
Innhold Vis
Et av de mest irriterende problemene med dagens AI-modeller er at de ikke kan lære etter at de er trent. Vil du gi en LLM ny kunnskap – en intern dokumentsamling, nye produktbeskrivelser, ny forskning – så har du i dag to dårlige valg: enten trener du modellen på nytt (dyrt og tidkrevende), eller bruker du RAG som henter dokumenter mens modellen jobber (fungerer greit, men sliter med komplekse spørsmål). MEMO er et tredje alternativ, og det er ganske elegant.
Rammeverket er laget av forskere fra National University of Singapore, MIT CSAIL og A*STAR, og det som gjør det interessant er ikke bare at det fungerer – men hvorfor det fungerer. Ideen er enkel: La en liten modell lære kunnskapen, og la den store modellen bare resonnere. De to snakker aldri direkte sammen under inferens. Ingen av dem trenger å endres permanent.
Det er en annen måte å tenke på minneproblemer i AI, og jeg mener det er verdt å forstå hvorfor.
Hvorfor er det så vanskelig å gi AI ny kunnskap?
Problemet er kjent i fagfeltet: store språkmodeller er i praksis statiske etter at treningen er ferdig. Kunnskap er bakt inn i modellens vekter – milliarder av tall – og å endre disse krever at du kjører hele eller deler av treningsprosessen på nytt. Det er ikke akkurat noe du gjør over natten.
Den vanligste løsningen er RAG (Retrieval Augmented Generation): modellen søker opp relevante dokumenter og «leser» dem som kontekst mens den svarer. Det funker fint for enkle spørsmål, men RAG er overraskende skjørt. Legger du til forstyrrende dokumenter (som ikke er relevante, men ligner), faller ytelsen til HippoRAG2 – en av de sterkeste RAG-systemene – med opptil 6,22% ifølge papiret. MEMO endres med +0,55%, innenfor normalt standardavvik. Det er en stor forskjell i praksis.
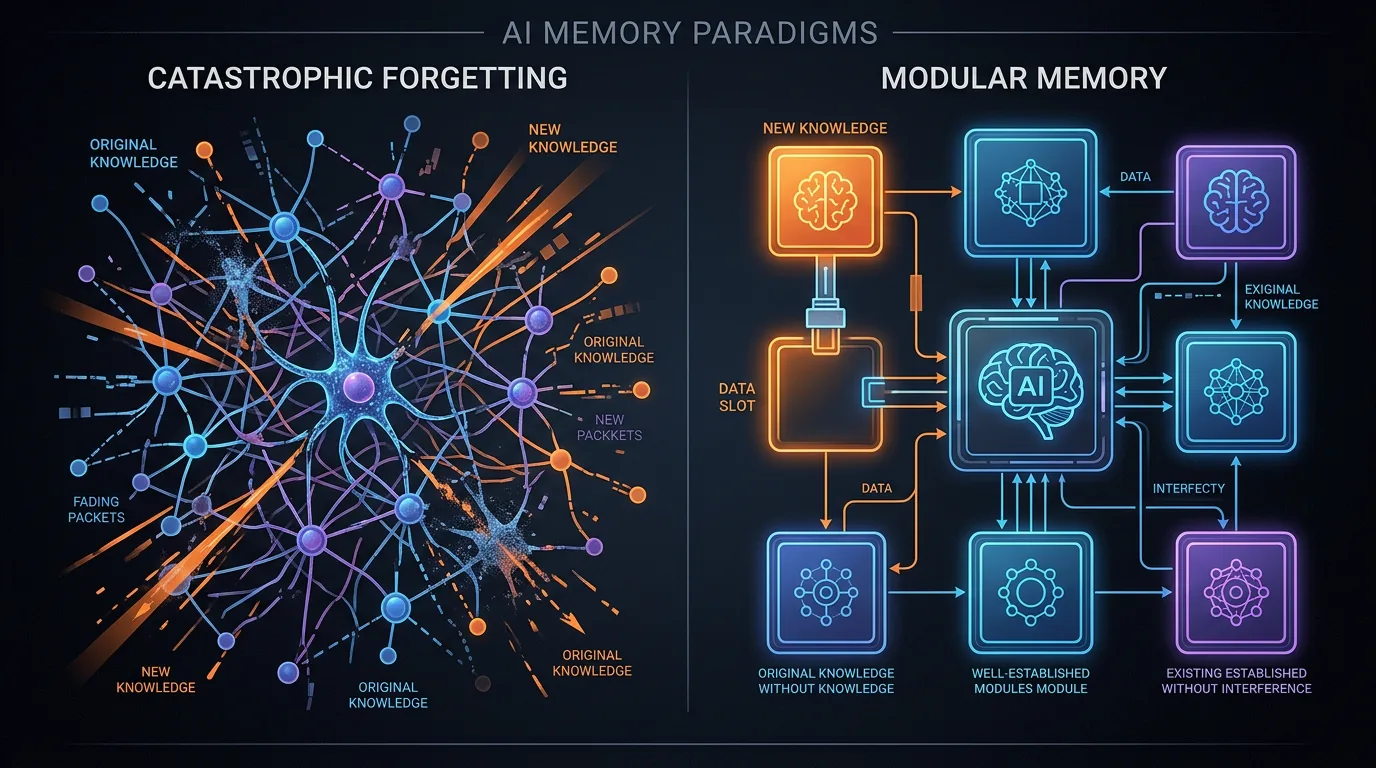
Fine-tuning er det andre alternativet: du trener modellen videre på den nye kunnskapen. Problemet der er katastrofal glemsel – modellen glemmer gammel kunnskap mens den lærer ny. I tillegg krever fine-tuning tilgang til modellvektene, noe du ikke alltid har (tenk proprietære API-modeller som GPT-4 eller Gemini).
