

Innhold Vis
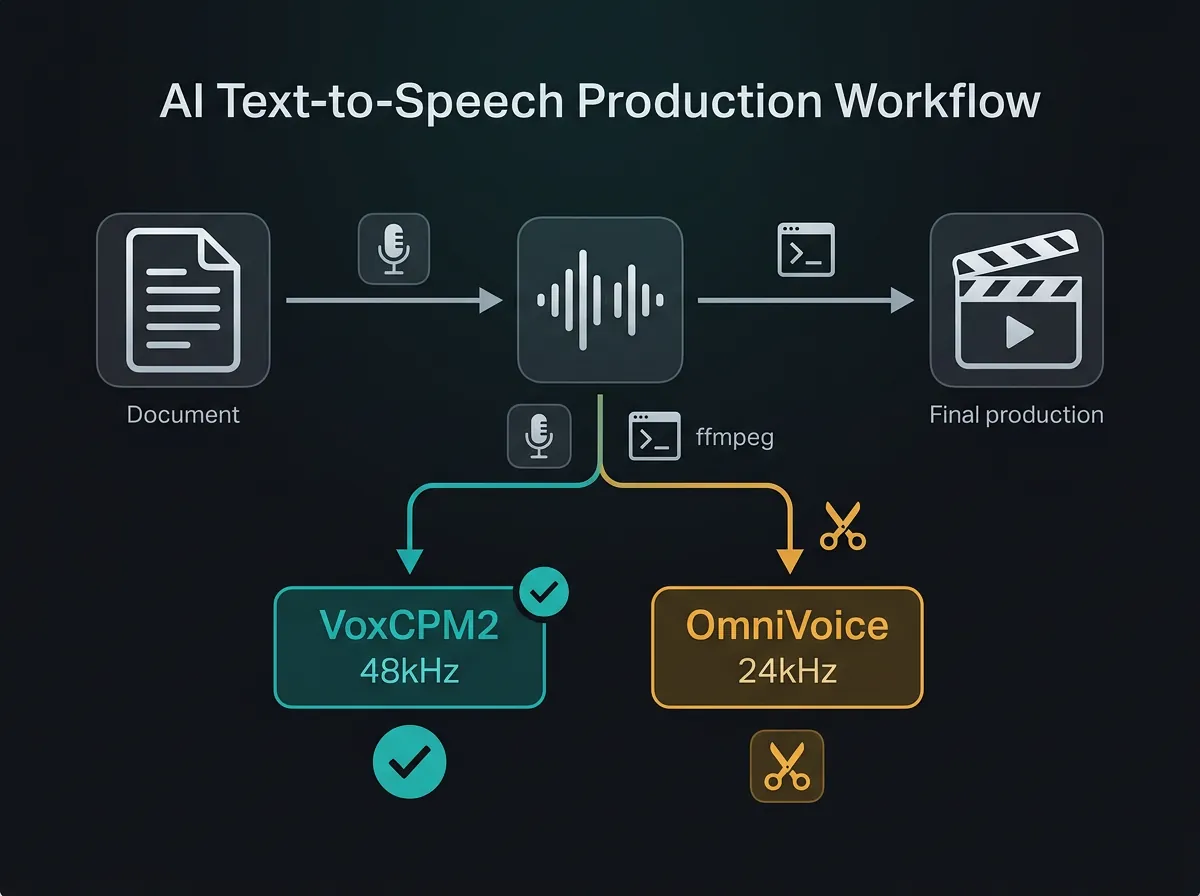
VoxCPM2 og OmniVoice er to open source AI-modeller for talesyntese som du kan kjøre helt gratis på egen maskin. VoxCPM2 leverer 48 kHz studio-kvalitet med imponerende voice cloning, mens OmniVoice støtter over 600 språk og har innebygde non-verbale lyder. Begge kjører på 12 GB GPU og krever null abonnement.
Jeg brukte VoxCPM2 til narrasjonen i en 6 minutter lang kortfilm jeg produserte. Det ga meg et praktisk bilde av hva disse modellene faktisk tåler – og hvor grensene går. Resultatet var bra nok til at jeg ble overrasket. Men det er noen ting du bør vite før du setter i gang.
