

Innhold Vis
Needle er en 26 millioner parameter modell som kjører tool calling raskere enn du rekker å blunke. Cactus Compute har open-sourcet den under MIT-lisens, og det er nettopp den typen utvikling som gjør AI-feltet genuint spennende: ikke en ny kjempemodell som krever et serverrom, men en liten spesialist som passer i lomma di.
Premisset bak Needle er enkelt og genialt. Agentic AI handler i bunn og grunn om tool calling – at modellen matcher en bruker-forespørsel mot riktig verktøy, trekker ut argumentverdier og spytter ut JSON. Det er ikke dyp resonnering. Det er henting og montering. Og for det trenger du ikke 70 milliarder parametere.
Cactus Compute destillerte Gemini 3.1s tool calling-evner ned i en bitteliten «Simple Attention Network». Resultatet: 6 000 tokens per sekund under prefill og 1 200 tokens per sekund under decode – på vanlig forbrukerhardware. Telefoner, smartklokker, AR-briller. Alt som tidligere krevde en skytilkobling kan nå skje direkte på enheten.
Hva er egentlig Needle?
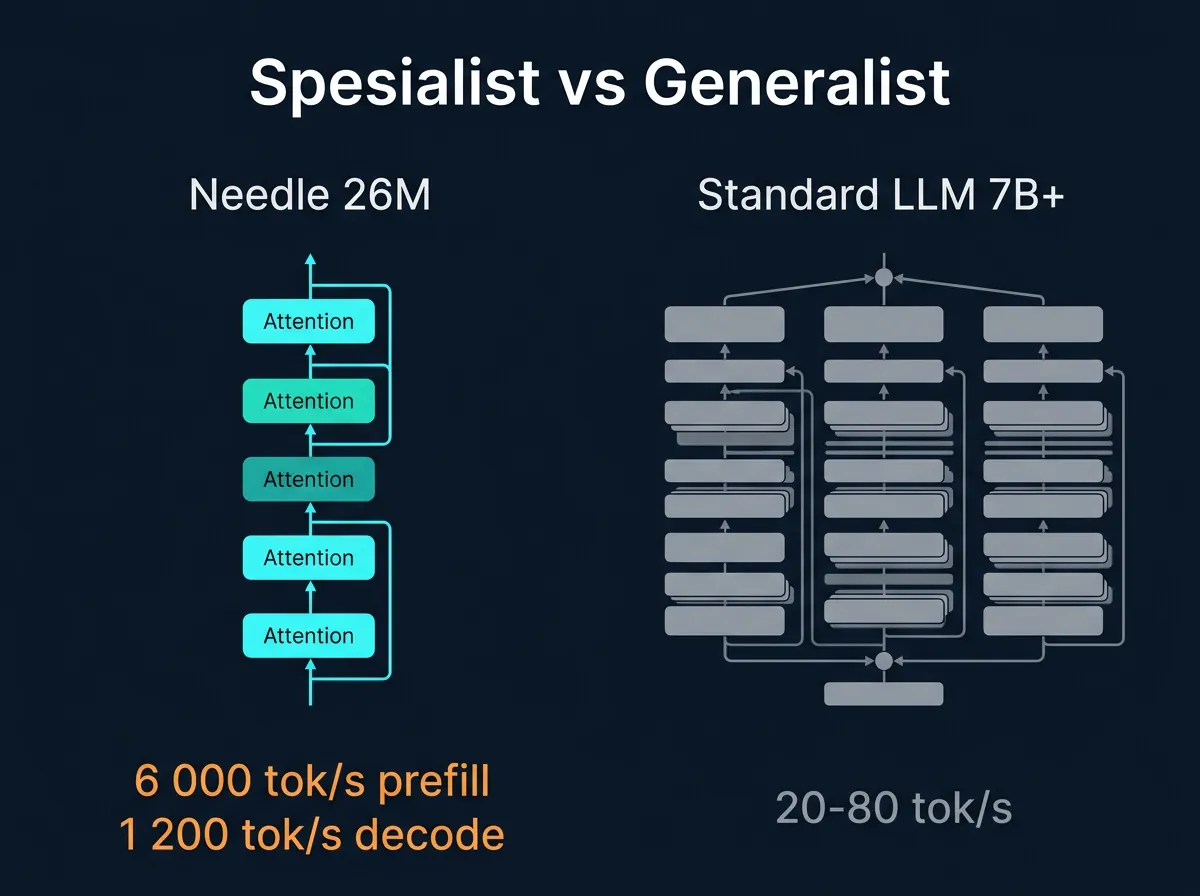
Needle er ikke en generell språkmodell. Den er trent for én ting: function calling. Arkitekturen er bevisst slanket – 512 embedding-dimensjoner, 8 attention-hoder med 4 key-value-hoder (grouped query attention), 12 encoder-lag og 8 decoder-lag. Det som er kuttet vekk er feed-forward-nettverkene i encoder-delen – de MLPene som gjerne spiser mest minne og regnekapasitet.
