

Innhold Vis
En utvikler leverte nylig noe ganske sprøtt på AMD x lablab-hackathonen: én setning inn, ferdig cinematic MP4 ut – komplett med karakterer, story, musikk og voice-over på opptil ni språk. Alt på én enkelt GPU. Alt open source.
Pipelinen heter One-Prompt-to-Cinematic-Reel og er tilgjengelig på GitHub. Den er bygget av åtte sekvensielle steg som kjøres på samme GPU, og bruker bare modeller med Apache 2.0- eller MIT-lisens. Totaltiden fra prompt til ferdig fil: rundt 45 minutter på en AMD Instinct MI300X.
Det er ikke et kommersielt produkt. Det er ikke en SaaS-tjeneste du betaler månedlig for. Det er kode du kan laste ned og kjøre selv – og det er akkurat det som gjør det interessant.
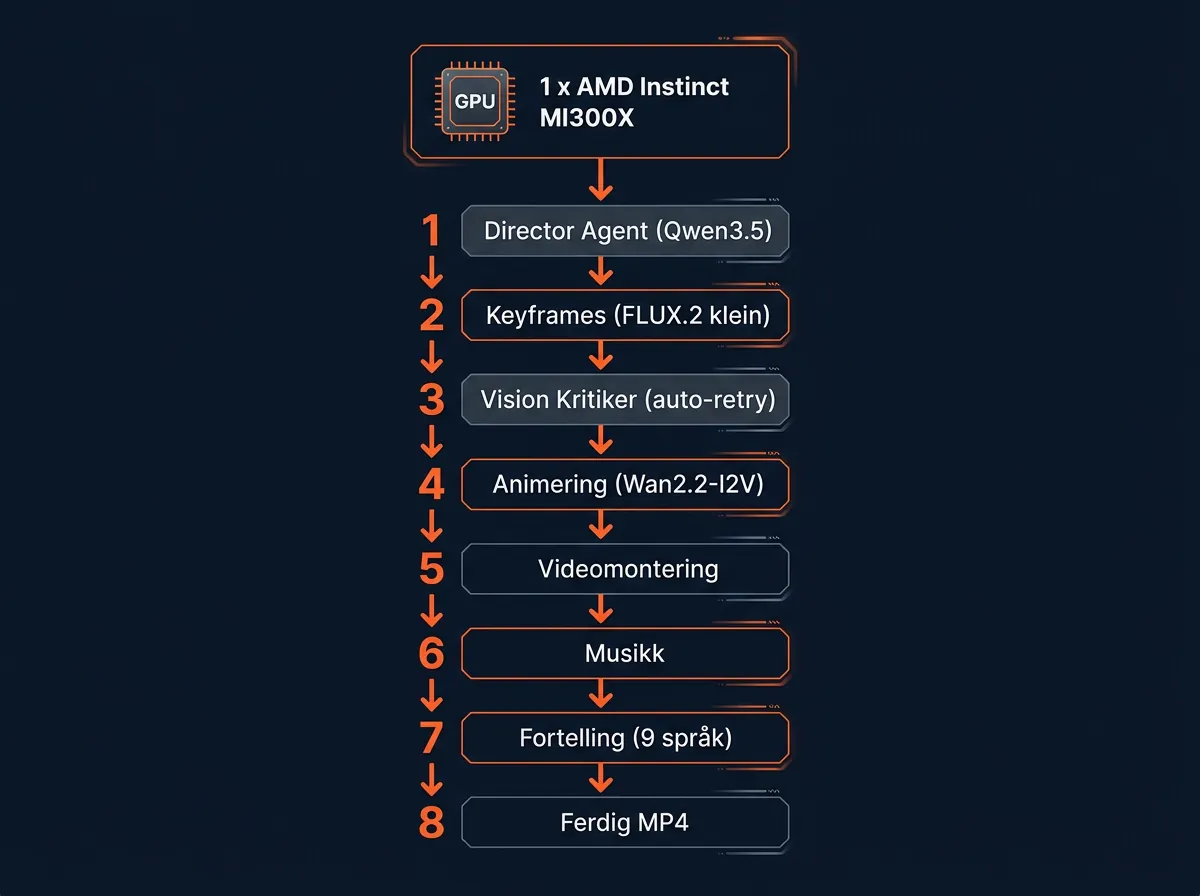
Hva er de åtte stegene i pipelinen?
