

Innhold Vis
En bruker på r/LocalLLaMA har bygget en PC som kjører Kimi K2.5 med 1 000 milliarder parametere lokalt – og klarer over 4 tokens per sekund. Det uvanlige er ikke modellen, men minneteknologien: Intel Optane Persistent Memory, en diskontinuert DIMM-teknologi som befinner seg et sted mellom vanlig RAM og SSD. Ingen hadde brukt dette i et LLM-inferens-bygg før.
Optane PMem er ikke lenger i produksjon – Intel la ned hele Optane-divisjonen i 2022 – men modulene finnes brukt til svært lave priser. Det er der denne historien begynner. Hva skjer når noen drar ut gammel serverteknologi fra støvete datacenter-hyller og putter inn en av verdens største open source-modeller?
Svaret: det fungerer faktisk. Og det forteller oss noe interessant om hva lokal AI-inferens egentlig handler om.
Hva er Intel Optane Persistent Memory?
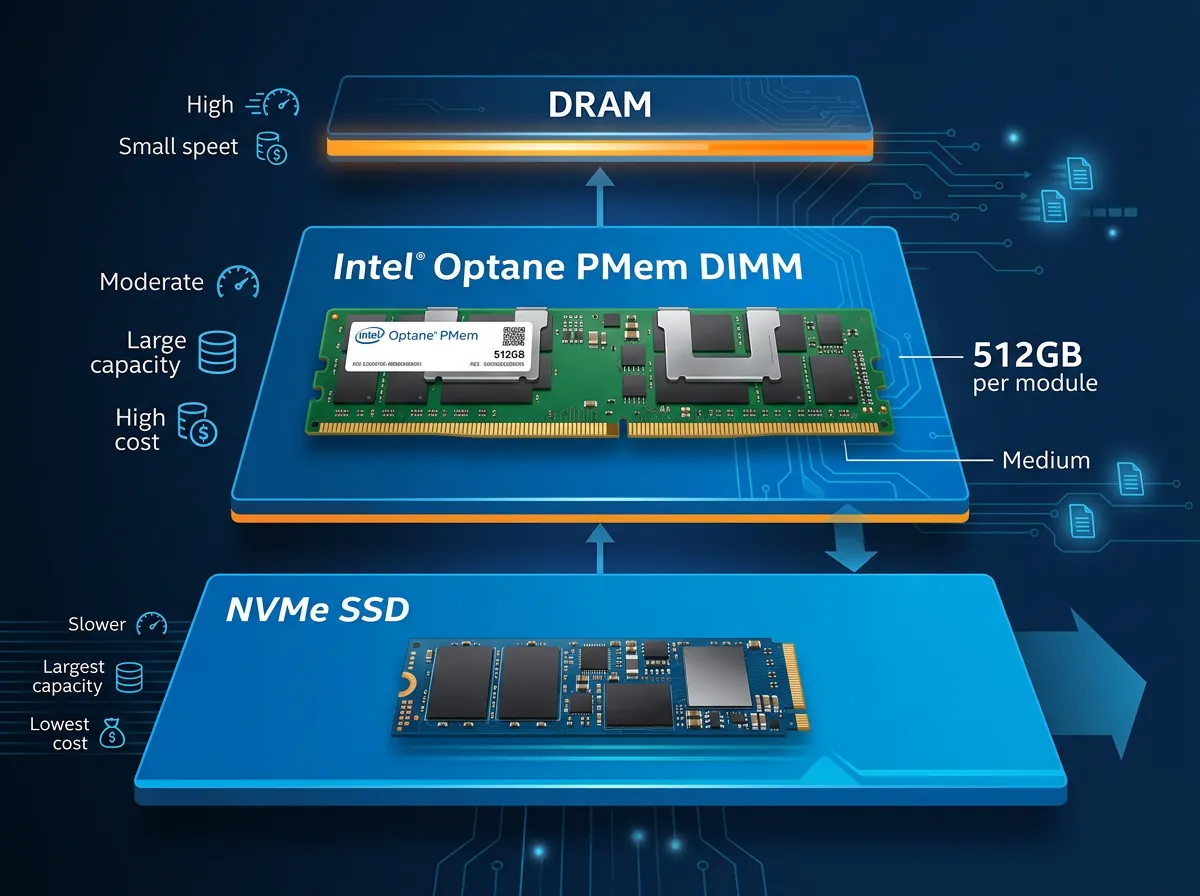
Intel Optane Persistent Memory – eller PMem – er en DIMM-modul som plugges rett i minneslottene på et serverhovedkort. Teknologien heter 3D XPoint og ble utviklet av Intel og Micron i fellesskap. Den er ikke DRAM, ikke SSD, men noe midt imellom.
Ytelsen speiler det: Optane PMem er tregere enn DDR4 men raskere enn NVMe SSD. Latensen er ett til to størrelsesordener høyere enn SDRAM, men kapasiteten per modul er enorm – 128 GB, 256 GB eller opptil 512 GB per DIMM. Per socket kan du stable opp til 4 TB med PMem 200-serien. Det er tall som vanlig RAM simpelthen ikke kan konkurrere med på pris.
Modulene krever tredje generasjons Intel Xeon Scalable-prosessorer og kjører på 3 200 MT/s med maksimalt 15 watt TDP. De kan operere i to moder: Memory Mode (fungerer som vanlig RAM, men med lagring i bakgrunnen) og App Direct Mode (applikasjonen styrer direkte hva som lagres i PMem vs DRAM). For LLM-inferens er det den enorme kapasiteten som er interessant, ikke nødvendigvis hastigheten.
