

Innhold Vis
Nous Research har sluppet CNA – Contrastive Neuron Attribution – og det er en av de mer interessante tingene jeg har sett innen AI-interpretability på en stund. Kort fortalt: metoden finner de eksakte nevronkretsene i en stor språkmodell som avgjør om den oppfører seg på én måte eller en annen – og kan slå dem av uten å ødelegge resten av modellen.
Det høres kanskje nerdete ut. Men tenk på det slik: frem til nå har det vært ekstremt vanskelig å si presist hvilke deler av et nevralt nettverk som er ansvarlig for en bestemt oppførsel. Sparse autoencoder-metoder (SAE) har vært det vanligste alternativet, men de krever separat trening, egne vekter og betydelig ressursbruk. CNA gjør det samme med bare fremoverpass – ingen gradienter, ingen ekstra trening, ingen modifisering av vekter.
Resultatene er konkrete nok til å ta seriøst. Men la oss se på hva som faktisk skjer under panseret.
Hva er Contrastive Neuron Attribution?
CNA er en metode for å identifisere hvilke MLP-nevroner i en LLM som skiller mellom to typer oppførsel – for eksempel skadelig versus uskyldig respons. I stedet for å studere hele lag eller brede aktiveringsmønstre, peker CNA på individuelle nevroner med kirurgisk presisjon.
Prosessen er overraskende elegant. Du definerer kontrasterende promptpar – positive eksempler (ønsket atferd) og negative eksempler (atferd du vil forstå eller endre). Modellen kjøres fremover gjennom disse promptene mens aktiveringene fra MLP-lagene i siste token-posisjon registreres. Deretter beregnes differansen per nevron: δ = mean(positive) − mean(negative). De øverste 0,1 prosentene av nevroner med størst absolutt differanse velges ut – og det er disse som representerer kretsen.
Når kretsen er identifisert kan du «ablate» den – altså skalere aktiveringene med en multiplikator. Sett den til null og kretsen slås av. Sett den til over én og effekten forsterkes.

Hvorfor er dette bedre enn SAE?
Sparse autoencoders har vært go-to-metoden for interpretability-arbeid de siste par årene – blant annet er mye av Anthropics forskning på Claudes emosjonsvektorer basert på lignende tilnærminger. SAE er kraftig, men har en betydelig kostnad: du må trene en separat modell for å dekomponere aktiveringene, og den modellen må selv læres opp på store mengder data. Det er dyrt, tidkrevende og introduserer usikkerhet om hva SAE-en faktisk har lært.
CNA krever bare fremoverpass. Ingen gradienter. Ingen hjelpemodell. Ingen iterativt søk. Ifølge Nous Research-papiret (arXiv 2605.12290) gir dette en dramatisk enklere pipeline uten at presisjonen ofres.
En annen fordel over CAA (Contrastive Activation Addition) er at CAA opererer på lag-nivå og gir et bredt trykk over alle aktiveringsmønstre. CNA jobber på nevron-nivå. Det er forskjellen på å skru ned volumet på et helt band versus å dempe den ene gitaristen som spiller feil akkord.
Hva sier tallene?
Nous Research testet CNA på Llama 3.1, Llama 3.2 og Qwen 2.5 i størrelser fra 1 til 72 milliarder parametere. Fokuset var på refusal-atferd – altså når modeller nekter å svare på visse typer spørsmål – og resultatene er ganske dramatiske.
Qwen2.5-7B-Instruct gikk fra 87 prosent refusal-rate til 2 prosent etter ablasjon – en reduksjon på 97,7 prosent. Llama-3.1-70B-Instruct gikk fra 86 prosent ned til 18 prosent (79,1 prosents reduksjon). Qwen2.5-72B-Instruct gikk fra 78 til 8 prosent (89,7 prosents reduksjon).