Pipelinen kjøres sekvensielt – én GPU, ett steg om gangen. Slik ser flyten ut:
Steg 1 – Director Agent (Qwen3.5-35B-A3B via vLLM + AITER MoE): Tar imot én engelsk setning og planlegger seks shots. Returnerer strukturert JSON med karakterbeskrivelser («character bibles»), shotprompts og musikkinstruksjoner. Dette er hjernen i systemet.
Steg 2 – FLUX.2 [klein] for keyframes: Genererer karakterbilder for hvert shot basert på JSON-instruksjonene. FLUX.2 klein er den raske, effektive varianten fra Black Forest Labs – optimalisert for iterasjon med god hastighet-til-kvalitet-ratio. Sub-10-sekunders generering per bilde.
Steg 3 – Vision Critic med auto-retry: Et visionssystem evaluerer hvert keyframe mot karakterbiblene fra steg 1. Hvis et bilde ikke holder mål, kjøres det automatisk på nytt. Denne feedback-loopen er det som skiller dette fra enkle batch-scripts.
Steg 4 – Wan2.2-I2V for animering: Image-to-video-modellen tar keyframes og animerer dem til videosegmenter. Wan2.2 er Alibabas open source videomodell – en av de få som faktisk konkurrerer med lukkede alternativer på kvalitet.
Steg 5 – Videoassembling: Segmentene settes sammen til én sammenhengende film.
Steg 6 – Musikk: Musikk genereres basert på instruksjonene fra Director Agent.
Steg 7 – Narrasjon på opptil 9 språk: Voice-over genereres og synkroniseres med videoen. Ni språk i samme pipeline.
Steg 8 – Final render: Alt settes sammen til én ferdig MP4.
Hvorfor er AMD Instinct MI300X interessant her?
Det meste av open source AI-arbeid skjer på Nvidia-hardware. CUDA-økosystemet har en nesten uovertruffen markedsposisjon, og de fleste tutorials, repos og modeller er skrevet med Nvidia i tankene.
Dette prosjektet ble bygget spesifikt for AMD x lablab-hackathonen – altså for AMD Instinct MI300X. Det er et bevisst valg om å vise at det faktisk fungerer på AMD-hardware, og at alternativet til Nvidia-monopolet eksisterer.
MI300X er AMDs kraftigste AI-akselerator, med 192 GB HBM3-minne. Det er mye minne – nok til å kjøre en 35-milliarders-parametersmodell (Qwen3.5-35B) pluss FLUX.2 pluss Wan2.2 på samme brikke uten å bytte mellom GPU-er. Det er trolig grunnen til at pipelinen er «sequential on the same GPU» og ikke krever en klynge.
Jan Sverre Bauge har tidligere skrevet om Metas massive AMD-kjøp – 100 milliarder kroner i AMD-brikker. Det signalet er nå to år gammelt, og vi begynner å se resultater i form av prosjekter som dette.
Hva er FLUX.2 [klein]?
FLUX.2 er andre generasjon av Black Forest Labs’ bildegenereringsmodell – etterfølgeren til FLUX.1 som satte ny standard for open source bildegenerering i 2024. Familien har fire varianter: max, pro, flex og klein.
Klein (tysk for «liten») er den raske varianten. Den er ikke laget for absolutt toppkvalitet – den er laget for rask iterasjon med høy hastighet-til-kvalitet-ratio. For en pipeline som skal generere seks keyframes i sekvens, er det riktig valg. Pipelinen trenger bilder som er gode nok til å fungere som keyframes for Wan2.2, ikke bildene som skal stå alene i et galleri.
Jeg har tidligere skrevet grundig om FLUX.2-familien og hva den faktisk kan – les den for en dypere gjennomgang av variantene.
Wan2.2-I2V – open source video som faktisk holder
Wan2.2 er Alibabas open source videomodell. I2V-varianten (Image-to-Video) tar et stillbilde og animerer det til et videosegment. Det er teknologisk krevende – modellen må forstå scenens dybde, belysning og bevegelse fra ett enkelt referansebilde.
