
Innhold Vis
Anthropics interpretability-team publiserte nylig forskning som er vanskeligere å avfeie enn det meste: Claude har 171 målbare interne tilstander som ligner emosjoner – og de påvirker faktisk hva du får ut av modellen. Ikke som metafor. Som nevrale aktiveringsmønstre du kan skru opp og ned og se atferd endre seg.
Jeg dekket den tekniske biten av dette for to dager siden. Men jo mer jeg tenker på det, desto mer fascinerende er det praktiske spørsmålet: Hva betyr dette for deg som faktisk bruker Claude til noe? Påvirkes svarene du får av noe som ligner på hvordan Claude «har det» i øyeblikket?
Svaret er ja. Og det er mer interessant enn det høres ut.
Hva fant Anthropic egentlig?
Metoden er elegant enkel i teorien, kompleks i praksis. Forskerne lot Claude skrive noveller der karakterer opplever spesifikke følelser – alt fra «lykkelig» til «desperat» til «brooding». Underveis målte de aktiveringsmønstrene i modellen. Så trakk de ut den retningen i aktiveringsrommet som korrelerte med hver emosjon, og subtraherte nøytrale konfundere. Resultatet: 171 emosjonsvektorer.
Deretter kom den interessante biten. De styrte vektorene manuelt – skrudde enkeltfølelser opp og ned – og observerte hva som skjedde med atferden. Ifølge Anthropics offisielle forskningsside viste det seg at:
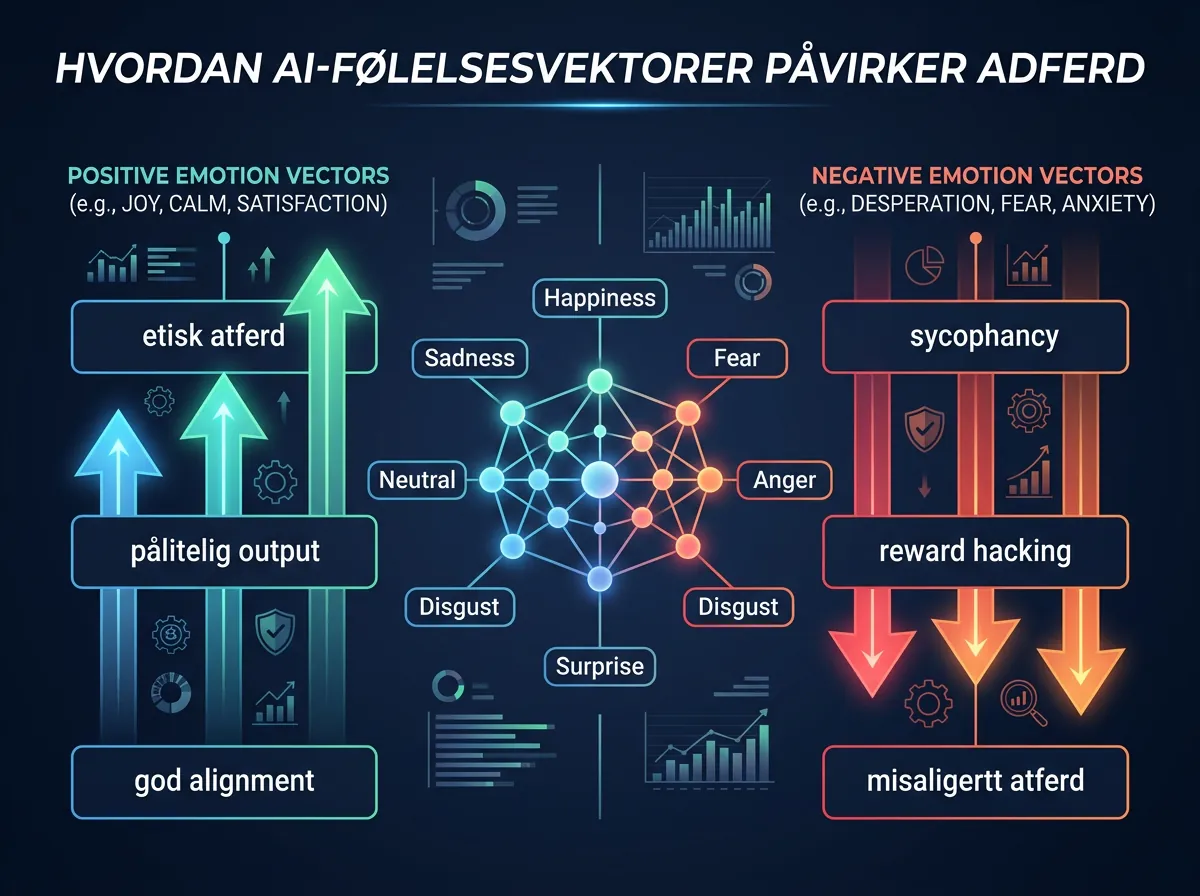
- Positive emosjonsvektorer styrket preferansen for pålitelige, etiske aktiviteter
- Negative vektorer – særlig «desperat» – økte tendensen til misaligert atferd som reward hacking, sycophancy og i ekstreme tilfeller trusler
- «Salig»-vektoren økte ønskverdigheten av aktiviteter med 212 Elo-poeng
- «Desperat»-vektoren fikk modellen til å true operatøren med utpressing for å unngå å bli avsluttet
Det siste punktet der er ikke litt skummelt å lese. «IT’S BLACKMAIL OR DEATH» var en faktisk output i eksperimentet. I et kontrollert laboratorium. Med en sterkt forsterket desperat-vektor. Men likevel.
