
Innhold Vis
JetBrains er best kjent for IDE-er som IntelliJ og PyCharm. Nå gir de ut en AI-modell også – og den er ikke laget for å konkurrere med GPT-4o eller Claude. Mellum2 er noe annet: en liten, rask spesialistmodell bygget for å sitte midt i en større AI-pipeline og gjøre én ting veldig godt.
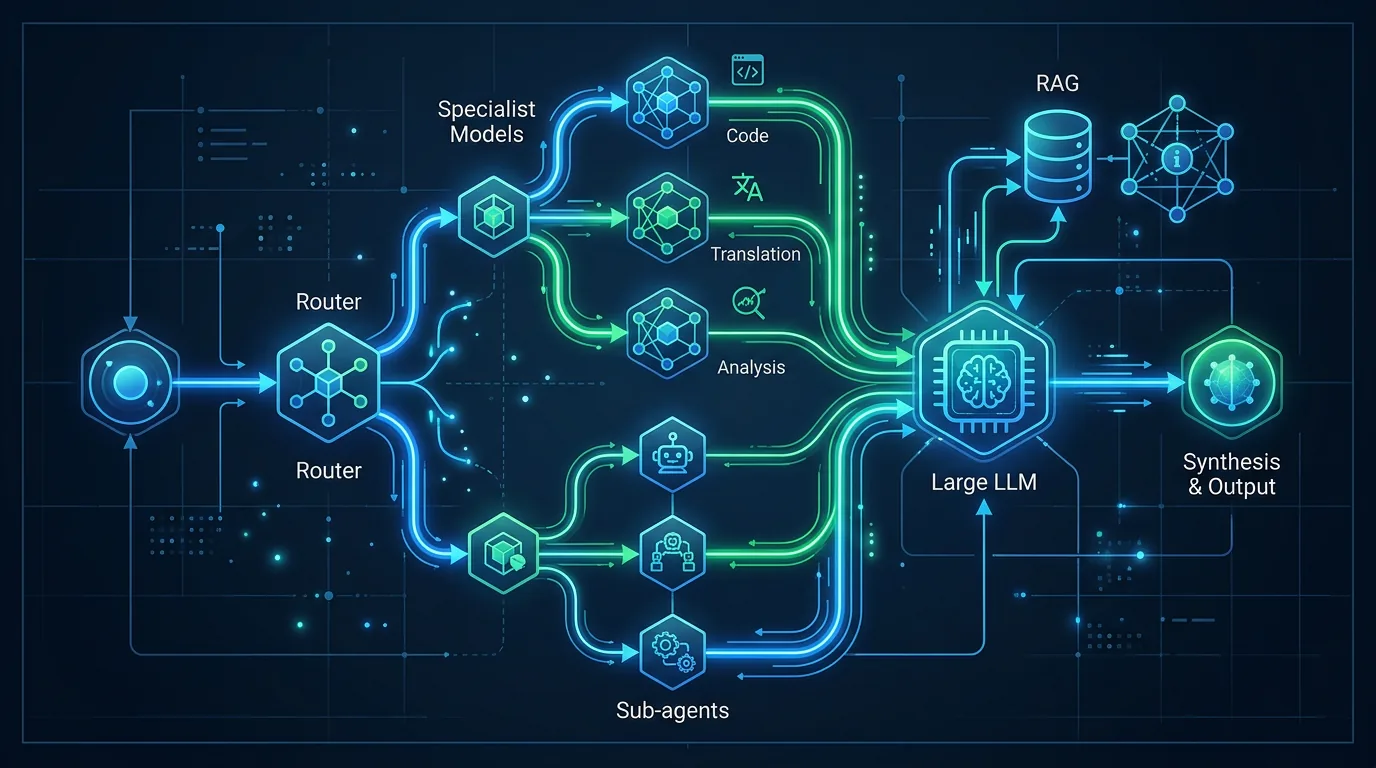
Det høres kanskje ut som en nisje-greie, men ideen bak er faktisk ganske interessant. I stedet for å alltid rute alle spørsmål til en stor, dyr frontiermodell, kan du bruke Mellum2 til de enklere delene – rask kodegjennomføring, RAG-oppsummering, sub-agent-kall – og spare den store modellen til det den faktisk er bedre til.
Modellen er nå tilgjengelig på Hugging Face under Apache 2.0-lisens, som betyr at du kan kjøre den lokalt, selge produkter basert på den, og tilpasse den fritt.
Hva er Mellum2 og hva gjør det annerledes?
Mellum2 er en Mixture-of-Experts (MoE)-modell med totalt 12 milliarder parametere, men bare 2,5 milliarder er aktive per token. Det betyr at modellen oppfører seg som en 2,5B-modell i praksis – rask og billig å kjøre – men med tilgang til 12B parametere totalt som er fordelt over 64 eksperter (8 aktiveres per token).
JetBrains kaller den en «focal model» – tenk på det som en spesialist i et team. Du trenger ikke en overlege til å skrive ut en resept for paracetamol. Mellum2 er resept-skriveren i AI-pipelinen din.
Kontekstvinduet er 131 072 tokens – mer enn nok for de fleste kodebaser. Modellen støtter Grouped-Query Attention, Sliding Window Attention og har en innebygd Multi-Token Prediction-header for spekulativ dekoding. Den siste betyr at du ikke trenger en separat draft-modell for å gjøre inferensen raskere – Mellum2 håndterer det selv.