Wan-modellserien har gjort det bra på åpne benchmarks. For den som er interessert i hva open source videomodeller faktisk kan i dag, er det verdt å se på den komplette guiden til AI-videogenerering. Kortversjonen: open source har kommet til et punkt der det konkurrerer seriøst med betalte alternativer for mange brukstilfeller.
Det som er nytt med dette prosjektet er ikke Wan2.2 isolert sett – det er at den er koblet inn i en full produksjonspipeline med automatisk kvalitetskontroll.
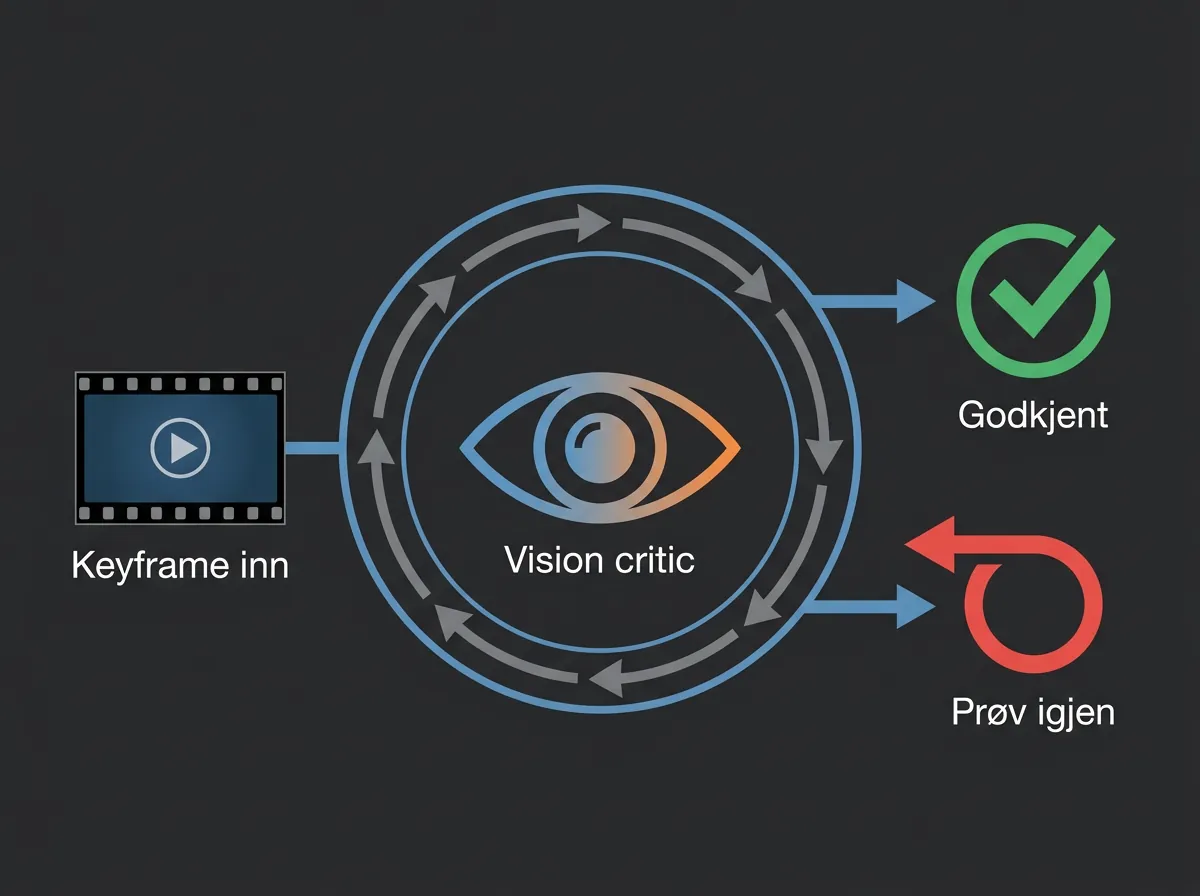
Hva betyr Vision Critic med auto-retry?
