
Innhold Vis
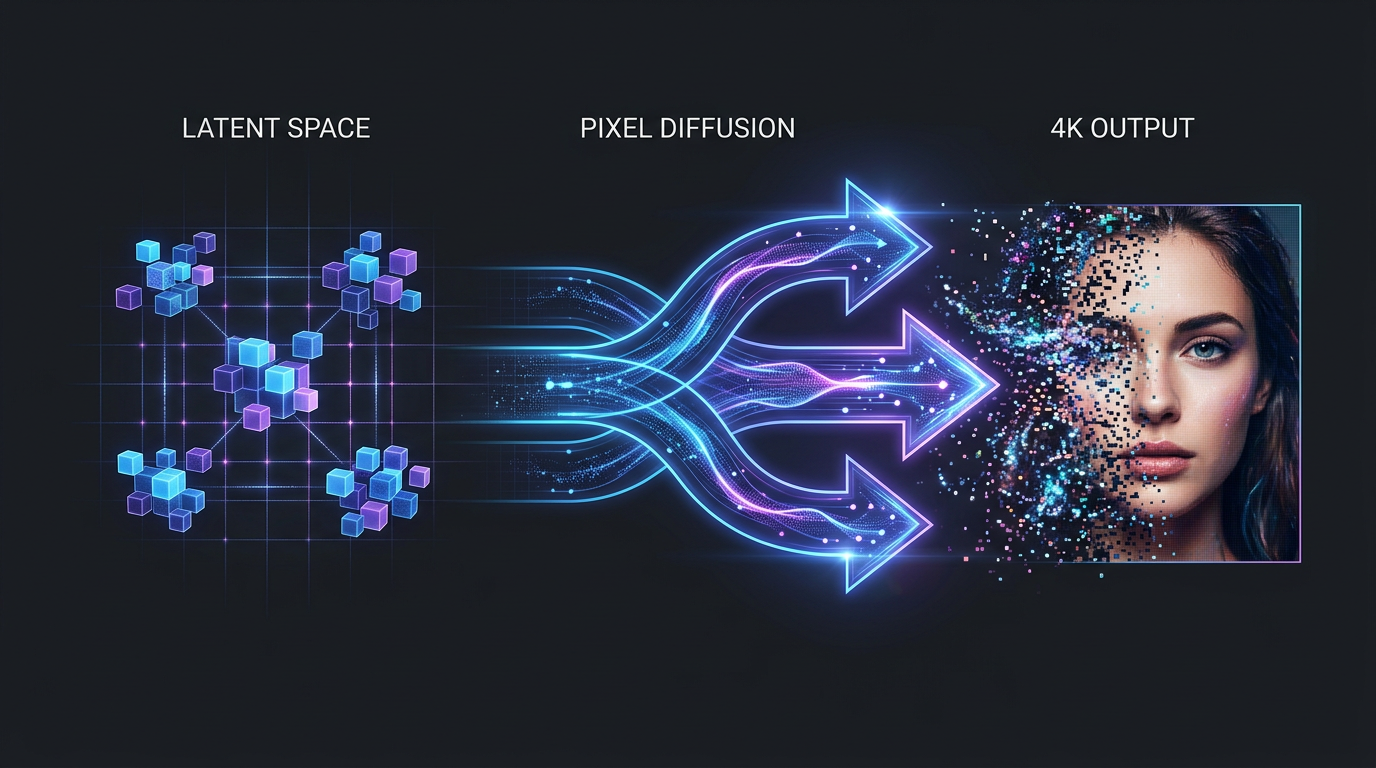
VAE har vært flaskehalsen i AI-bildegenerering lenge nok. Nvidia Research har nå lansert PiD – Pixel Diffusion Decoder – en helt ny tilnærming til latent decoding som kombinerer dekoding og oppskaling til ett enkelt trinn, og gjør det 6 ganger raskere enn konkurrentene.
Prosjektsiden til Nvidia beskriver PiD som en modell som «reformulerer latent decoding som betinget pikseldiffusjon». I praksis betyr det at steget der latente representasjoner konverteres til faktiske piksler – det steget du aldri tenker på, men som alltid er der – nå kan gjøres generativt og med mye høyere kvalitet enn med tradisjonell VAE.
Resultatene er imponerende på papiret. Men la meg ta deg gjennom hva PiD faktisk er, hva som gjør det annerledes, og hvorfor dette potensielt er et av de mer interessante tekniske bidragene fra Nvidia på bildesiden.
Hva er VAE, og hvorfor er det et problem?
En Variational Autoencoder (VAE) er komponenten i diffusjonsmodeller som oversetter mellom pikselrom og latentrom. Når en modell som Flux eller Stable Diffusion genererer et bilde, skjer selve diffusjonsprosessen i et komprimert latentrom. VAE er broen – den koder bildet ned til latenter, og dekoder det tilbake til piksler du kan se.
Problemet med VAE er at dekodingsprosessen er deterministisk og enkel. Det gir rimelig gode resultater på normal oppløsning, men begynner å stre med detaljer, fine teksturer og høy oppløsning. Du har sikkert sett artefakter – litt ujevne kanter, rar hud, eller tekst som ser ut som krusull. Mye av det skyldes VAE-steget. SenseNova U1 prøvde å løse dette ved å droppe VAE helt, noe som er en mer radikal tilnærming.
PiD tar en annen vei: behold latentrepresentasjonene, men gjør selve dekodingen generativ.
Hvordan fungerer Nvidia PiD?
