

Innhold Vis
Vanlig RAG søker én gang og håper på det beste. Det er problemet. Hvis det første søket ikke finner alt det trenger, lager AI-en et svar basert på ufullstendig grunnlag – og du merker det kanskje ikke før du har stolt på svaret. Google Research har nå lagt til noe de kaller en Sufficient Context Agent i Gemini Enterprise Agent Platform, og ideen er enkel: systemet søker om igjen til det faktisk har nok informasjon til å svare skikkelig.
De kaller det agentic RAG, og det er en vesentlig oppgradering fra den klassiske retrieve-and-generate-løkken som de fleste RAG-systemer bruker i dag. I stedet for å trekke ut litt data og produsere et svar, planlegger systemet, re-skriver spørsmål, distribuerer søk på tvers av datakilder og sjekker om svaret er tilstrekkelig godt grunnet – alt før det skriver en eneste setning til deg.
Resultatene de rapporterer er ikke ubetydelige: opp til 34% bedre faktanøyaktighet sammenlignet med standard RAG, og 90,1% presisjon i scenarier der systemet selv må velge riktig datakilde blant fire alternativer. Det er verdt å se nærmere på hva som faktisk foregår under panseret.
Hva er egentlig problemet med vanlig RAG?
RAG – Retrieval-Augmented Generation – er i utgangspunktet en fin idé: i stedet for å la en språkmodell gjette basert på treningsdata, henter du relevant informasjon fra en faktisk datakilde og gir det til modellen som kontekst. Brukt riktig gir det mer faktamessig presise svar og lar deg bygge AI-systemer på toppen av bedriftens egne data uten å finjustere modellen.
Problemet er de enkle søkeløkkene de fleste implementasjoner bruker. Du stiller et spørsmål, systemet gjør ett søk, finner noe, og svarer. Det fungerer greit for enkle forespørsler, men faller raskt sammen når spørsmålet krever informasjon fra flere steder – det Google kaller multi-hop queries.
Et konkret eksempel: en ingeniør spør «hva er serverspecene for Prosjekt X?» Systemet finner en server-ID i én database, men klarer ikke på egenhånd å gå videre til en annen database for å slå opp hva den ID-en faktisk innebærer. Standard RAG stopper der. Agentic RAG fortsetter.
