

Innhold Vis
LARQL er et open source-prosjekt som gjør noe ganske bisart: det behandler en AI-modell som en database du kan spørre mot, og gjør at du kan kjøre Gemma 4 26B spredt over to billige maskiner i stedet for én dyr GPU-rigg. Prosjektet dukket opp på Reddit i LocalLLaMA-forumet og skapte umiddelbar begeistring – og når du forstår hva det faktisk gjør, er det lett å forstå hvorfor.
Problemet med lokale LLM-er er alltid det samme: de store modellene krever enorme mengder VRAM. Gemma 4 26B er ikke noe du bare laster ned og kjører på en vanlig gaming-PC. Det har vært en hard grense for hva som er praktisk mulig hjemme eller i en liten bedrift. LARQL angriper dette problemet fra en helt annen vinkel enn det vi har sett tidligere.
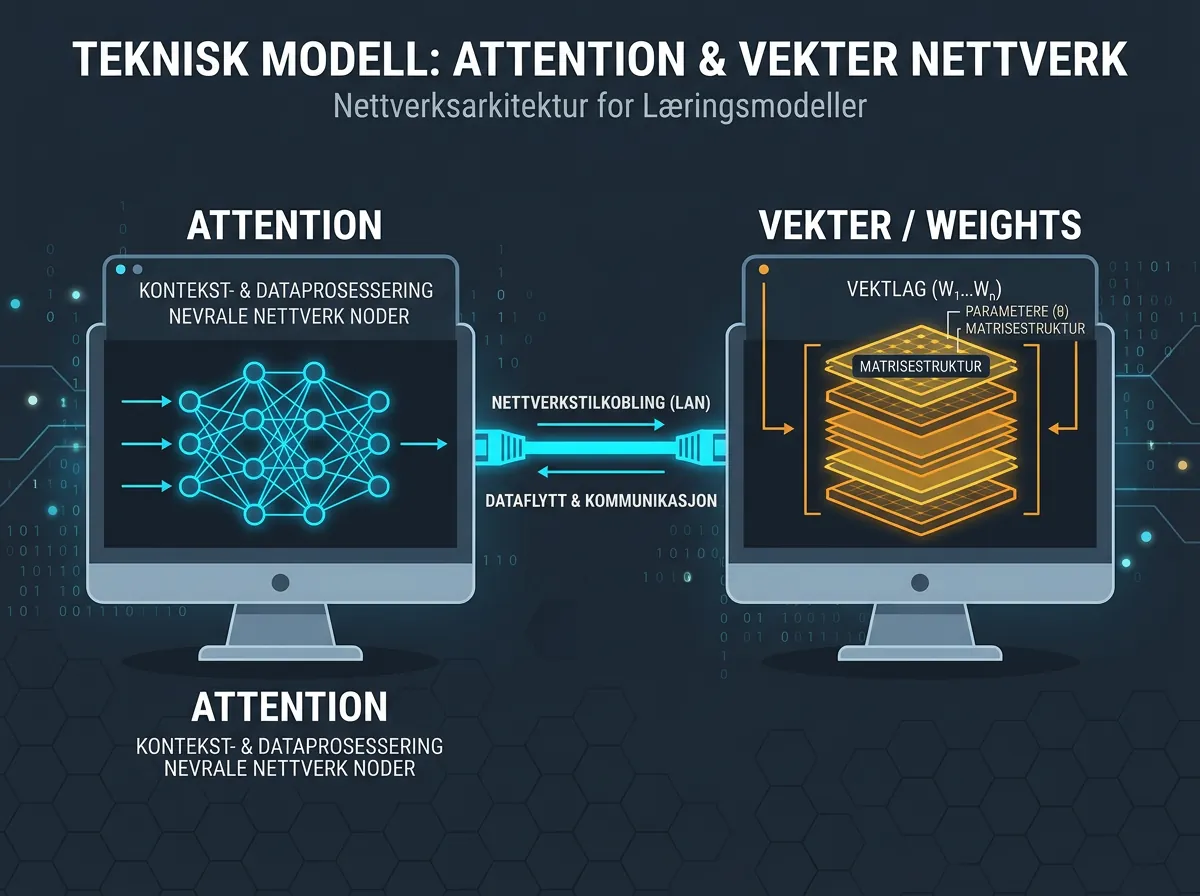
I stedet for å prøve å kvantisere modellen ned til noe håndterlig, deler LARQL opp selve arkitekturen. Attention-mekanismen – den kognitive «tenkingen» som skjer i modellen – kjører lokalt. Selve modellvektene, som er de tunge gigabytene, flyttes til en annen maskin. En billig Xeon-server holder. En gammel stasjonær PC holder. Det trenger ikke være fancy.
Hva er egentlig LARQL?
LARQL på GitHub beskriver seg selv som et verktøy for å transformere nevrale nettverk til querybare databaser. Det høres kryptisk ut, men ideen er elegant: modellen dekompileres til et format kalt vindex (vector index), der vektlagene organiseres som en graf-database du kan spørre mot med et eget spørrespråk kalt LQL (Lazarus Query Language).
Det praktiske resultatet er at du kan gjøre operasjoner på modellen – bla gjennom vekter, analysere strukturen, til og med redigere – uten at du trenger GPU i det hele tatt for de rene utforskingsoperasjonene. Men det som gjør prosjektet virkelig interessant er den distribuerte inference-funksjonaliteten: attention-laget kjøres separat fra vektene.
Repoet har 843 stjerner og 133 forks i skrivende stund, og koden er tilgjengelig under Apache 2.0-lisens. Det er skrevet i Rust, noe som gir ytelseskarakteristikker man sjelden ser i Python-baserte alternativer.
Hva betyr «decoupled attention from weights» i praksis?
I en vanlig transformer-modell er attention-mekanismen og modellvektene tett koblet sammen. De kjøres i samme operasjon, på samme maskin, krever samme minneressurser. Det er litt som å si at en kalkulator bare kan brukes hvis den og selve tallene fysisk befinner seg på samme sted.
LARQL bryter denne koblingen. Attention-prosessen – det som faktisk «tenker» og setter ord i sammenheng med hverandre – kan kjøres på en lokal maskin med begrenset RAM. Selve vektene, som utgjør det meste av modellens størrelse, flyttes til en annen maskin på nettverket. Maskin nummer to trenger ikke være kraftig. En gammel Xeon-server med mye RAM er perfekt. De koster ingenting brukt.
Resultatet er at Gemma 4 26B, en modell som normalt krever minst 16-20 GB VRAM, plutselig blir tilgjengelig for et to-maskin-oppsett der ingen av maskinene trenger å være særlig dyre. Det er ikke magi – det er smart arkitektur.
Hvordan kommer du i gang med LARQL?
Prosjektet bygges fra kilden med Cargo (Rusts pakkebehandler):
cargo build --release
Deretter kan du enten hente ferdig-konverterte modeller direkte:
larql pull hf://chrishayuk/gemma-3-4b-it-vindex larql run gemma-3-4b-it-vindex "Skriv meg et kort dikt"
Eller ekstraherer du dine egne modeller fra Hugging Face:
larql extract google/gemma-3-4b-it -o gemma3-4b.vindex
Prosjektet støtter Metal-akselerasjon på macOS og OpenBLAS på Linux og Windows. Støttede modellfamilier inkluderer Gemma, Llama, Mistral og Qwen opp til 31 milliarder parametere. Lagringskravet varierer: rundt 3 GB for ren utforskning uten inference, opp til 27 GB for full kjøring.
Det er verdt å merke seg at dette fortsatt er et aktivt prosjekt i utvikling. Funksjonene for distribuert kjøring er ikke nødvendigvis like polerte som man finner i mer modne verktøy, men kjernekonseptet er funksjonelt og koden er offentlig tilgjengelig for de som vil eksperimentere.
Hva skiller dette fra llama.cpp og Ollama?
Spørsmålet er naturlig: vi har jo allerede Ollama og llama.cpp for å kjøre modeller lokalt. Hva gjør LARQL annerledes?
llama.cpp støtter nå tensor parallelism – du kan dele en modell over flere GPU-er. Det er bra, men det krever at begge GPU-ene er i samme maskin og helst av samme type. LARQL tar et mer radikalt skritt og sier at maskinene ikke trenger å henge sammen fysisk i det hele tatt. De kan kommunisere over et lokalt nettverk.
Ollama er fantastisk for enkel oppsett og kjøring på én maskin, men det er ikke designet for distribuerte oppsett. LARQL er heller ikke et direkte Ollama-alternativ – det er snarere en annen filosofi for hva en AI-modell egentlig er. Behandle den som en database, ikke som en monolittisk binær fil.
Det er også verdt å nevne at LARQL eksponerer en helt annen type funksjonalitet: du kan faktisk spørre mot modellvektene, analysere dem, og potensielt redigere dem. Det åpner dører for eksperimentering som ikke finnes i Ollama eller llama.cpp.