PiD bruker en latent-betinget pikseldiffusjonsmodell som predikerer hastighetsfelt direkte i måloppløsningen. I stedet for å bare «avkode» latentene til piksler, bruker PiD dem som betingelse for en diffusjonsprosess som genererer det endelige bildet i full oppløsning.
Tre nøkkelelementer gjør dette mulig. Først er en sigma-bevisst adapter som injiserer støyforurensede latenter på riktig tidspunkt i diffusjonsprosessen. Deretter støtte for tidlig avslutning – PiD kan ta over fra basediffusjonsmodellen midt i prosessen, ikke bare på slutten. Og til sist: distillering via DMD2-teknikken, som reduserer antall nødvendige inferenstrinn til fire.
Fire trinn for å dekode til 2K eller 4K. Det er ikke mye. Og det gir gode tall: 512×512 til 2048×2048 på en RTX 5090 tar under ett sekund. På en GB200-klasse GPU kommer det ned i 210 millisekunder. Sammenlignet med SeedVR2 – en av de raskere kaskaderte SR-metodene – er PiD opptil 5,9 ganger raskere (211 ms vs 1238 ms) ifølge Nvidias egne tall fra arXiv-preprint 2605.23902.
Hvilke modeller støtter PiD?
PiD er ikke låst til én arkitektur. HuggingFace-kortet lister følgende støttede backboner:
- Flux1-dev (16-kanals VAE)
- Flux2-dev (128-kanals BN VAE) – Flux 2 er en av de sterkeste modellene akkurat nå
- SD3 Medium (16-kanals VAE)
- DINOv2-B + RAE ViT-XL
- SigLIP-2 So400M + Scale-RAE ViT-XL
Det finnes to checkpoint-varianter per backbone. «2k»-varianten skalerer fra 512 til 2048 piksler (4× eller 8× oppskaling). «2kto4k»-varianten tar deg videre til 3840 piksler, effektivt 4K output fra en 1024-piksel LDM. Alle sjekkpunkter er 4-trinn distillert – du trenger ikke konfigurere noe spesielt for effektiv inferens.
Hva er lisensbegrensningene?
Her må jeg være direkte: PiD er ikke open source på vanlig vis. Lisensen er «NVIDIA Internal Scientific Research and Development Model License», og det betyr konkret at du ikke kan bruke modellen i produksjonsmiljøer, ikke distribuere den, ikke deploye den kommersielt, og ikke bruke den til å generere verk for salg.
Det er med andre ord en forskningsmodell. Du kan laste den ned og eksperimentere lokalt, men du kan ikke slenge den inn i tjenesten din og fakturere kunder for det. Det er en viktig distinksjon.
Dette er ikke uvanlig for Nvidia Research-prosjekter. De publiserer mye interessant arbeid som teknisk demonstrasjon, men holder de beste bitene for eget bruk eller lisensiert distribusjon. NemoClaw var et lignende eksempel – imponerende teknisk, men Nvidia kontrollerer hva det brukes til.
Hva skiller PiD fra andre forsøk på å erstatte VAE?
Det har vært flere prosjekter som prøver å løse det samme problemet. HiDream O1 gikk til pikselrom direkte, og SenseNova U1 droppet diffusjonssteget delvis. Det er også kaskaderte super-resolusjon-pipelines som RealESRGAN og SeedVR2 som forbedrer output etter generering.
PiD er annerledes fordi det ikke er et post-processing-steg. Det integreres direkte i diffusjonsprosessen og kan ta over fra basediffusjonsmodellen underveis, ikke bare etterpå. Det betyr at konteksten fra diffusjonsprosessen bevares, og at modellen ikke må gjette seg til hva den «skulle ha vært» – den vet det allerede fordi den var med på det.
Støtten for semantiske latenter (SigLIP, DINOv2) er også interessant. Det betyr at PiD potensielt kan brukes med modeller som ikke er tradisjonelle diffusjonsmodeller i det hele tatt – noe som peker mot bredere anvendelse enn bare Flux og SD3. Mercury 2 er et eksempel på at diffusjon beveger seg inn på stadig nye områder, og PiD passer godt inn i den trenden.
Kan du bruke PiD nå?
Ja, teknisk sett. Modellen ligger tilgjengelig på HuggingFace under nvidia/PiD, og prosjektsiden hos Nvidia Research viser eksempler og gir instruksjoner for inferens. Du trenger Python, de riktige avhengighetene, og et sjekkpunkt som matcher den LDM-modellen du vil bruke.
Kommandolinjeeksempelet på HuggingFace ser slik ut:
PYTHONPATH=. python -m pid._src.inference.from_ldm_flux \
--prompt "A photorealistic cat" \
--ldm_inference_steps 28 \
--pid_inference_steps 4 \
--scale 4 \
--output_dir ./results/demoDet er ikke pek-og-klikk. Men det er heller ikke rakettvitenskap hvis du er vant til å kjøre diffusjonsmodeller lokalt. Legg til --pid_ckpt_type 2kto4k for 4K-output.
Grensen er lisensen. Forskning og eksperimentering er grønt lys. Produksjon og kommersiell bruk er rødt lys – og det gjelder selv om du teknisk sett får det til å fungere.
Nvidia vet hva de har her. Om PiD – eller noe basert på den samme teknikken – dukker opp i kommersielle tjenester som Nvidia AI Enterprise eller som API-tjeneste, blir det interessant å se hva prislappen er. Teknologien er der. Spørsmålet er bare hvem som får bruke den til hva.







