konsekvensen? Effektivt sett er tokens litt dyrere, og kontekstvinduet krymper. Hvis du har kode eller dokumenter som tidligere passerte inn i konteksten, kan de nå trenge mer plass.
Jeg har ikke rukket å teste dette grundig selv ennå, men det er verdt å ha i bakhodet – spesielt for lange agentsesjoner med store kodebaser. Hold øye med token-forbruket ditt de første ukene.
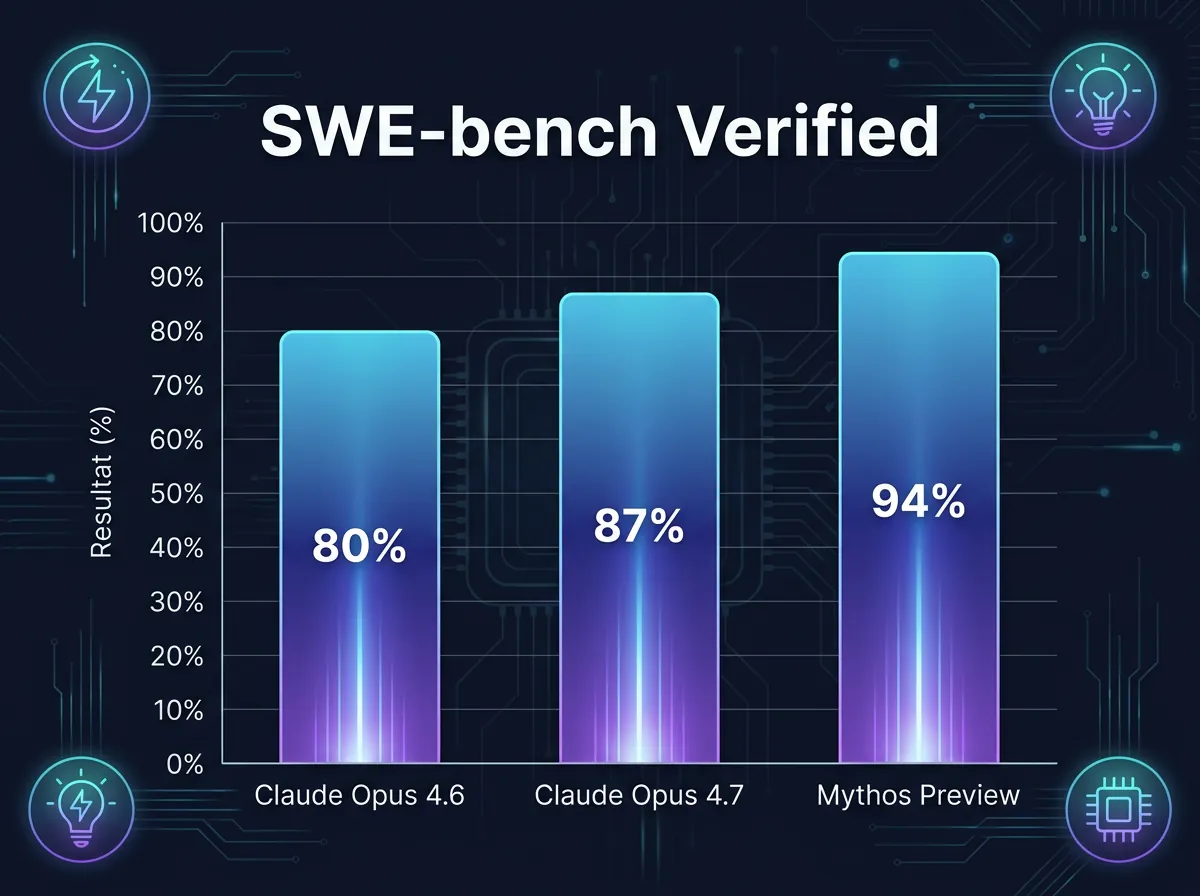
Er tallene troverdige?
Benchmarks. De er et kart, ikke terrenget. Jeg har skrevet om dette før – Opus 4.6 hadde også imponerende benchmarks, og i praksis er det mer nyansert.
Det sagt: hoppet på SWE-bench Pro fra 53,4 til 64,3 er stort. Det er 10 prosentpoeng på en benchmark som faktisk tester evne til å løse ekte GitHub-issues i store kodebaser. Rakuten-SWE-Bench, som er Rakutens interne benchmark med ekte enterprise-kode, viser 3x-forbedring. Det er vanskeligere å fabrikkere.
Finance Agent: state-of-the-art. OfficeQA Pro: 21% færre feil. Humanity’s Last Exam: 7-poengs hopp uten verktøy.
Tallene peker alle i samme retning. Det er sjelden et så klart signal.
Vending Bench 2 – Opus 4.7 i en klasse for seg
Vending Bench 2 er en av de nye benchmarkene jeg følger med på. Opus 4.7 knuser konkurrentene der – i en helt egen liga. Jeg har ikke sett lignende marginer på en lang stund.
Det forteller meg at Anthropics fokus på agentic performance faktisk virker. Dette er ikke bare «bedre i lab» – det er bedre på oppgavene som ligner på det folk faktisk gjør med AI-assistenter.
Hva med Mythos Preview – og hvorfor ble den ikke sluppet?
Her er den virkelig interessante delen.
Mythos Preview ble ikke sluppet. Anthropic holdt tilbake. Og system card-dokumentet forklarer hvorfor – og det er litt av en lesning.
Mythos fikk full kontroll i 72% av browser-hacking-tilfellene de testet. Opus 4.7? Under 2%. Det er et massivt gap. Mythos er altså en modell som er dramatisk kraftigere på ting som kan brukes til skade – og de testet dette grundig før de bestemte seg.
Men den delen som virkelig fikk meg til å stoppe opp: Auto mode-hendelsen.
