

Innhold Vis
Google lanserte Gemma 4 den 2. april 2026 – den første Gemma-modellen med Apache 2.0-lisens. Det er et større skifte enn det høres ut. Tidligere Gemma-modeller hadde egne lisensvilkår som begrenset kommersiell bruk. Nå bytter Google til en av de mest åpne lisensene som finnes. Modellene kommer i fire størrelser, støtter over 140 språk, og den minste varianten krever under 1,5 GB minne.
Gemma-serien har vært populær siden starten. Over 400 millioner nedlastinger og mer enn 100 000 varianter i det som nå kalles «Gemmaverse.» Men den forrige lisensen satte grenser. Du kunne bruke dem, ja – men ikke alltid som du ville. Apache 2.0 fjerner den usikkerheten.
Her er det du trenger å vite om Gemma 4: hva som er nytt, hva modellene faktisk klarer, og hvorfor lisensendringen betyr mer enn de fleste tror.
Fire modellvarianter – fra lommeformat til kraftpakke
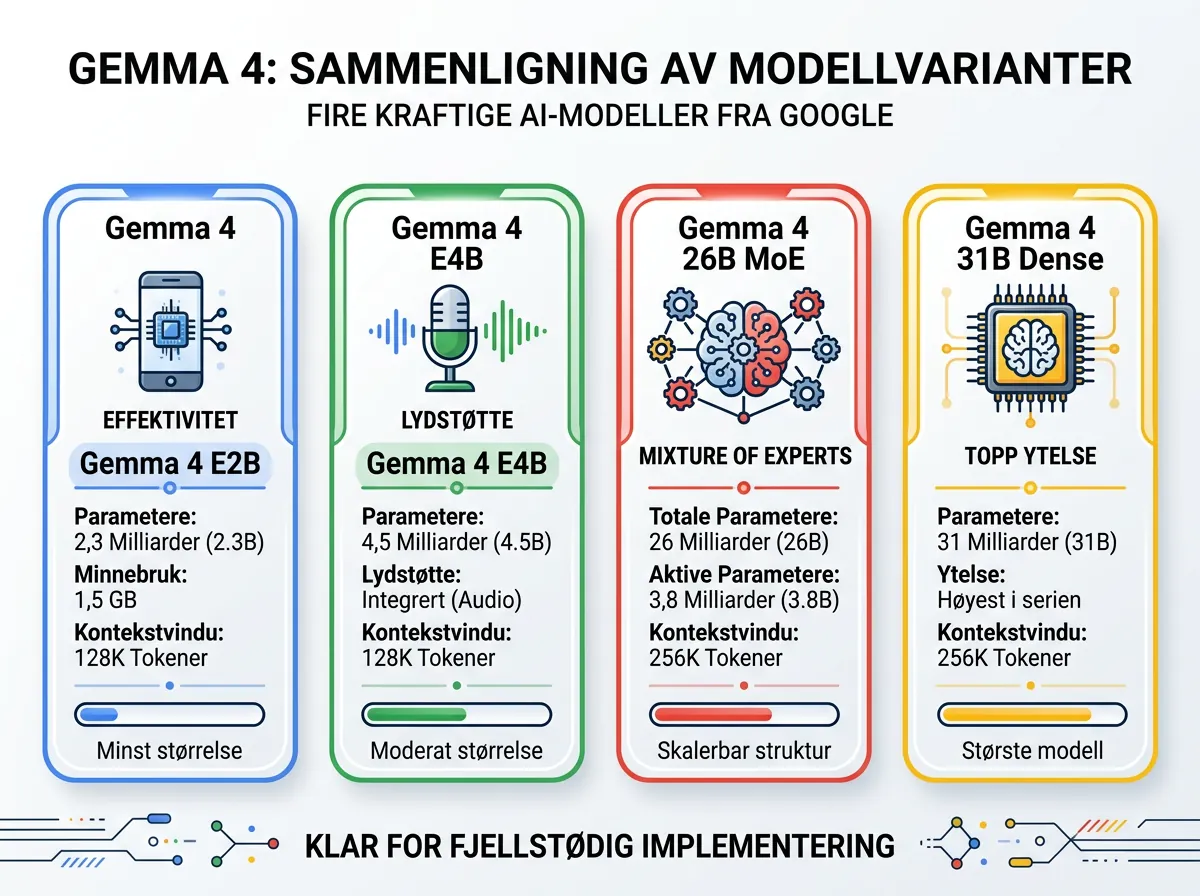
Gemma 4 kommer i fire varianter med ganske forskjellig profil:
- E2B – 2,3 milliarder effektive parametere, kjører på under 1,5 GB minne, støtter tekst og bilder
- E4B – 4,5 milliarder effektive parametere, støtter tekst, bilder og lyd
- 26B A4B – Mixture of Experts-arkitektur med 26 milliarder totale parametere, men bare 3,8 milliarder aktive per inferens
- 31B Dense – Den største, tetteste modellen med 256 000 tokens kontekstvindu
E2B og E4B er edge-modeller med 128 000 tokens kontekst. Det er allerede imponerende for den størrelsen. 31B-modellen dobler det til 256 000 tokens – nok til å lese en hel roman og stille spørsmål om den etterpå.