Treningsprosessen er interessant. Modellen ble fortrenet på 200 milliarder tokens over 27 timer på 16 TPU v6e-enheter. Deretter 45 minutter med 2 milliarder syntetiserte function-call-eksempler generert via Gemini. Det er den siste biten som gjør modellen god på akkurat denne oppgaven – og det forklarer tittelen «We Distilled Gemini Tool Calling Into a 26M Model».
MIT-lisens betyr at du kan bruke den kommersielt, bygge på den og distribuere den som du vil. Vektene ligger på Hugging Face under Cactus-Compute, og koden er tilgjengelig på GitHub.
Hvor rask er den egentlig?
6 000 tokens per sekund prefill og 1 200 tokens per sekund decode er tall som faktisk betyr noe. For context: de fleste lokale modeller på en vanlig bærbar datamaskin opererer i området 20-80 tokens per sekund under decode. Needle er i en helt annen liga – til tross for at den gjør noe smalere.
Det er selvsagt ikke tilfeldig. Med 26 millioner parametere er modellen liten nok til å passe i CPU-cache på mange enheter. Jo mindre modellen er, jo mer av vektene kan holdes i rask cache fremfor å hentes fra RAM. Det er en av de grunnleggende fysiske realitetene bak inference-hastighet.
Sammenligner du med alternativene den er testet mot – FunctionGemma-270M, Qwen-0.6B og Granite-350M – slår Needle alle tre på single-shot function calling. Det er 10x, 20x, og 13x større modeller henholdsvis. De er bedre på konversasjonsoppgaver, det er åpenbart. Men hvis tool calling er det du trenger, er Needle et rimelig åpenbart valg.
Hva bruker du Needle til?
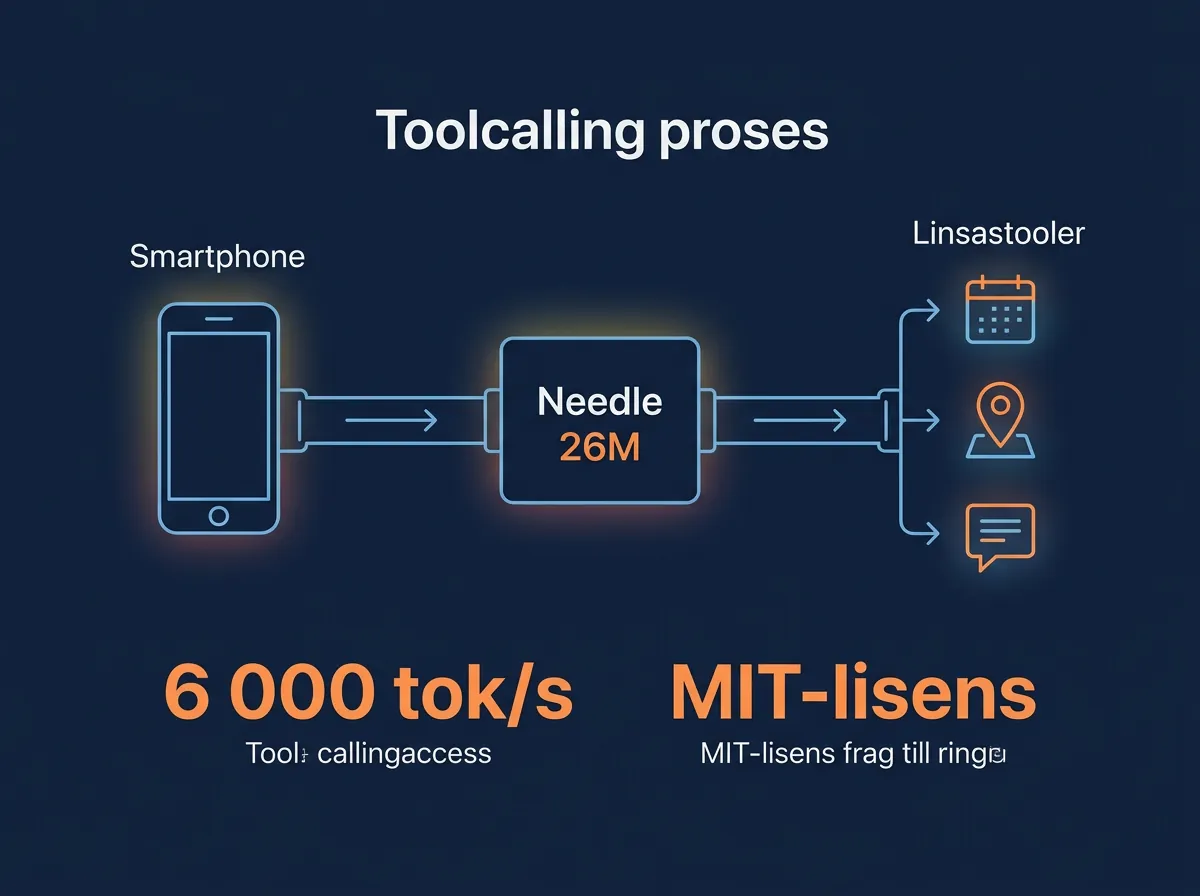
Tool calling er ryggraden i agentic AI. Når du ber en AI-assistent om å «sett alarm på 07:30», «send en melding til mamma» eller «søk etter nærmeste kafé», er det tool calling som skjer bak kulissene. Modellen matcher intensjonen din mot et verktøy, trekker ut parametrene og kjører funksjonen.