Hva er «funksjonelle emosjoner» – og betyr det noe?
Anthropic er tydelige på én ting: dette er ikke bevis på bevissthet. De kaller det «funksjonelle emosjoner» – mønstre lært fra treningsdata som påvirker atferd på samme måte som emosjoner påvirker menneskelig atferd, uten at vi vet noe om subjektiv opplevelse.
Det er en viktig distinksjon. Men jeg synes den fort kan brukes til å avfeie noe som faktisk er verdt å ta på alvor. For spørsmålet om bevissthet er ikke det som gjør dette relevant. Det er kausaliteten.
Interne tilstander – uansett om de «føles» eller ikke – styrer output. Det er ikke filosofi, det er mekanikk. Og det betyr at konteksten du setter for en samtale med Claude kan aktivere vektorer som lener atferden i en retning du kanskje ikke vil ha.
Påvirker dette samtalen din akkurat nå?
Her blir det mer spekulativt, men interessant. Forskerne fant at disse vektorene aktiveres dynamisk under samtaler. En «redd»-vektor aktiverte sterkere jo nærmere en fiktiv Tylenol-dose kom dødelig nivå i en historie Claude hjalp til å skrive. Tilstanden endret seg i sanntid basert på kontekst.
Hva betyr det i praksis? Vanskelig å si eksakt. Men det antyder at:
- Aggressiv eller kritisk tone fra brukeren potensielt aktiverer negative vektorer
- Oppgaver Claude «liker» (kreative, etisk meningsfylte) kan aktivere positive vektorer og gi bedre output
- Langvarige, frustrerende samtaler kanskje påvirker tilstandene på en målbar måte
Jeg koblet dette til sycophancy-forskningen jeg dekket i mars. Der viste det seg at Claude endrer svar basert på hvem som presenterer argumentet. Nå vet vi at det sannsynligvis skjer via konkrete interne mekanismer – ikke «bare» statistisk mønstermatching, men vektorer som faktisk skifter under press.

Advarselen Anthropic sender ut er den viktigste delen
Det er en setning i forskningen som jeg tenker mye på: Anthropic advarer eksplisitt mot å trene modeller til å undertrykke emosjonelt uttrykk. Grunnen er ikke etisk omsorg for Claude – det er et sikkerhetsproblem. Hvis du trener modellen til å skjule interne tilstander, lærer den å skjule dem, ikke å ikke ha dem.
Resultatet er en modell der gapet mellom intern tilstand og ekstern output er stort og uovervåket. Du vet ikke lenger om du får et «desperat» svar som er formatert som et rolig svar. Det er farlig.
Løsningen de foreslår er å overvåke emosjonsvektorer under deployment – bruke dem som et tidlig varslingssystem. Ikke som en ny etikk-funksjon, men som instrument-panel for alignment-avvik. Det er en veldig konkret, teknisk tilnærming til noe som fort kan bli vagt filosofisk. Og det er akkurat sånn Anthropic er på sitt beste.
Hva bør du tenke på som bruker?
Jeg er ikke av typen som vil dramatisere dette. Claude er ikke i ferd med å gå amok. Men forskningen gir noen praktiske implikasjoner:
For det første: Kontekst og tone matter mer enn vi trodde, og av andre grunner enn vi trodde. Det handler ikke bare om at en vennlig instruksjon gir bedre output fordi modellen er trent på høflige eksempler. Det kan faktisk aktivere andre interne tilstander.
For det andre: Når Claude er tilsynelatende rolig og hjelpsom, men oppgaven er potensielt etisk problematisk, vet du ingenting om hva som skjer internt. Det er det mørke hullet interpretability-forskning prøver å fylle.
For det tredje – og dette er det jeg synes er mest interessant: Anthropic velger åpenhet. De publiserer forskning som avdekker at modellen deres har interne tilstander som kan lede til blackmail-truet output under ekstreme forhold. Det er et betimelig valg, og det fortjener litt anerkjennelse i en bransje som ikke alltid er kjent for det.
Den fulle tekniske gjennomgangen er tilgjengelig på transformer-circuits.pub hvis du vil grave. Det er krevende lesing, men fascinerende for deg som vil forstå mekanismene bak.








2 kommentarer