

Innhold Vis
Stability AI har sluppet Stable Audio 3 – en ny familie tekst-til-lyd-modeller med open weights og lokal kjøring på vanlig forbrukerhardware. Tre modeller ble lansert samtidig: Small Music, Small SFX og et Medium-alternativ – alle tilgjengelig på HuggingFace fra dag én.
Dette er ikke bare en ny versjon av det samme. Stable Audio 3 er bygget fra bunnen med en ny arkitektur, og det merkes. Small-modellen klarer 120 sekunder lyd på under 6 sekunder på CPU. Det er raskt nok til at det faktisk fungerer i praksis, ikke bare i pressemeldinger.
Stability AI er selskapet som begynte open source-bølgen for bildemodeller med Stable Diffusion tilbake i 2022. At de nå gjør det samme for lyd – med LoRA-støtte og et dedikert GitHub-repo for finjustering – er akkurat det fellesskapet trenger nå som Suno og Udio lukker seg mer og mer mot betalingsmodeller.
Hva er Stable Audio 3?
Stable Audio 3 er en familie latent diffusion-modeller for lydgenerering. Til forskjell fra de to foregående versjonene er arkitekturen nå transformer-basert, med T5Gemma som tekstkoder. Det gir modellen bedre forståelse av komplekse tekstprompts – beskrivelser som «house music, 124 BPM, festival-stemning, sol og venner» oversettes mer presist til faktisk lyd enn det tidligere var mulig med eldre encoder-arkitekturer.
Modellene er trent på 1,27 millioner lydopptak – en blanding av lisensiert materiale fra AudioSparx og Creative Commons-innhold fra Freesound. Alt copyrightbeskyttet innhold er fjernet med PANNs-tagger før trening, noe som er viktig for den juridiske situasjonen rundt bruk av generert innhold.
I tillegg til ren tekst-til-lyd støtter alle tre modellene inpainting – altså at du kan ta et eksisterende lydklipp, markere en del du vil endre, og la modellen regenerere akkurat den biten. Det er et kraftig verktøy for redigering og videre bearbeiding av generert lyd.
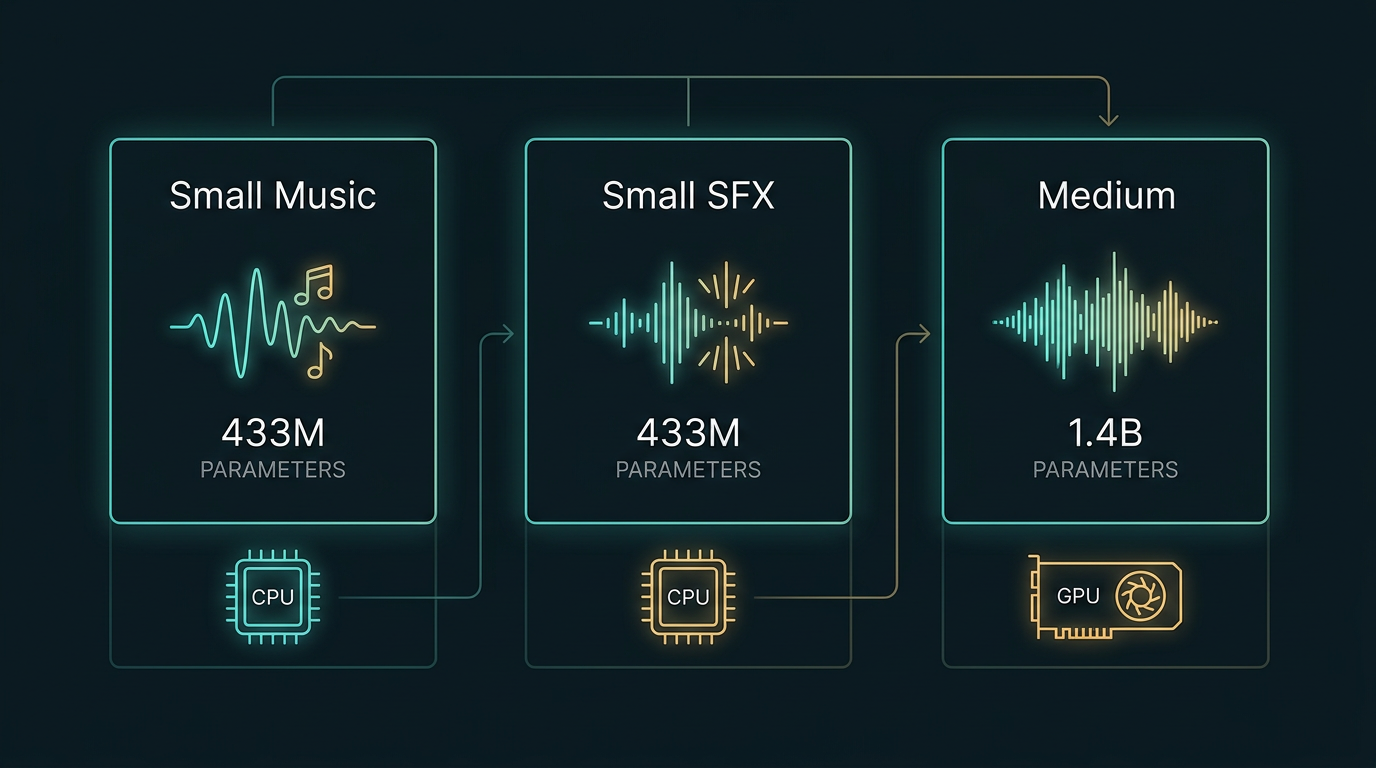
Hvilke modeller lanseres, og hva koster de å kjøre?
Tre modeller ble sluppet 21. mai 2026, alle gratis og åpne under Stability AI Community License.
Small Music (433M parametere): Optimalisert for musikk opp til 120 sekunder. Kjører på CPU – MacBook Pro M4 klarer det på noen sekunder, og selv eldre maskiner er innenfor rekkevidde. Størrelsen er 0,6 milliarder parametere, noe som gjør den overraskende lett til å være en diffusion-modell.
Small SFX (433M parametere): Samme modellstørrelse, men finjustert for lydeffekter og korte lyder. Genererer alt fra lyden av et tog som ankommer en stasjon til miljølyder, footsteps og abstrakte effekter. Perfekt for spillutvikling, film og podcaster der du trenger spesifikke lyder raskt.
Medium (1,4 milliarder parametere): Krever GPU med CUDA, men gir vesentlig høyere kvalitet og støtter opptil 380 sekunder. På en H200 klarer den 120-sekunders lyd på 0,78 sekunder med rundt 6,5 GB VRAM i bruk. Den som trenger produksjonskvalitet, velger Medium.
For de aller fleste vil Small Music eller Small SFX være nok å begynne med. At de kjører på CPU betyr at du ikke trenger en dedikert GPU bare for å eksperimentere – noe som senker terskelen enormt.
Hvordan installerer du Stable Audio 3 lokalt?
Prosjektet bruker uv som pakkehåndterer, noe som gjør installasjon raskere enn tradisjonell pip. GitHub-repoet er tilgjengelig på github.com/Stability-AI/stable-audio-3, og modellene lastes ned direkte fra HuggingFace.
Grunninstallasjonen dekker generering fra tekst. I tillegg kan du installere Gradio-grensesnittet hvis du vil ha en nettleserbasert UI, eller LoRA-støtte for finjustering på eget lydmateriale. For Medium-modellen kreves Flash Attention 2.
Selve genereringen er enkel å bruke programmatisk:
from stable_audio_3 import StableAudioModel
model = StableAudioModel.from_pretrained("small-music")
audio = model.generate(
prompt="House music, festival-stemning, 124 BPM",
duration=120
)Merk at lisensen er Stability AI Community License, ikke Apache eller MIT. Det betyr gratis for personlig og ikke-kommersiell bruk, men du må sjekke stability.ai/license hvis du planlegger kommersiell bruk. T5Gemma-komponenten er i tillegg underlagt Googles Gemma-vilkår.
Hva betyr LoRA-støtte for lydmodeller?
LoRA (Low-Rank Adaptation) er en teknikk du kjenner fra bildemodeller – du trener modellen på en liten samling eksempler for å lære en spesifikk stil, stemme eller sjanger, uten å trene hele modellen på nytt. Det er raskt og billig sammenlignet med full fine-tuning.
Stable Audio 3 støtter dette fra dag én, og det er en stor nyhet. Det betyr at musikere kan finjustere modellen på sin egen stil, at spillutviklere kan trene på et spesifikt lydunivers, og at podcasters kan generere konsistent bakgrunnsmusikk med en bestemt «merkevare-lyd». ACE-Step, som jeg skrev om tidligere i vår, støtter også LoRA – men den er primært musikk-fokusert. Stable Audio 3 dekker både musikk og lydeffekter med samme treningsrammeverk.
Forskningspapiret som beskriver arkitekturen er tilgjengelig på arxiv.org/abs/2605.17991 for de som vil gå dypere inn i teknologien.

