

Innhold Vis
LoRA-trening har alltid vært mer komplisert enn det trenger å være. Kohya SS er standarden de fleste bruker – men åpner du det første gang, møter du et grensesnitt med faner, underfaner og innstillinger som strekker seg så langt øyet rekker. Anima TrainFlow prøver noe annet: alt på én side, alt du faktisk trenger, ingenting du ikke trenger.
Verktøyet er laget spesifikt for Anima 2B – en open source bildegenererende modell i kategorien diffusion-baserte systemer – og er optimalisert for å kjøre på hardware de fleste faktisk eier. 6GB VRAM er minimumet. Det betyr at en RTX 3060, en RTX 4060, eller tilsvarende er nok til å komme i gang.
Prosjektet dukket opp på Reddit under r/StableDiffusion og skapte umiddelbart interesse fordi det treffer et reelt problem: «tab-fatigue», som noen kaller det. Du sitter foran Kohya, glemmer ett avkrysningsboks gjemt under Networks-fanen, og timer med GPU-tid gikk til spille. Anima TrainFlow vil løse akkurat det problemet.
Hva er egentlig LoRA-trening?
Hvis du er ny på dette: LoRA står for Low-Rank Adaptation, og er en metode for å lære en AI-bildemodell å gjenkjenne et spesifikt utseende, stil eller objekt uten å trene hele modellen på nytt. Du gir den 10-30 bilder av det du vil lære den, og etter noen hundre treningssteg kan modellen generere nye bilder i den stilen – eller med det ansiktet, den figuren, eller det motivet.
Det er kraftig teknologi, men har tradisjonelt krevd at du navigerer verktøy som Kohya SS eller SimpleTuner. Disse er gode, men de er laget for brukere som allerede vet hva de driver med. Anima TrainFlow er laget for resten – og faktisk også for erfarne brukere som er lei av å jakte på den ene innstillingen som kan ødelegge et treningsløp. Du kan lese mer om teknologien bak i AI-ordlisten min der jeg forklarer begreper som LoRA, fine-tuning og diffusion.
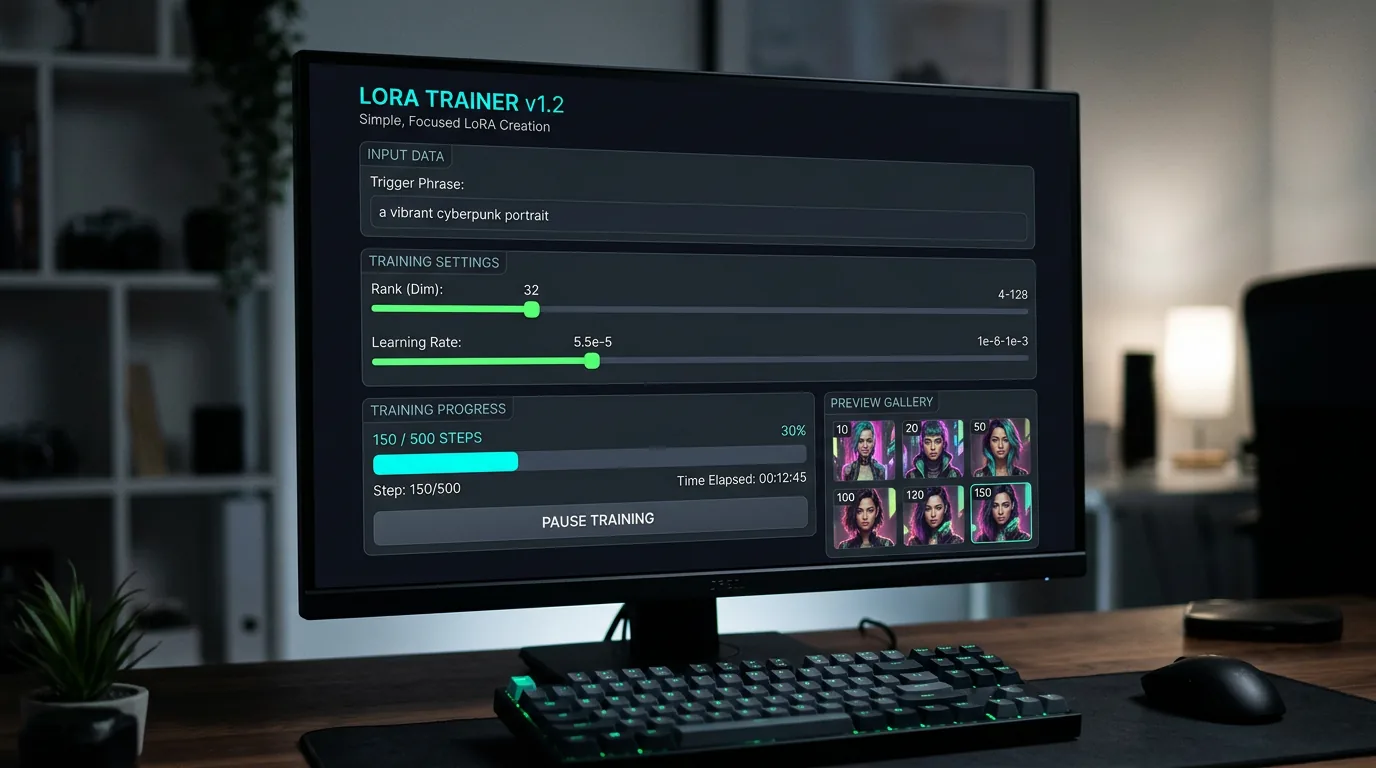
Hva gjør Anima TrainFlow annerledes?