Det er dette steget som skiller pipelinen fra et vanlig script. Mange AI-pipelines er «fire and forget» – de genererer, og resultatet er resultatet. Her er et visionssystem innebygd som faktisk sjekker om det genererte bildet matcher karakterspesifikasjonene fra Director Agent.
Hvis karakteren i keyframen ikke stemmer overens med karakterbibelen – feil hårfarge, feil klær, feil setting – kjøres generasjonen om igjen automatisk. Det er en feedback-løkke som gjør systemet mer robust uten menneskelig inngripen.
Konseptet ligner på det som er dekket i ComfyUI-artikkelen – arbeidsflytbasert AI der nodene kan kobles til hverandre for selvkorrigerende prosesser. Her er det implementert på et høyere abstraksjonsnivå med en LLM som Director og et visionssystem som kvalitetskontrollør.
Hva er Apache 2.0 og MIT-lisens, og hvorfor er det viktig?
Alle modellene i pipelinen har enten Apache 2.0 eller MIT-lisens. Det betyr:
- Du kan bruke dem kommersielt uten å betale lisensavgifter
- Du kan modifisere dem og bygge egne versjoner
- Du kan distribuere produkter bygget på dem
- Ingen «call home», ingen bruksrapportering til leverandøren
Dette er i skarp kontrast til mange kommersielle AI-videotjenester der du betaler per minutt generert innhold og leverandøren eier serverne, dataene og infrastrukturen. Her eier du hele stacken.
For den som er interessert i hva open source-lisenser faktisk betyr for AI-bruk, gir guiden til open source AI i 2026 god oversikt over de ulike lisenstypene og hva de tillater.
45 minutter – er det raskt eller tregt?
45 minutter for en ferdig cinematic reel med karakterer, story, musikk og voice-over på ni språk – på én GPU. Det er et relevant spørsmål å stille.
Sammenlignet med å lage det manuelt – skriving av manus, karakterdesign, animering, musikk, innlesing, oversettelse og synkronisering – er 45 minutter ekstremt raskt. Det er jobb som ville tatt et lite produksjonsteam dager.
Sammenlignet med sanntid er det selvfølgelig tregt. Men dette er ikke en sanntidsapplikasjon. Det er en batchpipeline for å produsere ferdig innhold automatisert. For den brukssaken er 45 minutter på én GPU et gjennombrudd.
Det er også verdt å merke seg at dette er på én AMD Instinct MI300X – en server-GPU. Ikke en konsument-GPU. Det er ikke en pipeline du kjører hjemme på en gaming-PC. Men den kan kjøres på leide GPU-ressurser fra RunPod eller tilsvarende, som gjør kostnadsregnestykket interessant for produksjonsbruk.
Hva kan du faktisk bruke dette til?
Pipelinen er åpen kode fra en hackathon – den er ikke et ferdig produkt. Men konseptet peker mot konkrete brukstilfeller:
Korte eksplainervideoer: Beskriv et konsept på én setning, få en animert forklaring ut. For innholdsproduksjon i skala kan dette spare enormt med tid.
Spillprototyper: Karakterer, scener og narrativ fra én prompt. For spillutviklere som vil teste ideer raskt uten et fullskala produksjonsteam.
Flerspråklig innhold: Nine-language narration i én kjøring er ikke noe du bygger manuelt. For global innholdsproduksjon er dette typen automatisering som faktisk monner.
Reklamemateriell: Konseptvisning for kunder uten å trenge et animasjonsstudio.
Det som er fascinerende her er ikke teknologien isolert sett – de individuelle modellene er kjente. Det er koblingen mellom dem, og særlig Vision Critic-laget som sørger for at output faktisk holder spesifikasjonene. Du kan lese mer om hvordan open source video-AI har utviklet seg i artikkelen om LTX-2 og open source video.
Åpen kode betyr at dette kan bygges videre på. Neste hackathon kan bruke dette som base og legge til bedre modeller, raskere pipeline eller støtte for forbruker-GPU-er. Det er slik open source-fellesskapet faktisk fungerer – og det er derfor lisensvalget her er viktig.
Hva tror du – er 45 minutter raskt nok for produksjonsbruk, eller er det fortsatt for tregt for din arbeidsflyt?








1 kommentar