MoE-arkitekturen i 26B A4B-varianten er interessant. 26 milliarder parametere totalt, men bare 3,8 milliarder er aktive når modellen prosesserer et spørsmål. Det gir ytelse som ligner en fullstendig 26B-modell, men med en brøkdel av regnekraften. Tenk på det som en spesialistgruppe der bare de relevante ekspertene kobles inn per oppgave.
Hva kan Gemma 4 egentlig?
Alle fire modellene støtter multimodal input – tekst og bilder som standard. E4B legger til lydstøtte. Alle er trenet på over 140 språk. Dette er ikke token-kjøring på norsk tekst med elendig forståelse, men faktisk flerspråklig trening.
På benchmarks holder den seg godt. 31B-varianten scorer 85,2% på MMLU Pro og 89,2% på AIME 2026. 26B MoE-modellen klarer faktisk 88,3% på AIME 2026 med bare 3,8 milliarder aktive parametere – det er ganske sprøtt. Den rangerer også som tredje beste åpne modell globalt på Arena AI-leaderboardet for tekst.
For koding er hoppet fra Codeforces ELO 110 til 2150 nevneverdig. Det er ikke random benchmark-tall – det betyr at modellen faktisk klarer competitive programming-oppgaver på et nivå som ellers krever spesialiserte modeller.
Gemma 4 er også bygget for agentbruk – function calling, strukturert JSON-output, og native system instructions for autonome arbeidsflyter. E2B demonstrerte prosessering av 4 000 input-tokens over to ferdigheter på under 3 sekunder. Til sammenligning: de fleste cloud API-kall tar like lang tid bare på nettverksforsinkelse.
Hvorfor betyr Apache 2.0 noe?
De fleste er kanskje ikke så opptatt av lisenser. Det skjønner jeg – det er ikke den mest spennende biten. Men her er det konkrete konsekvenser.
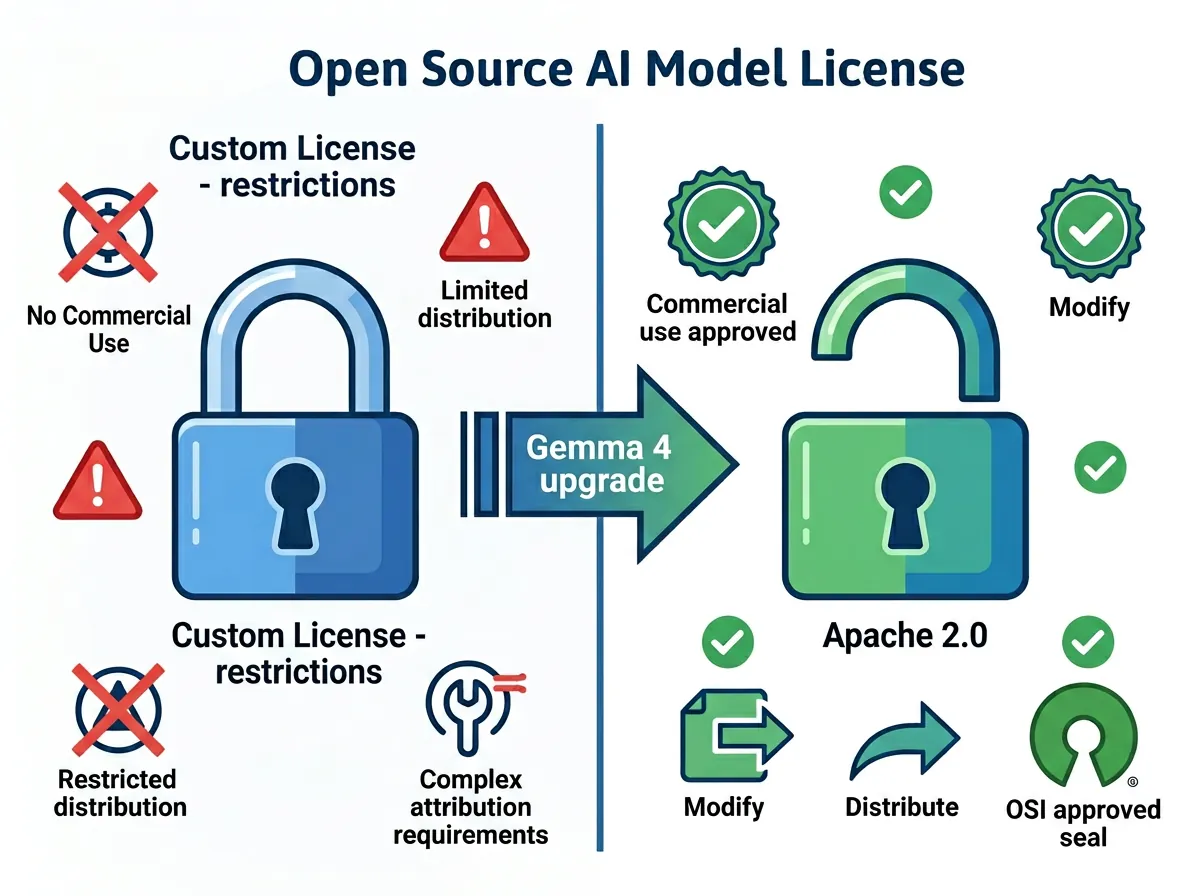
Apache 2.0 er en OSI-godkjent åpen lisens som gir deg rett til å bruke, modifisere og distribuere modellene – inkludert i kommersielle produkter. Du trenger ikke betale Google. Du trenger ikke søke om tillatelse. Du bygger bare.