Denne artikkelen er for deg som vil slippe å betale ElevenLabs hundrevis av kroner i måneden, eller som bare er nysgjerrig på hva open source TTS egentlig klarer i 2026. Jeg tar for meg begge modellene, sammenligner dem, og gir deg de praktiske tipsene jeg lærte gjennom testing.
Hva er VoxCPM2 og OmniVoice?
VoxCPM2 (openbmb/VoxCPM2 på HuggingFace) er en 2 milliarder parameter modell fra OpenBMB. Den er laget for høykvalitets talesyntese og kan klone stemmer fra omtrent 20 sekunder referanse-audio. Output er 48 kHz – det er det samme som du finner i profesjonell studioinnspilling.
OmniVoice (k2-fsa/OmniVoice på GitHub) tar en annen tilnærming: bred språkdekning. Over 600 språk støttes, og modellen har innebygde non-verbale lyder som [laughter], [sigh] og [surprise-ah] som faktisk fungerer. Output er 24 kHz, som er greit for de fleste bruksområder.
Begge er lisensiert for fri bruk og kjører lokalt. Det betyr at du ikke sender lydfiler til en ekstern server, og du betaler ingenting per minutt generert audio. Her er resultatet – en 6 minutters kortfilm der VoxCPM2 gjør all narrasjon
48 kHz vs 24 kHz – hva betyr det i praksis?
Sample rate handler om lydkvalitet. 48 kHz er standarden du finner i film og profesjonell produksjon. 24 kHz er det du hører i videokonferanser – tydelig nok for tale, men ikke det du vil ha i en produksjon som skal høres bra ut på høyttalere.
For podcast, YouTube-video eller en kortfilm er dette faktisk viktig. VoxCPM2 sin 48 kHz output holder seg godt i mix med musikk og lydeffekter. OmniVoice sin 24 kHz vil typisk høres litt «tynn» ut i samme kontekst, men er fullt brukbar for instruksjonsvideoer, e-læring, eller innhold der lyden er ren tale uten mye annet rundt.
Kort sagt: vil du ha filmkvalitet, velg VoxCPM2. Er du ute etter bred språkdekning og non-verbal ekspressivitet, er OmniVoice bedre – selv om den har lavere sample rate.
Hvordan installerer jeg dem?
VoxCPM2 er enkelt å komme i gang med. Én kommando, og modellen lastes ned automatisk første gang du kjører den:
pip install voxcpm
python -c "from voxcpm import VoxCPM2; model = VoxCPM2()"For OmniVoice følger du installasjonsinstruksjonene i GitHub-repoet. Det krever litt mer oppsett, men er godt dokumentert. Du trenger også Whisper for å transkribere referanse-audio – mer om det under.
Begge modellene kjører på 12 GB GPU. Har du et RTX 3080, 4070 eller tilsvarende, er du klar.
Voice cloning – slik fungerer det
Voice cloning lar deg gi modellen en stemme-referanse, og la den generere ny tekst i samme stemme. I VoxCPM2 holder det med omtrent 20 sekunder rent referanse-audio. Jeg brukte det første forsøket til kortfilmen min – det fungerte.
VoxCPM2 har i tillegg en funksjon kalt voice design, der du beskriver stemmen i parentes direkte i teksten: (A gruff older man with gravelly voice) Modellen tolker dette og justerer stemmekvaliteten. Stilig – men du kan ikke kombinere voice cloning og voice design i samme kjøring. Det er enten eller.
I OmniVoice brukes ref_audio-parameteren for voice cloning. Viktig detalj her: ref_text MÅ transkriberes med Whisper, ikke skrives fra hukommelsen. Jeg prøvde å skrive det manuelt første gang. Resultatet var dårligere enn forventet. Whisper large-v3 løste det.
Kan jeg bruke disse modellene på norsk?
Ærlig svar: brukbart, men ikke bra – i hvert fall ikke ut av boksen.