Hva er spesifikasjonene til builden?
Kjernen i riggen er et Xeon-basert serveroppsett med nok Intel Optane PMem-moduler til å holde hele Kimi K2.5 i minnet. Kimi K2.5 er en 1 000 milliarders parameter open source-modell fra Moonshot AI – den samme modellen som viste seg å ligge bak Cursor Composer 2.
Ytelsen er 4+ tokens per sekund. Det høres kanskje lite ut, men for en modell av denne størrelsen er det faktisk imponerende. Til sammenligning er 1 000 milliarder parametere omtrent det samme som hva man antar GPT-4 er i størrelsesorden – en modell du normalt ville trengt enorme GPU-klynger for å kjøre.
Det spesielle med Optane PMem i denne konteksten er at hele modellvekten bor i DIMM-slottene, aksessert direkte av prosessoren. Ingen GPU. Ingen NVMe-strømming. Minnet er stort nok til at modellen faktisk får plass.
Hvorfor er Optane PMem billig nå?
Intel la ned Optane-divisjonen i juli 2022. Micron hadde allerede droppet ut i 2021 for å fokusere på CXL-baserte løsninger. Intel solgte Lehi-fabrikken til Texas Instruments for 900 millioner dollar.
Resultatet er at brukte Optane PMem-moduler nå finnes på eBay og brukt servermarked til en brøkdel av opprinnelig pris. Datasentre som oppgraderer infrastrukturen kvitter seg med dem. For noen med riktig serverhovedkort og en Xeon fra tredje generasjon er det en mulighet til å lage et minneoppsett som ellers ville kostet en formue.
Det er litt som å finne brukte ECC-rammer fra 2018 – teknologien er gammel, men kapasiteten er fortsatt reell.

Er 4 tokens per sekund nok til å faktisk bruke modellen?
Det kommer an på hva du bruker den til. Til interaktiv chat der du sitter og venter på svar, er 4 tok/s akkurat på grensen – mange vil oppleve det som litt tregt. Til batch-prosessering, analyse av lange dokumenter, eller oppgaver der du lar modellen jobbe i bakgrunnen, er det absolutt brukbart.
Til sammenligning kjører Intel Arc Pro B70 235 tokens per sekund med Gemma 3 27B – men da snakker vi om en modell som er 37 ganger mindre. Kimi K2.5 har 1 000 milliarder parametere mot Gemma 3 27Bs 27 milliarder. Skjønnheten er at du faktisk KAN kjøre en 1 000 milliarders parametermodell lokalt overhodet, til en kostnad som ikke er astronomisk.
Det er ikke optimalt, men det er mulig. Og «mulig» var definitivt ikke noe folk tok for gitt for slike modeller.
Hva sier dette om fremtiden for lokal AI?
Det interessante med dette bygget er ikke at det er praktisk for alle – det er det ikke. Det er at det viser hvor kreative folk blir med tilgjengelig hardware når de vil kjøre store modeller lokalt.
Lokal LLM-inferens handler grunnleggende om to ting: minnekapasitet og minnebåndbredde. GPU-er dominerer fordi de kombinerer begge. Men som dette bygget demonstrerer, kan du komme langt med kapasitet alene – du ofrer bare hastighet. Optane PMem gir kapasiteten. Xeon gir tilgangen. Kimi K2.5 er modellen.
Parallelt ser vi at Ollama-alternativene modnes og at lokale oppsett med RTX 4090 og Ollama allerede er godt dokumentert for modeller i 70B-klassen. Det som skjer nå er at grensen for «lokalt kjørbar» flyttes oppover – fra 7B til 70B til 400B til nå altså 1 000 milliarder parametere.
Det krever fremdeles spesialisert hardware og teknisk kunnskap å sette opp. Men det er ikke lenger umulig.
Hva koster det å bygge noe lignende?
Intel Optane PMem 200-moduler kan finnes på bruktmarkedet – og prisene varierer mye avhengig av kapasitet og tilstand. En 512 GB modul som opprinnelig kostet titusener av kroner kan nå gå for en brøkdel. Xeon-serverhardware fra denne generasjonen er tilsvarende rimelig brukt.
Baksiden er at det krever en tredje generasjons Intel Xeon Scalable-plattform – ikke vanlig forbrukerhardware. Det er et serveroppsett, ikke en gaming-PC. Du trenger et passende serverhovedkort, Xeon-prosessor(er), og nok PMem-moduler til å holde hele modellvekten. For Kimi K2.5 snakker vi om enorme mengder minne – modellvekter for en 1 000 milliarders parametermodell i FP16 er rundt 2 000 GB.
Quant-versjoner av modellen er langt mindre. Med aggressiv kvantering kan du komme ned til 500-600 GB, noe som er innenfor rekkevidde for et bygg med flere Optane PMem-moduler.
Open source gjør alt dette mulig
Det er verdt å stoppe opp ved det åpenbare: Kimi K2.5 er open source. Uten åpne modellvekter ville dette bygget ikke vært mulig. Open source AI-bevegelsen er det som gjør at enkeltpersoner kan eksperimentere med modeller i denne størrelsesklassen.
Det er markedet som løser dette – ikke statlige AI-programmer eller regulerte sky-plattformer. Noen fant brukte moduler, koblet dem til riktig hardware, lastet ned vekter, og publiserte resultatet. Slik spres kunnskap. Slik senkes terskelen.
Hva tenker du? Er Optane PMem noe du ville vurdert for et lokal LLM-bygg, eller er GPU-ruten mer praktisk for dine behov?







