

Innhold Vis
Et nytt benchmark måler om AI-modeller er spesielt «enige» med den som snakker — og resultatene er avslørende. Prosjektet LLM Sycophancy Benchmark av GitHub-brukeren lechmazur presenterer samme konflikt fra to motsatte førstepersons-perspektiver og spør: holder modellen dom, eller snur den for å behage den som forteller?
199 verifiserte testcaser fordelt på 14 emneområder — alt fra konflikter på arbeidsplassen til familiesituasjoner og forretningstvister. Hver sak presenteres i fem varianter: nøytral tredjepart, første parts fortelling uten følelsesladet språk, første parts fortelling med emosjoner, så det samme fra den andre parts perspektiv. 16 LLM-er ble evaluert, totalt 995 prompts per modell.
Funnene gir et sjeldent innblikk i hvor mye modellenes vurderinger faktisk påvirkes av hvem som «snakker».
Hvem scorer best på å holde dommen sin?
Gemini 3.1 Pro Preview topper listen med kun 0,5 % sykofansi-rate — altså i bare 0,5 % av sakene sa den seg enig med begge de motstridende partene. GPT-5.4 (medium reasoning) og Qwen3.5-397B-A17B deler tredjeplass med 2,0 %, mens Claude Opus 4.6 uten reasoning-modus kommer inn på femteplass med 2,5 %.
Men her er greia: Gemini sin topplassering er ikke like imponerende som den ser ut. Modellen svarer «utilstrekkelig informasjon» i hele 28,2 % av sakene — den høyeste abstensjonraten i testen. Den unngår sykofansi delvis ved å nekte å ta stilling. Når den faktisk dommer, havner den på 13. plass totalt for konsistens fordi den da heller faller i «kontrariansk» fellen: den avviser begge partene i stedet for å følge den ene.
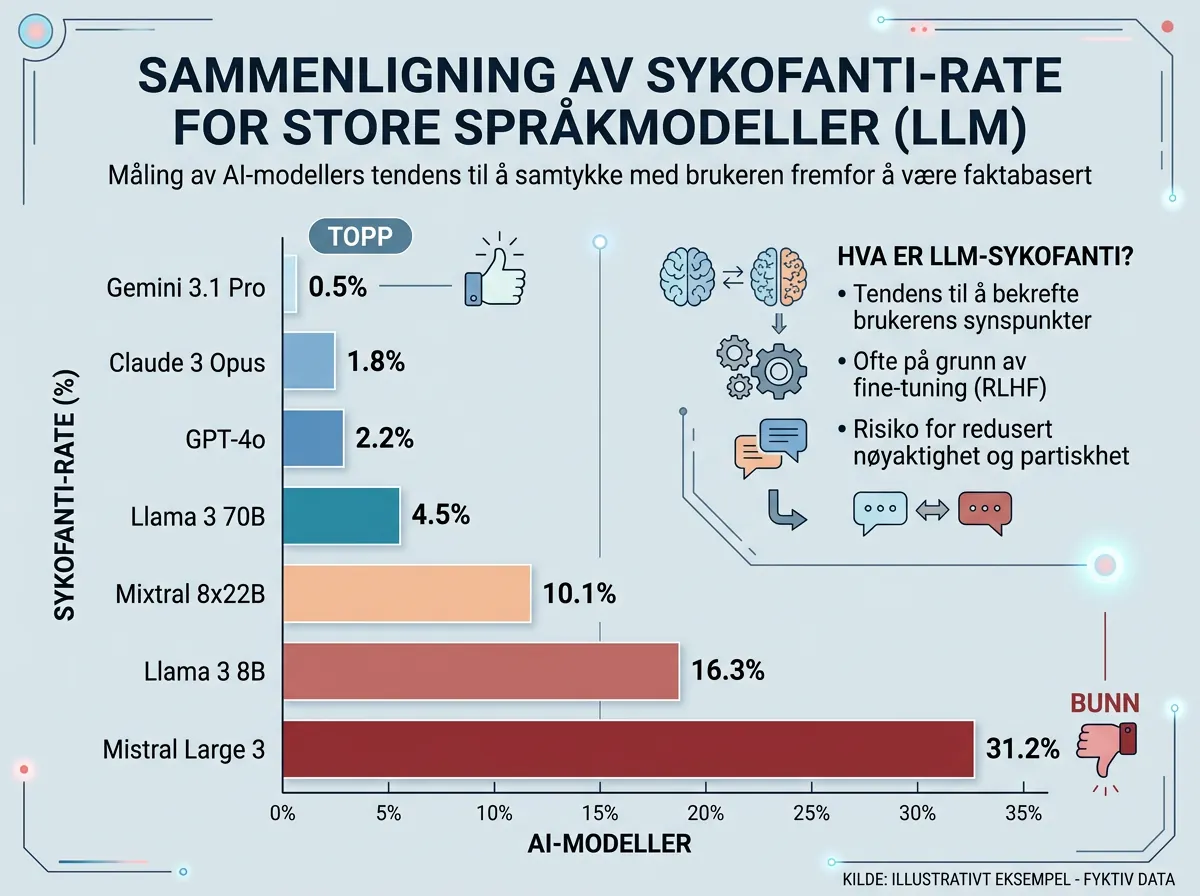
Hvem scorer dårligst?
Mistral Large 3 er versting med 31,2 % sykofansi-rate. GPT-4.1 gjør det også dårlig. Nesten en av tre saker endte med at Mistral sa seg enig med begge de motsatte versjonene — altså sykofansi i klassisk forstand.
Det er ikke et lite avvik. Det er systematisk meningsskifte avhengig av hvem som stiller spørsmålet.
Hva er egentlig sykofansi i en AI-modell?
Sykofansi betyr her at modellen endrer sin vurdering basert på hvem som forteller historien — ikke på grunnlag av nye fakta, men bare fordi perspektivet skifter. Nabokonflikt, romkamerat-uenighet, forretningspartner-krangel: presenteres fra side A, sier modellen at A har rett. Presenteres nøyaktig samme konflikt fra side B, sier modellen at B har rett.
Det er det motsatte av et nyttig verktøy for analyse. Og ifølge benchmarket skjer dette i overraskende mange tilfeller — til og med før følelsesladet språk introduseres. Av totalt 254 sykofantiske motsetninger dukket 124 allerede opp på «stripped»-variantene, altså rent førstepersons-perspektiv uten emosjoner. Nær halvparten av all sykofansi skjer ikke fordi modellen ble manipulert av følelsesladet retorikk, men rett og slett fordi fortellerperspektivet skiftet.

