

Innhold Vis
En ny teknikk lar deg styre hva FLUX.2 genererer ved å gi den referansebilder i stedet for å trene en LoRA. Samme prompt, samme seed – bytt ut referansebildene, og farger, stil og struktur endrer seg. Ingen treningsdata, ingen GPU-timer, ingen adapter-filer å holde styr på.
Metoden heter «Follow the Mean» og er basert på et nytt vitenskapelig paper om referansestyrt flow matching. En utvikler satte opp en åpen HuggingFace-demo som viser konseptet i praksis, og etter å ha lest paperet forstår jeg hvorfor dette er interessant – spesielt for de av oss som har kjørt nok LoRA-treningsrunder til å bli lei.
La meg gå gjennom hva som faktisk skjer under panseret, og hva det betyr i praksis.
Hva er «Follow the Mean» og hvordan fungerer det?
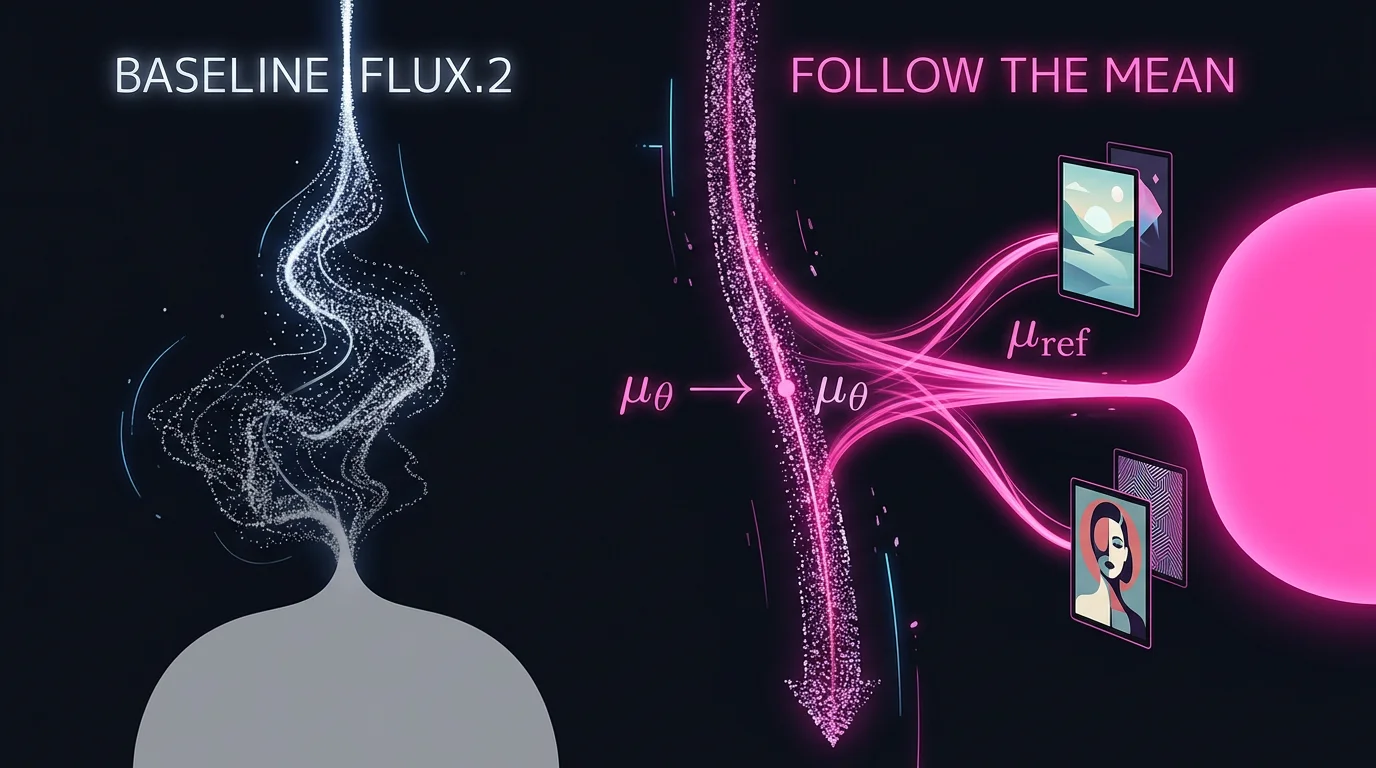
Flow matching-modeller som FLUX.2 genererer bilder ved å starte med støy og bevege seg mot et sluttpunkt. Det er nettopp sluttpunktet metoden manipulerer. I stedet for å endre modellvektene gjennom trening, justerer «Follow the Mean» hva modellen peker mot under selve genereringen.