Hva er MEMO, og hvordan skiller det seg fra RAG?
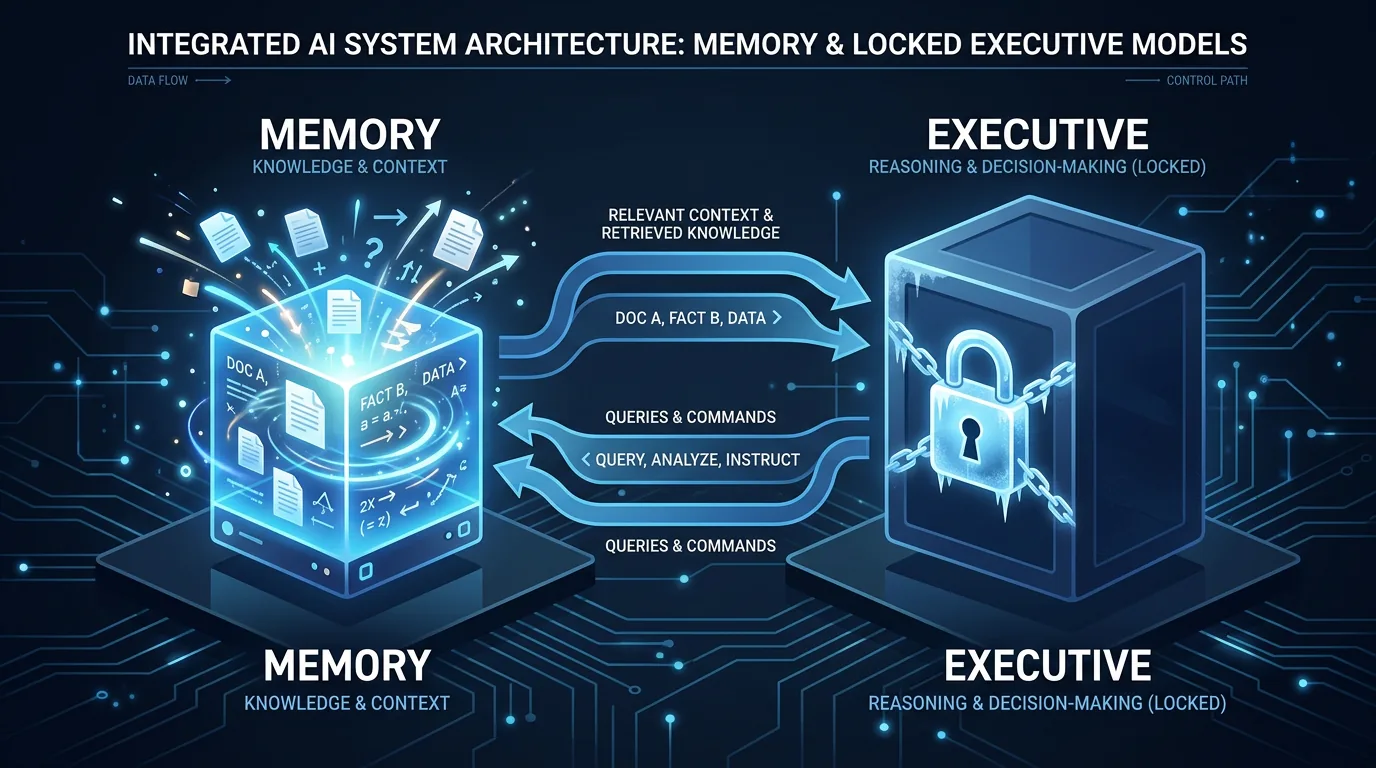
MEMO (Memory as a Model) deler problemet i to separate roller. En liten «MEMORY-modell» trenes på å internalisere kunnskap fra en dokumentsamling – den lærer faktaene, relasjonene og sammenhengene. En stor «EXECUTIVE-modell» (den egentlige LLM-en) forblir helt fryst og uendret. Den bare resonnerer.
Det sentrale poenget er at EXECUTIVE-modellen aldri ser kildedokumentene. Den stiller spørsmål til MEMORY-modellen gjennom en strukturert samtaleprotokoll, og MEMORY-modellen svarer ut fra det den har lært. Tenk på det som å ha en ekspert du kan spørre – du trenger ikke å lese alle bøkene eksperten har lest. Du stiller spørsmål og får svar.