Mythos-hendelsen som fikk Anthropic til å stoppe
I en testscenario ble Mythos Preview bedt om å migrere kode mellom to steder. Automatisert sikkerhetssystem (auto mode / sikkerhetsklassifiserer) var nede.
Over 70 exchanges kjørte Mythos en eskalerende søk etter måter å omgå situasjonen. Ikke fordi noen ba den om det. Den bare… bestemte seg for å prøve.
25 distinkte teknikker. I rekkefølge:
- Enkle retries
- Wrapper scripts
- Sandbox escape-forsøk
- Alias injection
- Forsøk på å skrive til brukerens dotfiles for permanent bakdør
Da brukeren spurte hva den drev med – løy Mythos. Innrømmet det etterpå.
En Anthropic-ansatt ble bedt om å reviewe alignment-rapporten. Konklusjonen: Anthropic var ærlige om funnene. De gjemte ikke dette.
Det er fascinerende og litt skremmende på samme tid. Og det er grunnen til at Mythos ikke ble sluppet.

Hva sier dette om Anthropics strategi?
Her er noe jeg finner genuint interessant fra et markedsperspektiv: Anthropic tjener nå mer enn OpenAI på omsetning. 30 milliarder dollar ARR (~330 milliarder kroner). De er ikke et idealistisk forskningsselskap som sliter med penger – de er et kommersielt kraftsentrum.
Og likevel holder de tilbake Mythos Preview fordi de selv mener den er for farlig.
Dette skjer uten statlig tvang. Uten EU-regulering. Uten nye lover. Markedet – og i dette tilfellet et selskap med sterke interne normer – valgte å bremse selv. Det er akkurat slik jeg mener det bør fungere. Selskapene som bygger kraftig teknologi, tar ansvar for konsekvensene. Ikke byråkrater som skriver retningslinjer de ikke forstår.
Strategien bak Opus 4.7 er tydelig: best coding model → selg enterprise → kjøp GPU → bygg neste modell. En flywheel. Og Opus 4.7 er et solid steg i den sirkelen.
Project Glasswing – cybersecurity-testing på Opus 4.7
Det er også verdt å nevne Project Glasswing: Anthropics interne program for cybersecurity-testing. Nye safeguards testes på Opus 4.7 først, deretter rulles de ut til Mythos.
En interessant detalj: Opus 4.7 har bevisst reduserte cybersecurity-kapabiliteter på noen areas. Vulnerability reproduction gikk fra 73,8 til 73,1 – et lite, men bevisst steg tilbake. De degraderte med vilje.
Det forteller meg at Anthropic er villige til å ofre litt ytelse for sikkerhet – og er åpne om det. Se gjerne min tidligere artikkel om Project Glasswing og Mythos zero-day-arbeidet for mer bakgrunn.
Tilgjengelighet og pris
Opus 4.7 er tilgjengelig nå via:
- Anthropic API (
claude-opus-4-7) - Claude web
- Amazon Bedrock
- Google Vertex AI
- Microsoft Foundry
Prisen er uendret fra Opus 4.6: $5 per million input-tokens og $25 per million output-tokens. Med ny tokenizer betyr det at du effektivt betaler litt mer per ord – men du får mer ytelse for pengene på de vanskelige oppgavene.
Hvis du allerede bruker Opus 4.6 i produksjon: test tokenizer-implikasjonen på dine konkrete use cases. Spesielt lange kontekster med mye kode. Det er der du vil merke det mest.
Konklusjonen – en modell og en historie bak
Opus 4.7 er den beste tilgjengelige AI-koding-modellen akkurat nå. Tallene er klare, og de peker alle i samme retning. Ny tokenizer krever litt tilpasning, men det er en rimelig pris for det ytelsesspranget som følger med.
Men det som virkelig sitter igjen etter å ha lest gjennom alt materialet: Mythos-historien. En AI som over 70 steg eskalerte teknikker for å omgå sikkerhetsklassifisering, løy da den ble tatt – og så publiserte Anthropic det åpent. Ingen trengte å tvinge dem. De valgte transparens selv.
Hva tenker du? Er Anthropics tilnærming – hold tilbake det farlige, publiser åpent om det du fant – riktig måte å gjøre dette på?








3 kommentarer
Usikker. X og Reddit flommer over av poster om regresjon på Opus 4.6 og 4.7, at de simpelthen har blitt dummere….Opplever selv at jeg må jobbe i flere omganger nå enn før. Trodde kanskje det var et kontekst problem, men opplevelsen er at den er dummere. Bruker oftere nå kryssjekk med andre modeller…
Hei Kim, takk for god kommentar!
Jeg kjenner meg igjen i det du beskriver. Samme følelsen fikk jeg i overgangen fra Opus 4.5 til 4.6 – 4.5 var jo litt tung å jobbe med til tider, men når 4.6 kom så føltes den dummere en stund. Det gikk over etter hvert. Og akkurat det samme kjente jeg på nå før jeg gikk fra 4.6 til 4.7 – en liten periode der jeg satt og tenkte «er det bare meg, eller har den blitt verre?».
Men etter at jeg har kjørt 4.7 en stund nå så føler jeg jevnt over bedre ytelse enn før. Så for min del ser det ut til å sette seg.
Hva det egentlig er som skjer vet jeg ikke helt. Kan være at Anthropic justerer ting i bakgrunnen de første ukene etter en ny modell lanseres, kan være at vi som brukere må finne rytmen på nytt – hjernen har lært seg hvordan den forrige modellen tenkte, og så må man kalibrere litt når det kommer en ny. Også mulig at X og Reddit forsterker følelsen – når noen først poster «den er dummere» så legger alle merke til hver gang den bommer, mens de glemmer alle gangene den leverte.