

Innhold Vis
DramaBox er en open source tekst-til-tale-modell fra Resemble AI som gjør noe de fleste TTS-systemer sliter med: den forstår scenenanvisninger. Prompten styrer ikke bare hva som sies, men hvordan det sies – inkludert latter, sukk, pauser og overganger mellom replikker.
Modellen er bygget på LTX-2.3, Lightricks’ audio-fundament som ble sluppet earlier i år. Det er altså samme LTX-familie som LTX-2 video-modellen, men her er det lyd som gjelder – ikke video. Resemble AI har tatt arkitekturen og fine-tunet den til å bli en ekspressiv talesyntese-motor.
Resultatet er en modell som skiller seg fra alt annet som finnes gratis der ute akkurat nå.
Hva gjør DramaBox annerledes enn andre TTS-modeller?
De fleste TTS-modeller tar tekst inn og spytter tale ut. DramaBox gjør det samme, men med et viktig ekstra lag: du beskriver scenen rundt dialogen. Selve prompten fungerer som et manus med scenenanvisninger, og modellen reagerer på dem.
Promptformatet er todelt. Alt inne i anførselstegn blir uttalt. Alt utenfor er instruksjoner til modellen. Et eksempel kan se slik ut:
A woman speaks with nervous energy, «I’m not sure I can do this.» She takes a long breath. «But I’ll try anyway.» She laughs softly, «Hahaha, what’s the worst that could happen?»
Modellen tolker «takes a long breath» som en pause med hørbart pust. «Laughs softly» gir en dempet latter før neste replikk. Dette er noe VoxCPM2 og OmniVoice ikke håndterer på samme måte – de er sterkere på flerspråklig støtte, mens DramaBox tar et helt annet grep på ekspressivitet.
Det er også verdt å nevne at DramaBox støtter sang og harmoni i tillegg til tale. Det åpner for bruksområder langt utover vanlig voice-over.

Hva krever DramaBox av maskinvaren?
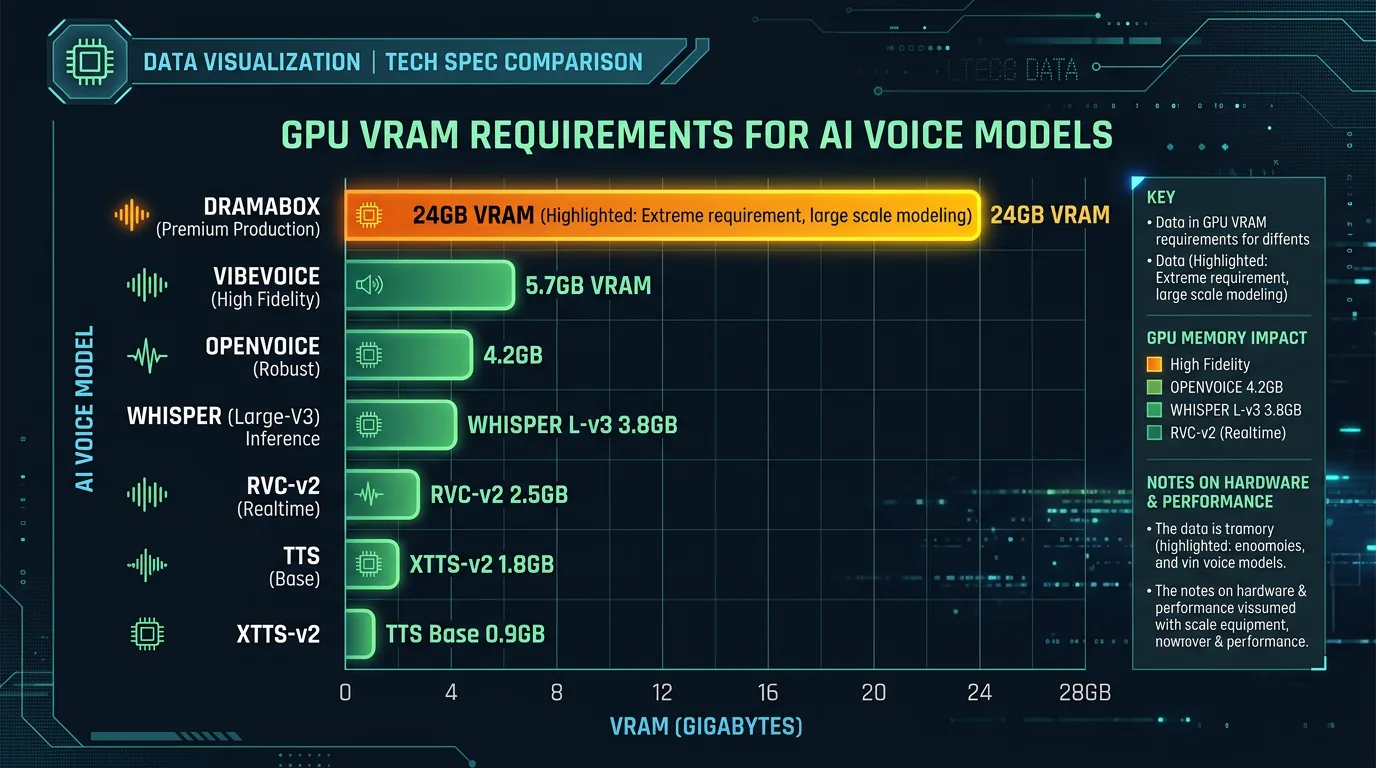
Her er det ingen grunn til å pynte på tallene: DramaBox trenger omtrent 24 GB VRAM på topp. Det betyr i praksis en RTX 4090 (24 GB) eller bedre. Genereringstiden er rundt 2,5 sekunder per replikk på en H100 – raskere hvis du bare har en enkel linje, tregere med lengre scener.