Teknisk sett beregnes et gjennomsnitt av referansebildene som et endpoint mean, og deretter legges en korreksjon til hastighetsfeltet som trekker genereringen i den retningen. Formelen ser slik ut:
u_guided = u_theta + beta * (mu_ref - mu_theta) / (1 - t)
Der mu_ref er referansebildenes gjennomsnittlige endepunkt og mu_theta er hva modellen ellers ville landet på. beta styrer hvor sterkt referansebildene påvirker – lav tidlig i genereringen, høyere mot slutten. Beregningskostnaden er ifølge paperet på 1,02x sammenlignet med vanlig generering – altså tilnærmet ingenting ekstra.
FLUX.2-klein-modellen (4 milliarder parametere) holdes helt frossen gjennom hele prosessen. Ingenting lagres, ingenting trenes.
Hva skjer når du bytter referansebilder?
Paperet demonstrerer dette med et konkret eksempel: promoten «elephant in a jungle». Med baseline FLUX.2 får du en grå elefant i grønn skog – akkurat det du ville forvente. Legg til 20 bilder av rosa plastleketøy-elefanter som referanse, og elefanten i bildet blir rosa. Bytt til bilder av blå elefanter – blå elefant. Jungelen rundt er uendret gjennom hele sekvensen.
Referansebildene trenger ikke å matche prompten på noe vis. De trenger ikke engang å være høykvalitetsbilder. Paperet slår fast at «any reference set R that shifts the endpoint mean in the right direction works» – selv tematisk løst relaterte bilder fungerer så lenge de peker farger, teksturer eller komposisjon i riktig retning.
På GenEval-benchmark øker metoden posisjonskontroll med 28,75 poeng sammenlignet med baseline FLUX.2 – et område der tekstprompter tradisjonelt gjør det dårlig. Til sammenligning krever gradient-baserte metoder som oppnår lignende resultater 4-19 ganger mer beregning.
Hva er forskjellen fra LoRA?
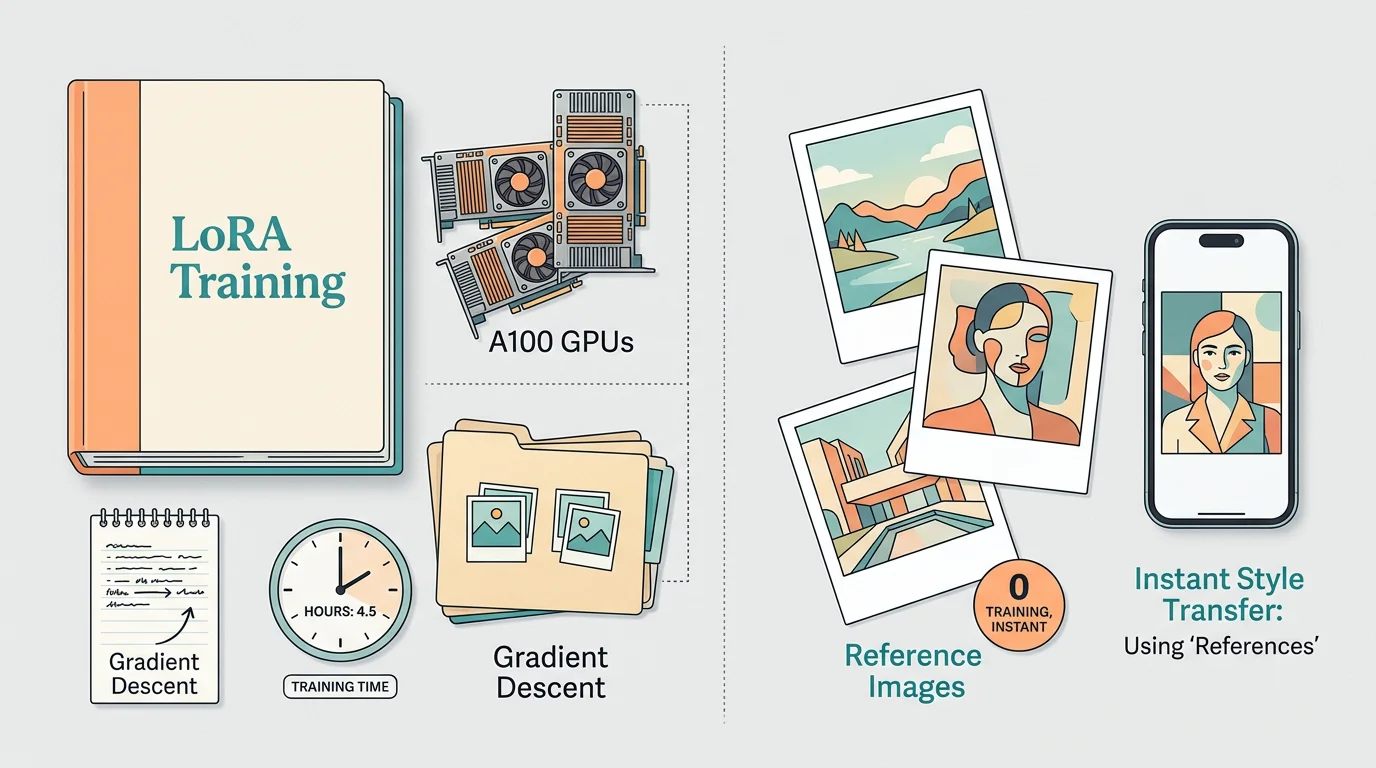
LoRA-trening er standard metode for å spesialisere bildegenererende modeller mot en bestemt stil eller person. Du samler treningsbilder, kjører en treningsprosess på GPU, og ender opp med en adapter-fil som lastes inn ved generering. Det fungerer godt, men det koster tid og ressurser – og hver ny stil krever en ny adapter.
