

Innhold Vis
Hva skjer når en utvikler er lei av framework-overhead og bestemmer seg for å skrive sin egen AI-motor fra bunnen i C++? Resultatet er en open source inferensmotor som kjører en multimodal AI-modell på et Orange Pi AIPro-kort til rundt 1 500 kroner – med 5,90 tokens per sekund og ingen avhengighet av PyTorch.
Prosjektet dreier seg om å kjøre MiniCPM-V 4.6 direkte på Ascend 310B NPU-en innebygd i Orange Pi AIPro. Ikke via Ollama, ikke via llama.cpp – en håndskrevet C++-motor med egenutviklede operatorer tilpasset akkurat denne brikken.
Det er ganske sprekt. Og det er open source.
Hva er Orange Pi AIPro og Ascend 310B?
Orange Pi AIPro er et single-board computer med en Huawei Ascend 310B NPU integrert på kortet. For rundt 149 dollar (ca. 1 500 kroner) får du 20 TOPS INT8 ytelse og 10 TFLOPS FP16 – det er dedikert AI-akselerasjon som ikke finnes på vanlige Raspberry Pi-kort.
Ascend 310B er Huaweis inferensbrikke beregnet på edge-deploy. Den bruker CANN som programvare-stack (Compute Architecture for Neural Networks) og har egne AscendC-operatorer for lav-nivå beregninger. Det er verken CUDA eller ROCm – et helt eget økosystem som krever at du enten bruker Huaweis egne rammeverk eller skriver mot det native API-et.
Det er nettopp det denne utvikleren valgte å gjøre.

