

Innhold Vis
Google lanserte Gemini Embedding 2 den 10. mars 2026 — og det er den første nativt multimodale embedding-modellen i markedet. Den plasserer tekst, bilder, video, lyd og PDF-er i ett felles vektorrom. Det høres kanskje abstrakt ut, men for alle som jobber med RAG er dette faktisk en stor deal.
Jeg bruker Gemini embeddings i egne RAG-systemer og har fulgt denne modell-serien tett. Da jeg så lanseringen tirsdag var reaksjonen min omtrent: «Ja. Endelig.» Ikke fordi det er perfekt — det finnes rimelige tekstalternativer — men fordi multimodal RAG til nå har vært et håpløst lappeteppe av separate modeller, ekstra API-kall og manuell koordinering. Gemini Embedding 2 kutter gjennom det.
I denne artikkelen går jeg gjennom hva modellen faktisk kan, tekniske spesifikasjoner som betyr noe i praksis, og når du bør (og ikke bør) velge den fremfor alternativer.
Hva er egentlig en embedding-modell?
Embedding-modeller er ikke chatbots. De er «oversettere» som konverterer innhold — tekst, bilder, lyd — til tall-vektorer. En vektor for «katt» vil ligge nær vektoren for «kattunge» i rommet, langt fra «regjeringen». Dette er grunnmuren i alle RAG-systemer (Retrieval Augmented Generation): systemet søker ikke etter eksakte ord, men etter semantisk mening.
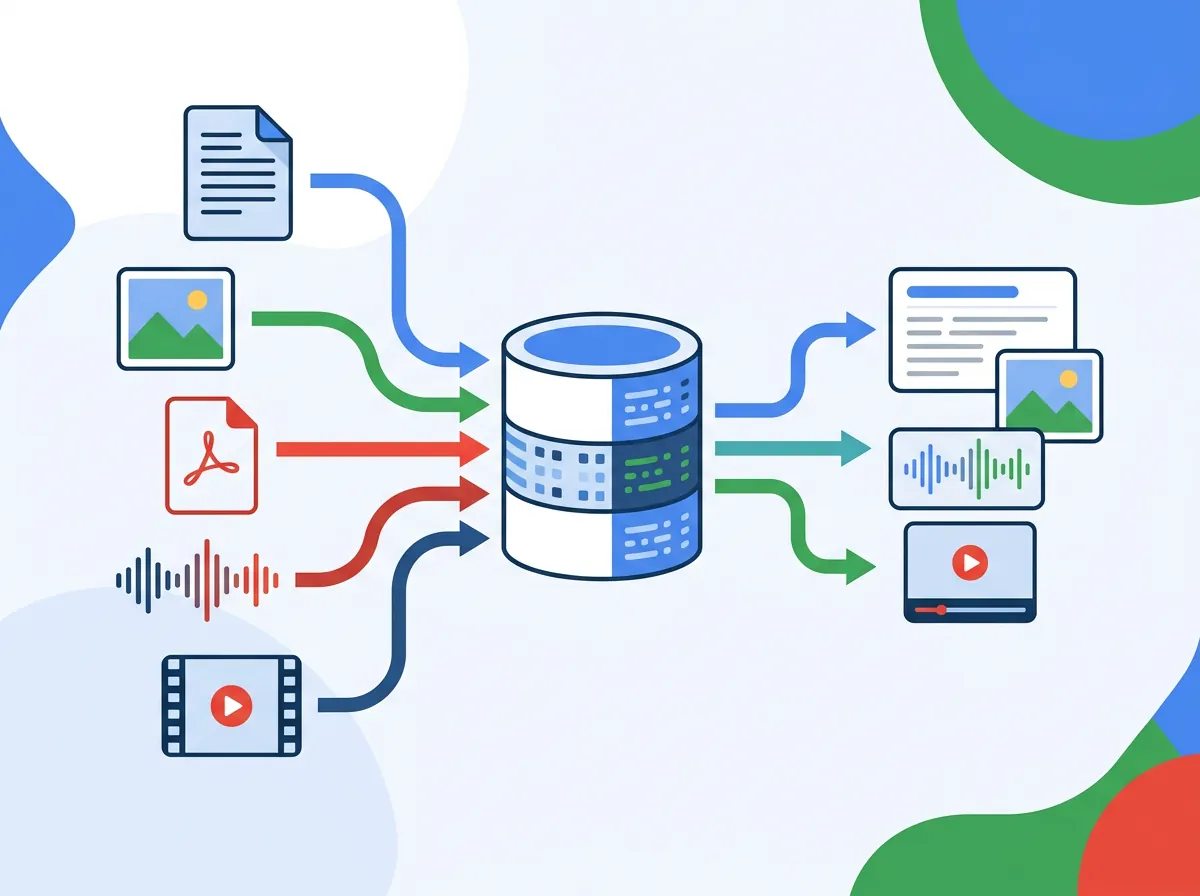
Spørsmålet Gemini Embedding 2 besvarer er: hva skjer når du ikke bare vil søke i tekst, men i bilder, videoer og PDF-filer med grafer — alt på én gang? Til nå har svaret vært: bruk fire forskjellige modeller, koordiner resultater manuelt, og lur deg selv til å tro at det er en pipeline. Med Gemini Embedding 2 er alle fem modaliteter i én felles modell.