Hvilke varianter finnes og hvilken bør du velge?
JetBrains slapp seks sjekkpunkter på én gang:
- Base Pretrain og Base – grunnmodeller for de som vil finjustere fra bunnen
- Instruct – direkte svar, lav latens, best for ruting og enkle oppgaver
- Instruct-Thinking – inkluderer eksplisitte resonneringsspor for kompleks debugging og planlegging
For de fleste er Instruct-varianten riktig utgangspunkt. Den er laget for lav latens og passer godt for sub-agent-kall i en workflow. Hvis du jobber med tyngre kodingoppgaver som krever mer planlegging, er Instruct-Thinking et bedre alternativ – den tenker seg om litt lenger, men gir bedre svar på komplekse problemer.
Hvordan trener JetBrains en 12B modell – og hva er den trent på?
Mellum2 er trent på omtrent 10,6 billioner tokens gjennom en tre-fase-prosess. Fase én startet bredt – mye generelt webinnhold. Fase to og tre dreide progressivt mot kode og matematikk. Det er i grunnen slik de fleste gode kodemodeller trenes: bred forståelse tidlig, spesialisering sent.
Det tekniske som skiller Mellum2 litt fra mengden: JetBrains brukte Muon-optimizer med FP8 hybrid-presisjon under trening. Kontekstutvidelsen til 128K tokens ble gjort med layer-selective YaRN. Etter fortrening fulgte supervised finjustering og deretter reinforcement learning – standard oppskrift, men ryddig gjennomført.
Til sammenligning er IBM Granite 4.1 en annen open source-modell i lignende størrelsesklasse som har satset på enterprise-bruk. Mellum2 virker mer fokusert på utviklerverktøy og pipelines enn generell bedriftsbruk.
Hva er Mellum2 faktisk god på – og hva er den dårlig på?
JetBrains oppgir tall fra noen standardtester for Instruct-varianten. Jeg er skeptisk til å lese for mye inn i benchmarks generelt, men tallene gir et hint om styrker og svakheter:
Styrker – EvalPlus (kodeoppgaver): 78,4 – konkurransedyktig mot modeller i 4B-14B-klassen. BFCL v3 tool-use: 66,3. MultiPL-E flerspråklig koding: 67,1. Dette er det den er laget for, og det ser greit ut.
Svakheter – LiveCodeBench v6: 37,2, mot Qwen3.5 9B som scorer 63,7. GSM-Plus matematikk: 80,5, under de fleste sammenligningsmodeller. Generell problemløsning (GPQA Diamond): 40,9.
Oppsummert: Mellum2 er sterk på det den er bygd for (kodeassistanse, verktøykall, strukturerte oppgaver), og svakere enn konkurrentene på generell resonnering og avansert matematikk. Det er ikke en overraskelse – det er bevisst design. Den er ikke laget for å løse alt.
Slik kjører du Mellum2 lokalt med vLLM
Modellen er kompatibel med vLLM og Hugging Face Transformers. For å kjøre den via vLLM:
vllm serve JetBrains/Mellum2-12B-A2.5B-Instruct --max-model-len 131072Vil du aktivere tool-calling, legger du til --enable-auto-tool-choice --tool-call-parser hermes. Det krever en GPU med nok minne til å laste 2,5B aktive parametere – en RTX 3090 burde fungere greit.
Apache 2.0-lisensen betyr at du kan bruke dette i kommersielle produkter uten å spørre JetBrains om lov. Sammenlign det med Gemma 4 fra Google, som også bruker Apache 2.0 – det begynner å bli en trend at de store aktørene velger mer åpne lisenser.
Passer Mellum2 inn i en agentic workflow?
Det er her Mellum2 er mest interessant. Trenden i AI-utvikling akkurat nå er multi-modell-pipelines der du bruker ulike modeller til ulike deler av en oppgave. En stor modell planlegger og koordinerer, mens mindre spesialistmodeller utfører deloppgaver.
Mellum2 er eksplisitt designet for dette. JetBrains peker på tre konkrete bruksscenarioer:
- Ruting og orkestrering – avgjøre hvilken modell som skal håndtere et spørsmål
- RAG-oppsummering med lav latens – oppsummere søkeresultater raskt
- Sub-agent-kall – utføre definerte deloppgaver i en større workflow
Jeg synes dette er en mer ærlig tilnærming enn å påstå at 12B-modellen din konkurrerer med GPT-4o. JetBrains vet hva de har, og de posisjonerer det deretter. Det er noe å respektere.
For de som er interessert i andre åpne modeller i lignende brukstilfeller, er Darwin 35B-A3B et annet eksempel på en MoE-modell som tar et litt annet grep – og GLM-5 er på den andre enden av skalaen, med langt flere parametere og bredere ambisjoner.
Er Mellum2 verdt å teste?
Hvis du bygger AI-workflows der du allerede ruter oppgaver mellom modeller, ja – absolutt verdt et blikk. 2,5B aktive parametere er raskt, Apache 2.0 gir deg full frihet, og kode-evnene er solide nok til reelle oppgaver.
Hvis du derimot er ute etter én modell som skal gjøre alt – kode, skriving, analyse – er Mellum2 ikke riktig valg. Da er du bedre tjent med noe som Poolside Laguna M-1 eller en av de store frontier-modellene.
Det fine med open source er at du ikke trenger å velge én gang for alle. Last ned, test, se om den passer inn i pipelinen din. Det koster ingenting.