Modellfilene fordeler seg slik:
- DiT transformer: 6,6 GB
- Audiokomponenter: 1,9 GB
- Tekst-encoder (Gemma 3 12B, kvantisert): ca. 8 GB
Til sammenligning krever VibeVoice bare 5,7 GB VRAM. DramaBox er ikke for folk med mellomklasse-GPU. Den er for de som vil ha det beste og har maskinvaren til det.
Trenger du noe lettere, er Flare TTS et interessant alternativ på 28 millioner parametere – dramatisk mer tilgjengelig, men uten samme ekspressive kontroll.
Hvordan fungerer stemmekloning i DramaBox?
Stemmekloning er valgfritt, ikke obligatorisk. Du kan kjøre DramaBox uten noe referanseklipp i det hele tatt – da velger modellen en stemme basert på beskrivelsen i prompten. Vil du klone en spesifikk stemme, holder det med et lydklipp på 10 sekunder eller mer.
Dette er bemerkelsesverdig lavt. Chatterbox – en annen open source stemmeklone-modell – er sammenliknbar her, men DramaBox legger til scenenanvisningslaget på toppen. Det er kombinasjonen som gjør den interessant.
I koden ser det slik ut:
python src/inference.py \
--prompt 'A man speaks calmly, "This is an automated message." He pauses. "Please hold."' \
--voice-sample my_voice.wav \
--output result.wav \
--cfg-scale 2.5 --stg-scale 1.5Parameteren cfg-scale styrer hvor strengt modellen følger prompten (standard 2,5). stg-scale påvirker den ekspressive vekten (standard 1,5). Skrur du stg-scale opp, blir stemmen mer dramatisk – det gir mening gitt modellens navn.
Vannmerking og lisens – hva må du vite?
Alle lyder DramaBox genererer, merkes automatisk med Resemble Perth-vannmerking. Dette er et usynlig digitalt vannmerke som overlever MP3-kompresjon og lydredisjon. Resemble AI bygger dette inn som standard, og du kan ikke enkelt slå det av.
Lisensen er LTX-2 Community License – samme avtale som gjelder for Lightricks’ grunnmodell. Det er ikke MIT eller Apache, men en community-lisens som tillater ikke-kommersiell og viss kommersiell bruk. Les lisensen nøye hvis du planlegger å bruke DramaBox i et kommersielt produkt.
Modellen er kun trent på engelsk, så forvent ikke norsk støtte med det første. For norsk TTS er VoxCPM2 og OmniVoice fortsatt mer relevante alternativer – selv om de taper på ekspressivitet.
Hvem er DramaBox laget for?
Den åpenbare målgruppen er folk som lager innhold med kunstige stemmer – podcaster, YouTube-videoer, spill, audiobooks, kortfilmer. Stemmekloning kombinert med dramatisk kontroll er et kraftig verktøy for innholdsproduksjon der du vil ha full kontroll over leveransen.
Spillutviklere har spesielt mye å hente her. NPC-dialog som reagerer på scenen rundt seg – en karakter som snakker med nervøs energi i en kampscene, eller rolig og selvsikker i en avslappet dialog – er akkurat det DramaBox er bygget for. Og siden modellen er open source og kan kjøres lokalt, slipper du dyre API-kostnader fra tjenester som ElevenLabs (som koster fra 200-500 kr/mnd for kommersielle planer).
Det er verdt å sjekke HuggingFace Space-demoen først hvis du ikke har 24 GB VRAM klar. Der kan du prøve modellen i nettleseren uten installasjon. Koden og modellen ligger åpent på GitHub.
Open source TTS-feltet beveger seg fort. Det som er imponerende med DramaBox er ikke primært lydkvaliteten isolert sett – det er at den smelter manusets form inn i selve talesyntesen. Det er et konseptuelt hopp fra det meste som finnes akkurat nå, og jeg er nysgjerrig på hvor dette ender.