Tekniske detaljer som faktisk betyr noe
La meg gå rett på det som er praktisk relevant, ikke bare imponerende på papiret.
Kontekstvindu på 8 192 tokens — det er fire ganger Gemini Embedding 001 (2 048 tokens). I praksis betyr det at du kan sende lengre dokumentchunks uten å dele dem opp, noe som bevarer kontekst og forbedrer søkekvalitet. OpenAI text-embedding-3-large har samme grense, så dette er paritet der — men multimodaliteten er ikke sammenlignbar.
MRL — Matryoshka Representation Learning er en teknikk som lar deg trimme vektordimensjonene ned fra standard 3 072 uten dramatisk tap i søkekvalitet. Praktisk implikasjon: 1 536 dimensjoner gir deg 99,9% av ytelsen på halvparten av lagringsplassen i vektordatabasen. Det er et enkelt valg for de fleste RAG-prosjekter.
Input per request: 6 bilder, 120 sekunder video (uten lyd) eller 80 sekunder med lyd, 80 sekunder lyd alene, 6 PDF-sider og 8 192 tokens tekst. Ikke ubegrenset, men mer enn nok for typiske dokumentarchunks.
MTEB-score — #1 blant kommersielle API-modeller?
Ifølge Googles offisielle lanseringsblogg scorer Gemini Embedding 2 68,17 på MTEB (Massive Text Embedding Benchmark) — bransjens standard for embedding-ytelse. Det plasserer den blant toppen av kommersielle API-løsninger, nest etter Gemini Embedding 001 (68,32).
For sammenligning:
- OpenAI text-embedding-3-large: 64,60
- Cohere Embed v4: 65,20
- Voyage-3-large: 66,80
- Gemini Embedding 2: 68,17
Men her er det viktig å presisere: open source-modeller som NV-Embed-v2 og Qwen3-Embedding-8B scorer høyere på enkeltbenchmarks. Forskjellen er at de krever egen hosting. For deg som vil ha en API du bare kaller og ikke vil drifte noe selv, er Gemini Embedding 2 det sterkeste alternativet per mars 2026.
Hva er multimodal RAG — og hvorfor er det viktig?
Klassisk RAG er genialt, men det håndterer bare tekst. Problemet er at virkelig nyttig bedriftsinformasjon sjelden er ren tekst. Det er PDF-er med grafer, tekniske håndbøker med bilder, opplæringsvideoer, taleopptak fra møter.
Inntil nå har du hatt to alternativer: ignorer alt som ikke er tekst (taper informasjon), eller bruk separate modeller for hvert format og sys dem manuelt sammen (tidkrevende, skjørt, dyrt). Gemini Embedding 2 gjør noe annet: den legger alle modaliteter inn i det samme vektorrommet. Det betyr at en tekstspørring kan matche et bilde, et videoklipp kan matche en PDF-side, og alt dette skjer i én søkeoperasjon.
Konkrete eksempler på hva dette åpner for:
- Tekniske håndbøker: En ingeniør stiller et spørsmål om en maskinkomponent → systemet matcher mot både tekstbeskrivelse og produktbilder i håndboken
- PDF-søk: Søk i årsrapporter, regnskapsdokumenter og tekniske manualer med grafer og tabeller — ikke bare tekstblokker
- Lyd-til-dokument: Taleopptak fra kundeservice kan matches mot skriftlig dokumentasjon uten mellomsteg for transkripsjon
- Videosøk: Søk i opplæringsvideoer basert på semantisk innhold
Greia er at dette ikke bare er kul demo-teknologi. Det er den første gangen disse brukstilfellene har en enkel, API-basert løsning uten kompleks koordinering.