Googles egne Gemma-lisenser hadde restriksjoner på kommersiell bruk som skapte usikkerhet. Bedrifter som ville bygge produkter på Gemma måtte tolke lisensvilkår og i verste fall innhente spesifikk tillatelse. Det bremset mange.
Apache 2.0 er den samme lisensen mange av de viktige åpne AI-verktøyene bruker. Det signaliserer at Google mener alvor med åpen utvikling – ikke bare «åpen for hobbyister, men ikke for bedrifter.»
Gemma 4 vs Gemma 3 – hva har endret seg?
Gemma 3 kom i mars 2025 med størrelsene 1B, 4B, 12B og 27B. Kontekstvinduer på 32K for 1B-varianten og 128K for de andre. Multimodal støtte på alt unntatt 1B-modellen.
Gemma 4 endrer arkitekturen ganske fundamentalt. MoE er nytt. Lydstøtte er nytt. 256K kontekstvindu på de største modellene er nytt. Og Apache 2.0 er selvsagt det største skiftet.
Ytelseshopp er også tydelig. MMLU Pro gikk fra 67,5 (Gemma 3 27B) til 85,2 (Gemma 4 31B). Det er ikke et lite steg – det er nesten 18 prosentpoeng på ett år. Codeforces ELO-hoppet fra ~100-tall til 2150 er enda mer dramatisk.
Kan du kjøre Gemma 4 lokalt?
Ja. Det er poenget med hele greia.
E2B på under 1,5 GB minne betyr at den kjører på telefoner, Raspberry Pi-er og rimelige laptoper. E4B krever mer, men er fortsatt langt innenfor hva en vanlig PC med 8-16 GB RAM håndterer. Ollama støtter allerede Gemma-modellene, og Gemma 4 vil følge. LM Studio og andre lokale kjøringsverktøy vil raskt få støtte.
For de større variantene (26B MoE og 31B) trenger du litt mer muskler – et grafikkort med 16-24 GB VRAM er et greit utgangspunkt. Men MoE-arkitekturen i 26B-varianten er nettopp designet for å kreve mindre ressurser enn en fullstendig 26B-modell ville gjort.
Hva betyr det i praksis? At du kan ha en multimodal modell som støtter tekst, bilder og lyd, med 128K kontekstvindu, kjørende helt lokalt på din egen maskin. Ingen API-kostnader. Ingen dataoverføring. Full kontroll.
Er dette faktisk imponerende?
Jeg synes det er genuint bra. Ikke fordi Google lanserer enda en modell – det gjør de hele tiden – men fordi kombinasjonen her faktisk betyr noe.
Apache 2.0 + sterke benchmarks + liten minnefotavtrykk + multimodal + 140 språk. Det er ikke én ting, det er fire ting samtidig. E2B under 1,5 GB med 128K kontekst er spesielt interessant for alle som vil kjøre noe kraftig på begrenset hardware.
Gemmaverse-tallene – 400 millioner nedlastinger, 100 000+ varianter – viser at dette er modeller folk faktisk bruker og fine-tuner. Apache 2.0 vil gjøre det enda lettere å bygge kommersielle produkter på toppen uten juridisk risiko.
Konkurransen mellom åpne modeller har aldri vært hardere. Meta med Llama, Alibaba med Qwen, Mistral, og nå Google som skrur opp lisensens åpenhet. Det er bra for alle som vil bruke AI uten å betale per token til en skyplattform hver gang.
Modellene er tilgjengelige på Googles Hugging Face-profil og via Google AI for Developers.








4 kommentarer