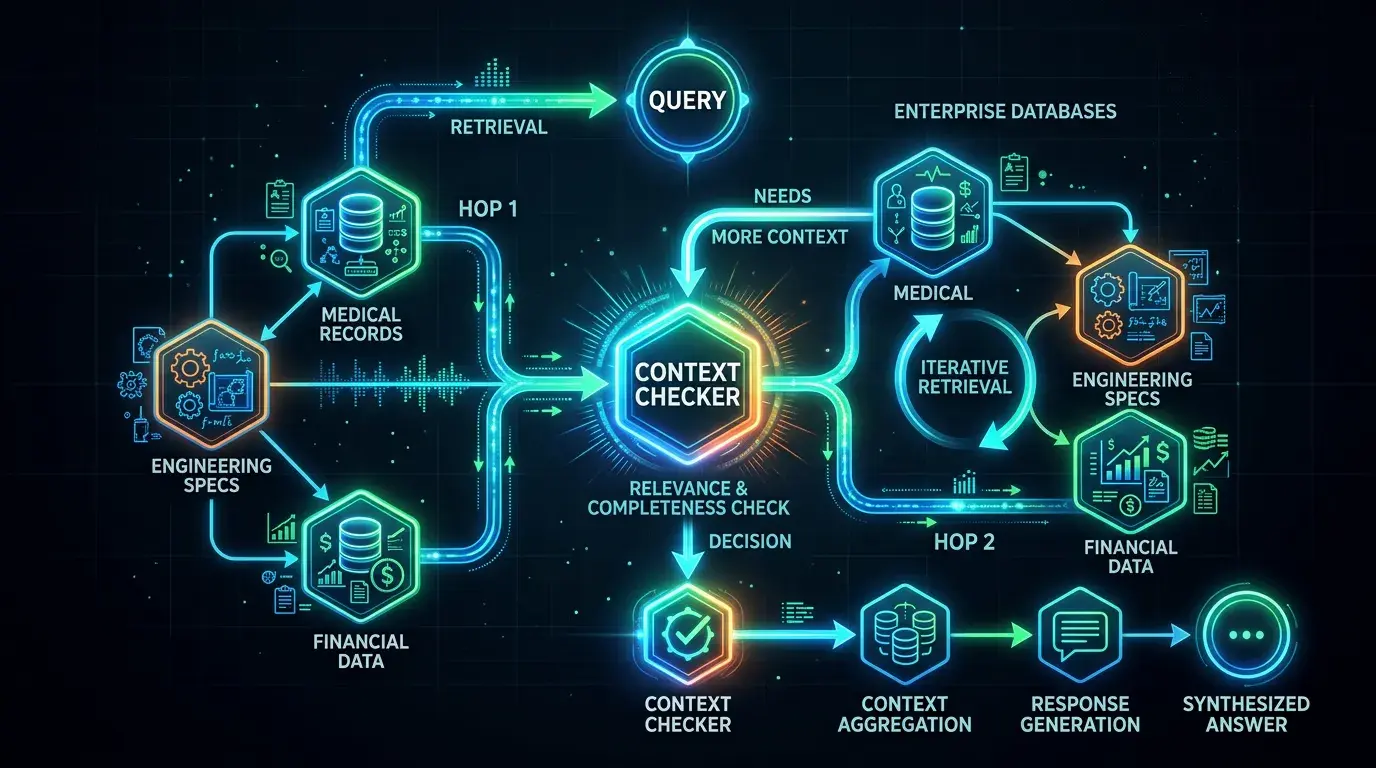
Hva gjør Sufficient Context Agent konkret?
Sufficient Context Agent er kvalitetssjekken som mangler i de fleste RAG-systemer. Etter at systemet har søkt og hentet inn informasjon, tar denne agenten en titt på hva som faktisk ble funnet – og spør: er dette nok til å svare skikkelig?
Det smarte er at den ikke bare flagger at noe mangler. Den skriver en konkret logg over hva som mangler og hvorfor, slik at neste søk kan rettes mer presist mot riktig informasjonsgap. Det er forskjellen mellom å si «vi vet ikke nok» og «vi vet ikke hvilke kliniske studier som støtter denne doseringen – søk igjen etter det.»
Hele arkitekturen består av fem spesialiserte agenter som håndterer hvert sitt steg:
- Orchestrator – tar imot forespørselen og ruter den riktig
- Planner Agent – kartlegger hvilke datakilder som inneholder relevant informasjon
- Query Rewriter – omformulerer vage spørsmål til søkbare, presise spørringer
- Search Fanout Agent – distribuerer søk parallelt på tvers av datakilder
- Synthesis Agent – setter sammen det endelige svaret
Sufficient Context Agent sitter mellom Search Fanout og Synthesis. Hvis den ikke er fornøyd med hva som kom inn, sender den systemet tilbake til Planner – med konkret feedback om hva som må finnes.
Hvilke resultater rapporterer Google?
Google testet rammeverket på FramesQA, et benchmark med 824 spørsmål fordelt over 2676 PDF-dokumenter designet nettopp for multi-hop-problemer. I cross-corpus-scenariet – der systemet selv må identifisere hvilken av fire datakilder som inneholder riktig informasjon – kom de ut med 90,1% presisjon.
Forbedringen i faktanøyaktighet sammenlignet med standard RAG var på opptil 34%. Det er et tall jeg ville tatt med en klype salt i isolasjon, men i kombinasjon med at latenstiden bare økte med 3% mellom enkelt- og flerkilde-operasjoner, er det et argument for at tilnærmingen faktisk er praktisk gjennomførbar og ikke bare et akademisk konsept.