Flerspråklig support — relevant for norsk dokumentasjon
Modellen er trent på over 100 språk og bruker ett felles semantisk rom for alle. Det betyr i praksis at en norsk spørring kan matche engelsk dokumentasjon — uten eksplisitt oversettelse i pipelinen.
Det er mer relevant enn det høres ut. Mange bedrifter har interne dokumenter på norsk og leverandørdokumentasjon på engelsk. Med tidligere embedding-modeller var dette et reelt problem: du måtte enten oversette alt, bygge separate indekser, eller akseptere dårlig søkekvalitet på tvers av språk. Gemini Embedding 2 håndterer dette nativt.
Hva koster Gemini Embedding 2?
Standard API: $0,20 per million tokens ifølge Googles offisielle prisliste. Batch API (ikke tidskritisk): $0,10 per million tokens — halvparten av prisen for batch-indeksering av store dokumentarkiver.
For ren tekst-RAG er Gemini Embedding 001 fremdeles et fornuftig valg: litt bedre MTEB-score, lavere pris, og Generally Available (ikke Preview). Gemini Embedding 2 er riktig valg når du trenger multimodal støtte eller det lengre kontekstvinduet på 8 192 tokens.
OpenAI text-embedding-3-small koster $0,02 — altså 10 ganger billigere. Men den er tekstbasert, og kontekstvinduet er ikke i nærheten. Det er en avveining: for enkle ren-tekst-systemer er OpenAI small klar prisvinner. For alt som involverer bilder, PDF eller lyd er det ikke en reel konkurrent.
GDPR og Vertex AI — viktig presisering
Google AI Studio er gratis og bra for prototyping, men data behandles i USA. For sensitive forretningsdata holder ikke det.
Vertex AI støtter EU-regioner (europe-west1, europe-west4), noe som gjør Gemini Embedding 2 brukbart for GDPR-sensitive brukstilfeller. Hvis du jobber med persondata eller konfidensiell bedriftsinformasjon: bruk Vertex AI med EU-region, ikke Google AI Studio. Alternativet er open source-modeller som kjøres lokalt — da forlater dataene aldri maskinen din.
Slik kommer du i gang
For prototyping via Google AI Studio er det rett frem:
pip install google-generativeaiimport google.generativeai as genai
genai.configure(api_key="DIN_API_NØKKEL")
result = genai.embed_content(
model="models/gemini-embedding-2-preview",
content="Hva er best praksis for dokumenthåndtering?",
task_type="RETRIEVAL_QUERY",
output_dimensionality=1536
)
print(result['embedding']) # Liste med 1536 tall1 536 dimensjoner er anbefalingen for de fleste RAG-prosjekter — du beholder 99,9% av ytelsen til halvparten av lagringskostnaden i vektordatabasen.
Viktig: embedding-rommet fra Gemini Embedding 001 og Gemini Embedding 2 er inkompatible. Migrerer du, må all eksisterende data re-embeddes. Det er litt jobb, men for de fleste prosjekter verdt det.
Hvis du vil se mer om hva du kan bygge med n8n og automatisering, sjekk ut artikkelen om community nodes i n8n. For bakgrunn på Gemini-modellserien generelt har jeg dekket Gemini 3.1 Pro og Gemini i hverdagen tidligere.
Konklusjon — når bør du velge Gemini Embedding 2?
Velg Gemini Embedding 2 hvis:
- Du bygger RAG-systemer som skal håndtere bilder, PDF, lyd eller video
- Du har blandet norsk/engelsk dokumentasjon og vil unngå oversettingssteg
- Du trenger det lengre kontekstvinduet (8 192 tokens)
- Du vil slippe å koordinere separate modeller for forskjellige modaliteter
Hold deg til Gemini Embedding 001 (eller OpenAI text-embedding-3-small) hvis du bare jobber med ren tekst og vil ha laveste mulige pris.
Modellen er i Public Preview, API-navn gemini-embedding-2-preview, tilgjengelig via Google AI Studio og Vertex AI. For alle som jobber seriøst med RAG er den verdt å teste — og for multimodal RAG er det rett og slett ikke noe annet kommersielt alternativ per i dag.








1 kommentar