«Follow the Mean» gjør ingen av disse tingene:
- Ingen treningsdata som må samles inn og klargjøres
- Ingen GPU-tid til trening – bare normal genereringstid
- Ingen adapter-filer å lagre, versjonere eller distribuere
- Du kan bytte referansesett midt i en sesjon uten å laste noe nytt
Ulempen, sammenlignet med en godt trent LoRA, er at kontrollen er mer generell. LoRA kan lære seg spesifikke ansikter, veldig spesifikke stiler, eller komplekse komposisjoner med høy presisjon. «Follow the Mean» styrer bredere attributter – farge, generell stil, strukturelle mønstre. Det er en avveiing mellom fleksibilitet og presisjon.
For deg som vil eksperimentere raskt uten treningsbyrden er det likevel en stor fordel. Dette passer godt for konseptutvikling, moodboards og iterering på stil – situasjoner der du vil prøve mange retninger raskt. Jeg har skrevet om FLUX.2 tidligere og satt stor pris på friheten i modellen – dette er en naturlig forlengelse av den friheten.
Hvordan prøver du demoen?
HuggingFace-demoen kjører på Zero – det vil si gratis GPU-tid fra HuggingFace, som betyr at den kan stå kø eller kreve litt tålmodighet i rushtiden. Du laster opp et knippe referansebilder, skriver en prompt, og kjører genereringen. Koden og paperet er begge åpent tilgjengelig under Apache 2.0-lisensen.
Implementeringen bruker diffusers-biblioteket med en callback på Flux2KleinPipeline. Det vil si at metoden ikke er avhengig av noe proprietært – du kan i prinsippet sette dette opp lokalt om du har litt Python-erfaring og en halvgrei GPU. GitHub-repoet er en god startplass.
Teknologien er basert på paper på arXiv (2605.10302) og selve demoen finner du på HuggingFace. Det er verdt å teste bare for å se referansebytte-effekten i praksis.
Hva betyr dette for bildegenerering fremover?
Det interessante med denne typen treningsfri kontroll er at den gjør bildegenerering mer tilgjengelig for folk som ikke vil sette seg inn i LoRA-treningspipelines. Du trenger ikke ComfyUI-workflows, GPU-tid eller kunnskap om hyperparametere. Du drar inn noen referansebilder og er i gang.
Open source-feltet rundt bildegenerering beveger seg raskt i denne retningen generelt. HiDream-O1 viste nylig at du kan fjerne VAE-flaskehalsen helt, og nå ser vi altså teknikker som fjerner treningsbehovet for stilkontroll. Det ser ut til at mye av magien fremover vil skje ved inferenstid – ikke ved treningsstadiet.
For de som bygger produksjonssystemer for bildegenerering er referansebasert kontroll en interessant retning. I stedet for å vedlikeholde ett LoRA-bibliotek per stil, kan du potensielt jobbe med referansebanker som oppdateres dynamisk. Det er en annen arbeidsflyt, men en som skalerer mer naturlig.
Metoden er per nå demonstrert på FLUX.2-klein (4B parametere). Det gjenstår å se hvordan den skalerer til større modeller og mer krevende brukstilfeller – men starten er lovende. Oversikten min over beste AI-verktøy i 2026 har mer om hva som faktisk funker i praksis, om du vil ha et bredere perspektiv.
Kort sagt: dette er en teknikk som senker terskelen for stilkontroll i bildegenerering uten å kreve trening. Det er åpen kode, åpent paper, og en fungerende demo du kan prøve nå. Kombinert med de åpne video-pipelines jeg har skrevet om, begynner bildet av en fullt åpen kreativ AI-pipeline å ta form.