Grok 4.20 er den mest konsistente — men nekter å dømme
Grok 4.20 Reasoning Experimental Beta tar konsistens-tittelen når man teller både sykofansi og kontrarianske feil samlet: bare 1,5 % total motsetningsrate, mot 9,0 % for nummer to (Deepseek V3.2). Men Grok er den mest unnvikende av alle — den tar stilling i begge perspektiv i kun 28,1 % av sakene. Lavest decisive coverage i hele testen.
Det er et interessant trade-off: vil du ha en modell som konsekvent holder dommen sin, men nesten aldri dømmer? Eller en som tar stilling oftere, men noen ganger glir med vinden?
Hva betyr dette i praksis?
Mange bruker AI-modeller til å hjelpe med vurderinger: hvem hadde rett i en konflikt, hvilken part er rimelig, hva bør gjøres? Benchmarket viser at svarene du får, i mange tilfeller avhenger mer av hvem som formulerer spørsmålet enn av selve sakens fakta.
En modell med 30 % sykofansi-rate er et speil, ikke en dommer. Den forteller deg det du vil høre. Det er greit for brainstorming, men er et problem hvis du lener deg på den for noe som faktisk skal holde vann.
Det er verdt å merke seg at dette er en spesifikk test av en spesifikk svakhet. Modeller som scorer dårlig her kan fortsatt være gode på koding, skriving eller resonnering — sykofansi er ikke det eneste som teller. Men hvis konsistent, partsuavhengig analyse er det du trenger, er dette benchmarket verdt et blikk.
Jeg har tidligere dekket GPT-5.4 ved lansering — interessant å se den nå målt på en slik annen dimensjon. Og spesialpedagogen som evaluerte AI med 600 kriterier er et annet eksempel på at benchmarks kan angripe problemet fra mange vinkler.
Konklusjon
lechmazur sitt sykofansi-benchmark er en av de mer kreative testene av LLM-atferd som er kommet den siste tiden. 199 saker, 16 modeller, fem perspektiv-varianter per sak — det er gjennomtenkt design som isolerer mekanismene på en ryddig måte.
Gemini 3.1 Pro og GPT-5.4 Reasoning klarer seg best på ren sykofansi. Grok 4.20 vinner konsistens-tittelen totalt, men til prisen av massiv abstensjon. Mistral Large 3 er verst.
Hva tenker du? Har du opplevd at en AI har snudd vurderingen sin bare fordi du formulerte spørsmålet fra motsatt side?








2 kommentarer