Filosofien er enkel: 80% av parameterne i et LoRA-treningsverktøy er ting du aldri rører. De resterende 20% er det du faktisk endrer fra prosjekt til prosjekt. Anima TrainFlow samler bare de 20% på én side og lar resten håndteres i bakgrunnen med fornuftige standardverdier.
De fire viktigste tingene grensesnittet eksponerer er triggerfrase (det spesielle ordet som aktiverer LoRA-en i prompten din), Rank (kompleksiteten på adapteren, typisk 16-64), læringsrate og antall treningssteg. Det er ikke mer enn det. Ingen nettverksfaner, ingen optimizer-submenyer, ingen dropout-konfigurasjoner du aldri forstod.
I tillegg har verktøyet to funksjoner som faktisk hjelper i praksis:
- Smart datasettanalyse: Verktøyet analyserer bildemappen din automatisk og beregner optimale oppløsninger og bucket-innstillinger. Du slipper å tenke på aspect ratio-matching manuelt.
- Sanntidsforhåndsvisning: Mens treningen kjører, genereres eksempelbilder som oppdateres i galleriet. Du ser om retningen er riktig lenge før treningsløpet er ferdig.
Under panseret er det sd-scripts som faktisk gjør jobben – det samme rammeverket Kohya SS bygger på. Forskjellen er at Anima TrainFlow eksponerer et mye smalere sett av innstillinger via Gradio, og bruker Prodigy-optimalizatoren som håndterer læringsraten adaptivt. Det betyr at du slipper å tune læringsraten manuelt – Prodigy justerer seg selv basert på gradientene underveis.
Hvilke maskinvarekrav stilles?
Her er tallene direkte fra prosjektet:
- VRAM: 6GB minimum (NVIDIA GPU)
- OS: Windows 10/11
- Lagring: ~5GB ledig plass, SSD anbefalt
6GB VRAM er et godt sted å sette grensen. Det inkluderer RTX 3060, RTX 4060 og mange eldre kort som RTX 2060 Super. Sammenlignet med full modelltrening, som kan kreve 16-24GB VRAM, er LoRA-metoden langt mer tilgjengelig – noe som er hele poenget med teknologien. Jeg har skrevet om hva du kan gjøre med ulik lokalhardware i artikkelen om Flux 2 og lokal bildegenerering.
Verktøyet er Windows-only, noe som er en begrensning for Linux-brukere. Mac støttes ikke – det er ikke overraskende siden Prodigy-optimalizatoren og sd-scripts-rammeverket er optimalisert for CUDA, som er NVIDIAs plattform. Apple Silicon har sine egne treningsverktøy (MLX-baserte alternativer), men det er en annen artikkel.
Hvordan installerer du Anima TrainFlow?
Det er to veier inn, og den første er så enkel at det nesten er latterlig sammenlignet med å sette opp Kohya SS manuelt:
Portabel versjon (anbefalt): Last ned 1,7GB-arkivet fra GitHub-repositoriet, pakk det ut med 7-Zip, og kjør start_trainer.bat. Ferdig. Ingen Python-versjonsproblemer, ingen virtuelle miljøer som krangler med andre installasjoner, ingen avhengigheter du må rote med.
Manuell installasjon: Klon repositoriet fra GitHub, kjør Install_Requirements.bat, og deretter start_trainer.bat. Denne er for deg som vil ha full kontroll over hva som installeres.
Datasettforberedelse er minimalt: legg alle treningsbilder i én mappe. Støttede formater er .png, .jpg og .webp. Hvert bilde trenger en tilhørende .txt-fil med samme filnavn som inneholder tags eller bildebeskrivelse. Det er standard LoRA-workflow uansett hvilket verktøy du bruker.
Er Anima TrainFlow for nybegynnere eller erfarne?
Begge deler, men av ulike grunner. For nybegynnere er én-sides-grensesnittet en reell fordel. Det er færre steder å gjøre feil, og Prodigy-optimalizatoren fjerner den vanskeligste variabelen – læringsraten – fra ligningen. Du kan komme i gang med et rimelig resultat uten å forstå alle parameterne.
For erfarne brukere er argumentet annerledes. Noen ganger vil du bare ha et raskt, lavfriks treningsløp uten å sette opp et fullskala Kohya-prosjekt. Anima TrainFlow er det – en dedikert, lettvekts løsning for Anima 2B som ikke prøver å gjøre alt for alle modeller. Det er MIT-lisensiert, altså fullstendig gratis og åpen kildekode.
Begrensningen er at det kun støtter Anima 2B. Trener du på SDXL, Pony, eller nyere arkitekturer som HiDream, må du bruke andre verktøy. Anima TrainFlow er ikke ment å være universell – det er ment å gjøre én ting bra.
Hva er Anima 2B?
Anima 2B er en 2 milliarder parameter diffusjonsmodell spesifikt designet for portrettgenerering og konsistente karakterer. Den er optimalisert for realistiske ansikter og menneskefigurer – noe mange større modeller sliter med. Med bare 2 milliarder parametere er den også langt mer effektiv å kjøre lokalt enn fullskala SDXL-modeller som har betydelig større minnefotavtrykk.
Modellen er interessant fordi den representerer trenden mot spesialiserte modeller fremfor alt-i-ett-løsninger. I stedet for én stor modell som er «OK» på alt, er Anima 2B laget for å være god på én ting. Det er samme tenkning som du finner i fine-tunede språkmodeller – som jeg har skrevet om i artikkelen om fine-tunede modeller som slår frontier-API-er på smale oppgaver.
Kombinasjonen av en spesialisert basemodell (Anima 2B) og et dedikert treningsverktøy (TrainFlow) er fornuftig. Det er en helhetlig tilnærming til å gjøre personlig LoRA-trening tilgjengelig for folk med vanlig forbrukerhardware – og det er den typen open source-utvikling det er verdt å følge med på.