VoxCPM2 på norsk: stemmen kloner fint, men tempoet er for raskt. Omtrent 20% for fort. Det lar seg fikse med ffmpeg i etterkant:
ffmpeg -i input.wav -filter:a "atempo=0.85" output.wavOmniVoice er faktisk litt bedre på norsk enn VoxCPM2, men «bedre» betyr ikke «bra». Stemmen sitter med cloning, men selve språket går flatt. Pauser, oppbygning, rytme – det som gjør norsk til norsk – mangler. Norsk TTS er fremdeles et uløst problem i open source-verdenen i 2026.
Dialekt fungerer ikke. Jeg testet fonetisk tekst for å simulere dialekt. Resultatet vris mot noe som høres nynorsk-preget ut. La det ligge.
Har du behov for skikkelig norsk tale-AI, er NB-Whisper et mye bedre utgangspunkt – men det er for transkribering, ikke syntese. For syntese er du fremdeles best tjent med ElevenLabs hvis norsk kvalitet er avgjørende.
Svakheter du bør vite om
Ingen av modellene er perfekte. Her er de viktigste begrensningene jeg støtte på:
- VoxCPM2 og lange tekster: Tekster på 2-3 minutter og oppover begynner å bryte sammen. Løsningen er segmentering – del opp i chunks på omtrent 1 minutt, bruk samme referanse-audio gjennom hele sesjonen for konsistens.
- *sigh* og *laugh* leses som ord: Asterisk-syntaks fungerer ikke i VoxCPM2. Stjernen og ordet leses bokstavelig. Vil du ha non-verbale lyder, er OmniVoice et bedre valg.
- OmniVoice og ref_text: Transkriber alltid referanse-audio med Whisper. Manuell transkripsjon gir merkbart dårligere resultat.
- Norsk tempo: Begge modellene kjører norsk for raskt. ffmpeg atempo i post er bedre enn å justere tempo-parameteren under generering – sistnevnte påvirker stemmekvaliteten negativt.
Non-verbale lyder er generelt et uløst problem i open source TTS per 2026. OmniVoice er den eneste av disse to som har fungerende støtte, men det er begrenset til noen få tags.
Sammenligning med ElevenLabs – er det verdt å bytte?
ElevenLabs koster mellom 5 og 1 320 dollar i måneden avhengig av plan. Du får bedre non-verbal kontroll, rikere emosjonell variasjon, og mye bedre norsk. Det er ingen tvil om at ElevenLabs er overlegen på rene kvalitetsmål.
Men for produksjon der du kontrollerer alle parameterne selv – der du segmenterer, velger referanse-audio nøye, og gjør etterbehandling i ffmpeg – er VoxCPM2 svært nær på engelsk. Jeg la narrasjonen fra kortfilmen min under musikk og lydeffekter, og den holdt seg godt.
Spørsmålet er hva du trenger. Rask iterasjon med lite etterbehandling? ElevenLabs. Full kontroll, ingen kostnad per minutt, og du er komfortabel med litt teknisk arbeid? VoxCPM2 er et reelt alternativ.
Jobber du med musikk eller lydproduksjon og vil utforske AI-generert lyd fra en annen vinkel, kan det også være verdt å se på guiden min til AI-musikk. Og hvis du er interessert i hva som skjer med AI og lyd generelt, dekket jeg ACE-Step XL nylig – en modell som gjør noe ganske annerledes med musikkgenerering.
Praktiske tips fra produksjonen
Dette er det jeg faktisk lærte gjennom å bruke VoxCPM2 på et lengre prosjekt:
- Segmenter alltid: Del opp lange tekster i chunks på omtrent 1 minutt. Bruk nøyaktig samme ref_audio-fil for alle chunks for å holde stemmen konsistent gjennom hele produksjonen.
- Whisper large-v3 for synkronisering: Bruk Whisper til å transkribere ferdig audio for å synkronisere med video. Det gir mer presis timing enn å gjøre det manuelt.
- ffmpeg for tempokorrigering: atempo=0.85 for norsk. Gjør dette som siste steg, ikke under generering.
- Velg referanse-audio nøye: Klar romklang, uten bakgrunnsstøy, tydelig tale. Jo renere referansen er, jo bedre blir cloning-resultatet.
Begge modellene er tilgjengelige nå og fungerer på standard gaming-GPU. Det er ganske imponerende hva du kan få til gratis med litt tålmodighet og riktig workflow.








1 kommentar