Er dette gjennombruddet for lokal AI hjemme?
Jeg er alltid litt forsiktig med å erklære gjennombrudd for tidlig – det har blitt gjort altfor mange ganger i AI-verdenen. Men dette er genuint spennende av én konkret grunn: det angriper skaleringsproblem fra en uventet vinkel.
Vi har i årevis prøvd å løse «modellen er for stor for én maskin»-problemet ved å gjøre modellen mindre (kvantisering) eller maskinen større (bedre GPU). LARQL foreslår noe annet: del opp selve kjøringen over maskiner du allerede har. En gammel PC som samler støv i hjørnet. En Raspberry Pi med nok RAM. En utdatert server du fikk billig.
Det minner meg litt om hvordan Bitcoin og andre blokkjedeteknologier distribuerte databehandling – ikke ved å ha én superdatamaskin, men ved å la mange ordinære maskiner samarbeide. Konseptet er ikke nytt, men anvendt på lokal AI-inferens er det ganske friskt.
Om du allerede er kjent med Gemma 4 og spekulativ dekoding, er LARQL neste logiske steg å utforske. Og hvis du leter etter alternativer til sky-tjenester for å kjøre store modeller privat og uten abonnementskostnader, er dette definitivt verdt å følge med på.
Prosjektet er ungt. Det vil ha bugs. Det vil endre seg. Men grunnideen – at du kan splitte en modell over to billige maskiner og unngå den dyre GPU-flaskehalsen – er den typen kreativ løsning som faktisk kan gjøre store lokale modeller tilgjengelige for folk flest. Hva tenker du? Har du maskiner stående som kunne vært utnyttet til dette?








1 kommentar