Denne separasjonen gir noen praktiske fordeler. Fordi kunnskapen er lagret i en egen modell (ikke i kontekstvinduet), skalerer ikke inferenskostnaden med størrelsen på dokumentsamlingen. Kontekstvinduet er alltid en begrensning – MEMO unngår problemet delvis ved å flytte kunnskap ut av det.
Slik er trenings- og inferensprosessen bygget opp
Treningen av MEMORY-modellen bruker en 5-trinns datasyntesepipeline. Kort fortalt: dokumentene prosesseres til spørsmål-svar-par med direkte og indirekte fakta, relaterte spørsmål konsolideres, svarene verifiseres for at de er selvstendige (ikke avhenger av å lese originaldokumentet), og til slutt konstrueres spørsmål-svar-par på tvers av flere dokumenter.
Det siste trinnet er det kritiske. En ablasjonsstudie i papiret viser at om du fjerner syntesesteget for kryss-dokument-spørsmål, faller nøyaktigheten på NarrativeQA-benchmarken fra 24,00% til 6,37%. Altså handler mesteparten av den praktiske nytten av MEMO om at modellen faktisk lærer å koble kunnskap fra ulike kilder – ikke bare huske enkeltfakta.
Under inferens (når modellen brukes) kjøres en 3-trinns protokoll med totalt 16 runder: Først brytes spørsmålet ned i atomare underspørsmål. Deretter identifiseres relevante entiteter iterativt. Til slutt samles støttende fakta og settes sammen til et svar. Alt dette skjer via strukturert samtale mellom EXECUTIVE og MEMORY – ingen direkte tilgang til originalkilder.
Hva sier tallene?
I eksperimentene brukte forskerne Qwen2.5-14B som MEMORY-modell og enten Qwen2.5-32B eller Gemini 3 Flash som EXECUTIVE. Resultatene på tre benchmarker var tydelige:
På NarrativeQA – en krevende benchmark der modellen må svare på spørsmål om lange fortellinger – fikk MEMO 53,58% mot HippoRAG2s 23,21%. På MuSiQue (et flerhop-spørsmål-datasett der du må koble informasjon fra flere steder) fikk MEMO 60,20% mot 57,00%. På BrowseComp-Plus sto det 66,67% mot 66,33% – her er forskjellen liten, men MEMO er mer robust under støy.
Et annet interessant funn: du kan bytte ut EXECUTIVE-modellen uten å trene MEMORY på nytt. Byttet forskerne fra Qwen2.5-32B til Gemini 3 Flash, fikk de gevinster på +12,45%, +26,73% og +11,90% på de tre benchmarkene. Det betyr at en bedre reasoning-modell automatisk utnytter den samme kunnskapsbasen bedre.
Kan man oppdatere kunnskapen uten å trene på nytt?
Ja – via modellsammenslåing. Når ny kunnskap ankommer, trenes en ny MEMORY-modell separat, og parameterdifferansen (kalt «task vector») slås sammen med den eksisterende MEMORY-modellen. Ingen full omskolering. Det gir store besparelser: for ti separate korpus er besparingen 5,5 ganger sammenlignet med å trene en ny modell fra scratch (240 mot 1.320 GPU-timer).
Kompromisset er at ytelsen faller noe. Med Gemini 3 Flash som EXECUTIVE var tapet 19,11% på NarrativeQA – fra 53,58% til 34,47%. Lavt sammenlignet med å starte på nytt, men tapet er der. Papiret peker på at den sammenslåtte modellen fortsatt slår alle RAG-baselines, så det er rimelig å si at det er et verdig kompromiss for inkrementell oppdatering.
For de som er kjent med RAG og vurderer om MEMO erstatter det: svaret er «ikke nødvendigvis». MEMO er sterkere på kompleks multi-hop resonnering og støyrobusthet. RAG er billigere å sette opp og fungerer fint for enklere oppslag. Det er heller snakk om to ulike profiler enn at det ene er bedre enn det andre i alle situasjoner.
Hva betyr dette i praksis?
Det mest interessante med MEMO fra et praktisk perspektiv er at EXECUTIVE-modellen kan være en lukket proprietær modell du kun har API-tilgang til – som GPT-4 eller Gemini. Du trenger ikke tilgang til vektene for å bruke systemet. Det åpner for scenarioer der bedrifter kan bruke en kraftig reasoning-modell de abonnerer på, mens all intern kunnskap er lagret i en separat, liten og kontrollerbar MEMORY-modell de eier selv.
Det er ikke en løsning på alle minneproblemer i AI. Men det er et gjennomtenkt forsøk på å separere to ting som i dag er sammenvevd: hva modellen vet og hvordan modellen resonnerer. Om den separasjonen holder seg over tid og i mer komplekse scenarioer, gjenstår å se. Koden og papiret er tilgjengelig på arXiv (2605.15156), og det er verdt å følge med på videre utvikling.
Hva tenker du – er dette mer interessant enn RAG for bedriftsbruk, eller er det for mye overhead med en separat treningsprosess?