Jeg har ikke testet dette selv, så jeg kan ikke si noe om hvordan det oppfører seg på norsk bedriftsdata i produksjon. Men tallene peker i en interessant retning, spesielt for organisasjoner som sliter med fragmenterte datasiloer.
Hvem er dette relevant for i praksis?
Google trekker frem tre brukstilfeller i rapporten sin: helsetjenester som jobber med separate databaser for medisin, ernæring og allergier, ingeniørteam som sporer komponentspesifikasjoner på tvers av systemer, og finansavdelinger som integrerer budsjett- og tidslinjeinformasjon.
Det handler med andre ord om virksomheter med fragmentert dataeierskap – der informasjonen som trengs for å svare på et spørsmål typisk sitter i to eller tre forskjellige systemer som ikke prater naturlig med hverandre. Det er ikke et nisje-problem. Det er hverdagen for de fleste mellomstore til store organisasjoner jeg kjenner til.

For norske virksomheter som allerede ser på Gemini Enterprise, er dette verdt å følge med på. Grunnideen – at AI-systemet skal iterere til det har nok grunnlag – er egentlig det alle burde forvente av et enterprise RAG-system. At det har tatt så lang tid å komme dit sier kanskje mer om bransjen enn om Google spesielt.
Er dette noe nytt, eller er det gammelt nytt?
Agentic RAG som konsept har vært diskutert lenge i AI-miljøer, og det finnes open source-implementasjoner som gjør noe av det samme. Det som er nytt her er at Google bygger det direkte inn i en enterprise-plattform med en konkret, navngitt komponent (Sufficient Context Agent) og rapporterer målbare tall på et standardisert benchmark.
Det gir organisasjoner noe håndgripelig å forholde seg til – i stedet for å selv sy sammen agenter og håpe at kvalitetskontrollen holder. Jeg er nysgjerrig på om og når dette kommer til å dukke opp i de nordiske Workspace-tilbudene. Gemini har allerede et bredt sett med enterprise-funksjoner, og agentic RAG er naturlig neste steg.
Det er også interessant å se dette i lys av Googles agentic vision-satsing – der trenden tydelig går mot AI som aktivt utforsker og itererer, ikke bare svarer. Gemini som forskningsverktøy har lenge handlet om dype søk, og dette bygger videre på samme tankegang.
For den som vil grave dypere er det også verdt å se på hva LLMSearchIndex gjør med lokal RAG – det er en annen tilnærming til samme grunnproblem, bare uten skyavhengigheten.
Ofte stilte spørsmål
Hva er forskjellen på vanlig RAG og agentic RAG?
Vanlig RAG søker én gang og svarer basert på det som kom opp. Agentic RAG itererer – systemet sjekker om det hentet nok informasjon, og søker igjen med mer presise spørsmål hvis svaret er mangelfullt. Googles implementasjon rapporterer opptil 34% bedre faktanøyaktighet som resultat.
Trenger jeg Gemini Enterprise for å bruke dette?
Per juni 2026 er Sufficient Context Agent en del av Gemini Enterprise Agent Platform. Open source-alternativer som LangChain og LlamaIndex har lignende agentic RAG-funksjoner, men Googles tilnærming er integrert direkte i enterprise-plattformen med ferdig arkitektur.
Hva er en multi-hop query?
En multi-hop query er et spørsmål som krever informasjon fra flere datakilder i sekvens. For eksempel: «Hva er serverspecene for Prosjekt X?» – der systemet først må finne en server-ID ett sted, og deretter slå opp detaljene et annet sted. Standard RAG stopper etter første treff.
Er 34% faktaforbedring realistisk å forvente i produksjon?
Tallet er målt på FramesQA-benchmarken med 824 spørsmål og 2676 PDF-dokumenter. Resultater fra benchmarks treffer ikke alltid likt i produksjon med bedriftens egne data, men retningen er klar: iterativ søking gir bedre grunnlag enn enkelt-treff.








1 kommentar