Hvorfor skrive en C++-motor i stedet for å bruke eksisterende rammeverk?
Det korte svaret er overhead. Standardmåten å kjøre modeller på Ascend er via torch_npu – PyTorch-integrasjonen for Huaweis NPU. Men PyTorch bringer med seg masse ekstra lag: Python-interpreter, dynamisk graf-bygging, generiske kernel-velgere. For en liten edge-enhet er det mye å bære.
Ved å skrive inferensmotoren direkte i C++ med AscendC custom kernels og aclnn-operasjoner, kan alt tilpasses akkurat den modellen og akkurat den brikken. Ingen generiske tilpasninger, ingen unødvendige abstraksjonslag.
Arkitekturen er tredelt: C++-motoren håndterer all inferens på NPU-en, mens Python kun brukes for tokenisering og bildeforbehandling på CPU-siden. Det gjør at du kan bytte ut Python-delene etter hvert uten å røre kjernekoden.
Modellen som kjøres er MiniCPM-V 4.6 – en multimodal modell med 24-lags hybrid lineær/full attention, 1024 hidden dimensions og et vokabular på 248 000 tokens. Vision-delen er en SigLIP-so400m tower med 27 transformer-lag. Kompakt, men kapabel nok for tekst og bildeanalyse.
Hva er ytelsen på 5,90 tokens per sekund?
Gjennomsnittshastigheten ved single-batch decode endte på 5,90 tokens per sekund – opp fra 2,88 tokens/s ved prosjektstart. Det er omtrent en dobling gjennom tre optimaliseringsfaser. Per-step-latens er nede i ~170ms, og det meste av resterende tid går med til matrisemultiplikasjon og minnebåndbredde.
5,90 tokens per sekund er ikke raskt i absolutt forstand. En konversasjon går på under halvt skritt per sekund fra brukerens perspektiv, og for lange kontekster vil det kjennes tregt. Men det er lokal, offline inferens på maskinvare til 1 500 kroner – uten cloud-kostnader, uten datadeling, og uten internettavhengighet.
Til sammenligning kjører VoiceVoice C++ fra Microsoft lignende rammeverk-frie tilnærminger for tale-AI lokalt – samme prinsipp, annet domene. Poenget er at folk begynner å se at C++-baserte løsninger gir reell ytelsesgevinst fremfor Python-wrappers.
Oppstart etter vektlasting er raskt: ~2 sekunder varmeup, deretter er modellen klar. Det er akseptabelt for edge-bruk.
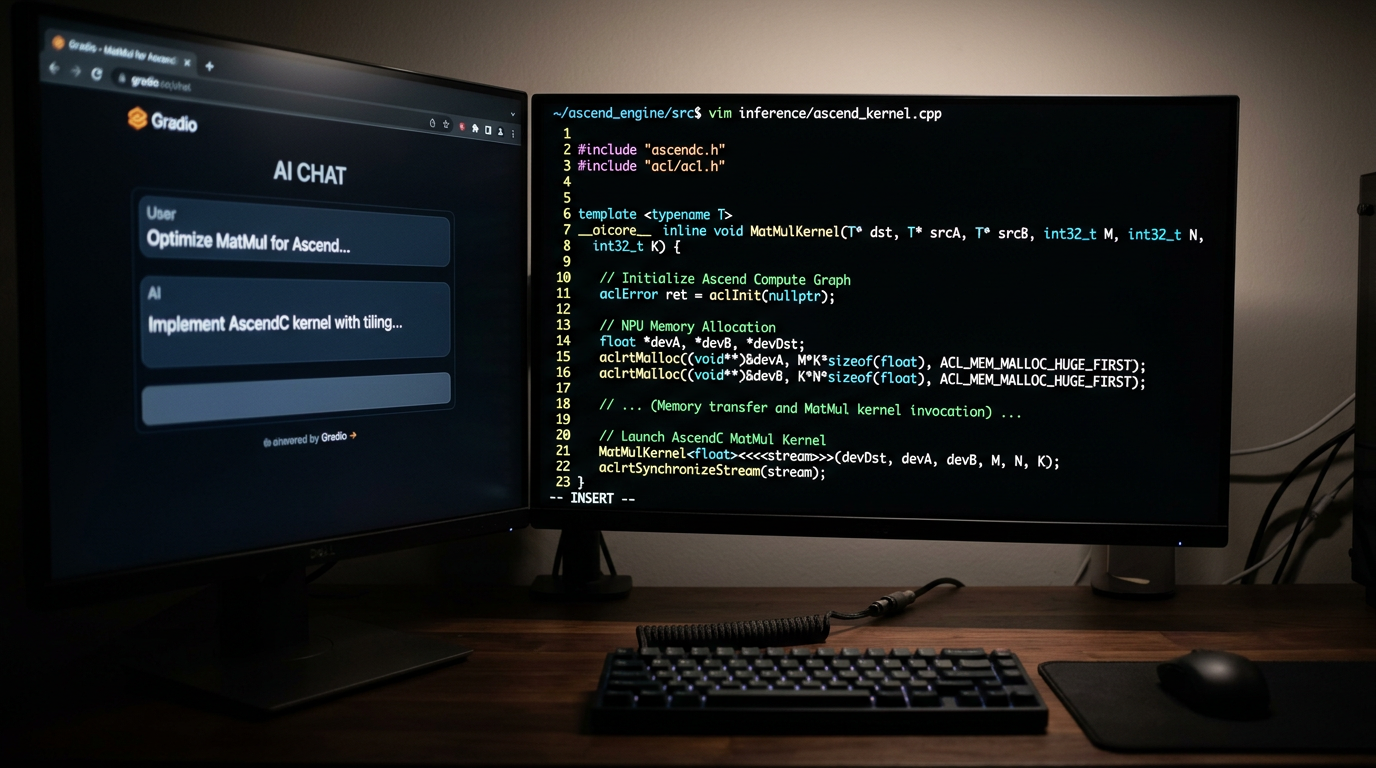
Hva er MiniCPM-V 4.6, og er den nyttig?
MiniCPM-V 4.6 er en kompakt multimodal modell fra OpenBMB som håndterer både tekst og bilder. Den er designet for ressursbegrensede miljøer – det er ikke en 70B-klasse modell, men heller ikke en leke-modell. Vision-tårnet analyserer bilder i 448×448 piksler og koder dem til 64 image tokens som modellen kan resonere rundt.
Praktiske bruksområder på edge-hardware: bildeanalyse av kamera-feed, dokumentbehandling offline, spørsmål-svar om bilder uten å sende data til cloud. For IoT-scenarier der bilder ikke skal forlate bygget, er det nettopp dette man vil ha.
Modellen valideres i prosjektet mot CPU-referanser med maksimal absolutt differanse på 0,0098 for bildefeatures – det er numerisk nøyaktighet som er god nok for praktisk bruk.
Hvordan bygger du prosjektet selv?
Prosjektet ligger åpent på GitHub under Apache 2.0-lisens. Byggesystemet er relativt ryddig: tre skript automatiserer hele prosessen.
Du trenger Ubuntu 22.04 aarch64, CANN 8.3.RC2, CMake 3.20 eller nyere, og Python 3.8+ med transformers og pillow. PyTorch er ikke påkrevd for selve inferensen – bare for tokenisering. Byggetidene er håndterbare: custom operatorinstallasjon tar ~3 minutter, CMake-bygging ~1 minutt.
Gradio-grensesnittet gir deg et chat-UI med strømmende token-generering direkte i nettleseren. Det gjør prosjektet tilgjengelig for testing uten at du trenger å skrive Python-kode selv.
Dette minner om tilnærmingen i Atlas inference engine – der ble Rust og CUDA brukt for å slå vLLM med 131 tokens per sekund på server-hardware. Samme filosofi, annet mål: maksimer det du kan på den brikken du har.
Er dette verdt bryet for deg?
Spørs hva du vil oppnå. Hvis du vil ha enkel lokal AI og bare vil komme i gang, er rammeverk som GAIA fra AMD eller standard Ollama langt enklere å sette opp – Ollama kjører mange modeller rett ut av boksen uten at du trenger å kompilere noe.
Men det er en annen greie å bygge noe som faktisk er tilpasset brikken du har. Dette prosjektet er interessant fordi det demonstrerer at Ascend 310B-plattformen er programmerbar utover Huaweis egne rammeverk. At noen tar seg tid til å skrive AscendC-operatorer fra bunnen, validere mot CPU-referanser og pakke det med en Gradio UI – det senker terskelen for neste person som vil prøve noe lignende.
Og 1 500 kroner for dedikert NPU-maskinvare med åpen kildekode-inferens er et interessant punkt i kostnadskurven. Ikke for alle, men for de som vil ha full kontroll over AI-kjøringen uten å eie et datasenter – eller betale per token til en cloud-leverandør. Se gjerne også på hvordan lokal AI løser GDPR-problemstillinger for bedrifter som ikke kan sende data til sky.








1 kommentar