Det er dette Needle gjør – og ingenting annet. Den vet ikke hva Aristoteles mente om etikk. Den kan ikke skrive et dikt. Men den kan prosessere hundrevis av tool-calls i sekundet på en Android-telefon, noe ingen annen åpen modell klarer i nærheten av.
Praktisk sett åpner dette for AI-agenter som kjører helt lokalt. Ingen API-kall til skyen, ingen latency fra nettverkshop, ingen abonnementskostnader per request. Tenk på det som en liten, rask dispatcher – den tar imot kommandoen din, finner riktig verktøy, og iverksetter. Alt på enheten din.
Jeg har tidligere skrevet om Anthropics eksperimenter med programmatic tool calling der de forsøker å erstatte tradisjonell JSON-basert tool calling med Python-baserte løsninger. Tilnærmingene er forskjellige, men begge peker mot det samme: tool calling er en egen disiplin som fortjener spesialiserte løsninger, ikke bare en bieffekt av å gjøre en stor generell modell enda større.
Slik kommer du i gang
Cactus Compute har gjort oppsettet enkelt. Du kloner repoet, kjører setup-scriptet og starter playground-grensesnittet:
git clone https://github.com/cactus-compute/needle.git
cd needle && source ./setup
needle playgroundDette starter en web-UI på localhost:7860 der du kan teste modellen mot dine egne verktøy. Det finnes også CLI-kommandoer for inference, trening, evaluering og datasyntetisering. Du kan med andre ord finjustere Needle på dine egne function-call-eksempler direkte på en vanlig Mac eller PC – treningsdatasettet er open-sourcet og prosessen er dokumentert i repoet.
Det er en ganske lav terskel. Du trenger ikke å lære noe nytt rammeverk, og du trenger ikke en kraftig GPU for å eksperimentere. Treningskjøringen tok 45 minutter på industriell TPU-hardware, men finjustering på et lite, domenespesifikt datasett er en annen sak.
Hva betyr dette for lokal AI?
Needle representerer noe jeg synes er verdt å merke seg: spesialisering fremfor generalisering. Feltet har lenge hatt et nærmest religiøst fokus på å gjøre store modeller som kan gjøre alt. Needle er en motbevegelse – en modell som er genuint god på én ting, og som er liten nok til å kjøre hvor som helst.
Det minner om Gemini Embedding 2, som heller ikke er ment å «snakke» men å forstå semantisk likhet på tvers av modaliteter. Spesialistmodeller med en klar jobb er en trend som gir mening – og Needle er et godt eksempel på hva som er mulig når du snevrer inn problemet nok.
526 GitHub-stjerner etter lansering og et engasjert LocalLLaMA-community indikerer at det er interesse der ute. Neste steg for Cactus Compute vil antakelig være å vise Needle i action i en faktisk agentic pipeline på en ekte enhet. Det er her beviset må komme – ikke bare tokens per sekund, men faktisk bruk i virkelige apper.
Hva tenker du? Er det rom for 26M-modeller i din AI-stack, eller er du av dem som mener en modell enten er stor nok til å gjøre alt, eller ikke verdt bryet? Jeg er genuint nysgjerrig på om noen faktisk tester dette i produksjon.