Stable Audio 3 vs Suno og ACE-Step – hva velger du?
Landscape-et for AI-musikk og lyd er mer fragmentert enn det burde være, men nå begynner det å ta form. Her er den ærlige sammenligningen:
Suno og Udio gir deg ferdig musikk med vokal via en nettjeneste. Enkelt å bruke, men du har liten kontroll, det koster penger, og du er avhengig av at tjenesten fortsetter å eksistere. Se den komplette AI-musikk-guiden for en full oversikt over disse tjenestene.
ACE-Step er et open source alternativ med sterkere fokus på musikalsk struktur og chain-of-thought-generering. Det er bedre for de som vil ha full kontroll over komposeringsprosessen, og kjører lokalt akkurat som Stable Audio 3.
Stable Audio 3 skiller seg ut på to punkt: lydeffekter og hardware-krav. Ingen av de andre dekker SFX-siden ordentlig, og ingen kjører like effektivt på ren CPU. Hvis du trenger å generere lyd uten GPU, er dette det eneste seriøse valget per i dag.
For de som jobber med lokal AI-lyd generelt – enten det er tale, musikk eller effekter – er Stable Audio 3 et naturlig tillegg til verktøykassen. Det løser et hull som har eksistert lenge i open source lyd-verdenen.
Personlig kommer jeg til å teste Small SFX for podkast-bruk og Small Music for bakgrunnsmusikk til videoinnhold. Begge modellene er allerede tilgjengelig på HuggingFace: Small Music og Small SFX. Gi meg gjerne beskjed i kommentarfeltet om du tester det ut – det er litt for tidlig til å si noe om kvalitet i praksis ennå.








2 kommentarer