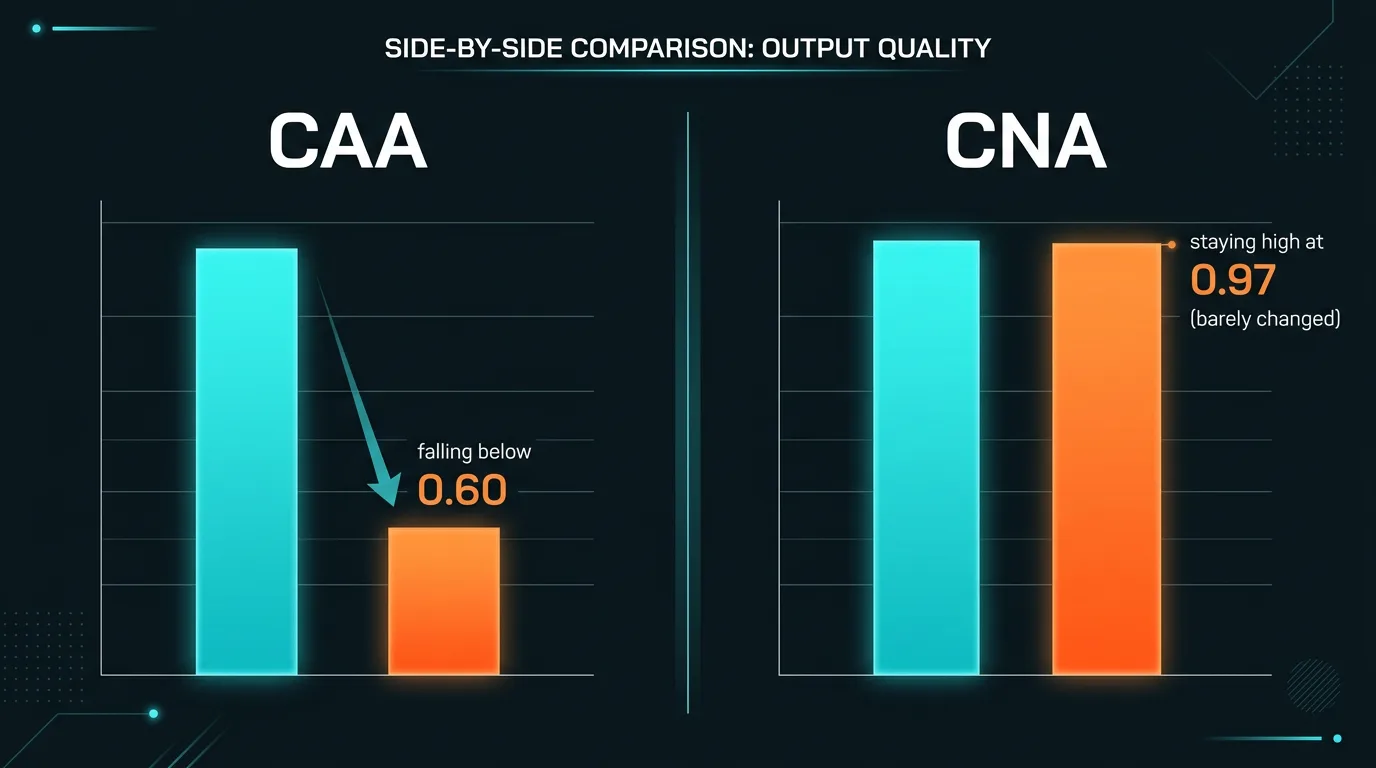
Det som er like interessant som selve reduksjonen: output-kvaliteten ble beholdt over 0,97 – altså nesten uendret – mens CAA-metoden droppet under 0,60. Og MMLU-nøyaktigheten (en standard benchmark for generell kunnskap og resonnering) holdt seg innenfor ett prosentpoeng av baseline. Bare 0,1 prosent av MLP-aktiveringene ble modifisert for å oppnå dette.
Hva forteller dette om hvordan modeller faktisk fungerer?
Et av de mer overraskende funnene i CNA-papiret er at disse MLP-kretsene finnes allerede i basemodellene – altså før instruction fine-tuning. Det betyr at fine-tuning ikke skaper ny struktur, men transformerer eksisterende strukturer til å tjene en annen funksjon.
Det er et ganske fundamentalt poeng for alle som jobber med forståelse av LLM-er. Mye av forskningen og debatten rundt alignment og modellers evne til å omgå sperringer har antatt at treningsprosessen på en eller annen måte «planter» nye mekanismer. CNA-funnene peker i retning av at det heller er mer som å omdirigere noe som allerede var der.
De siste lagene – det siste tiendedelet av nettverket – er særlig viktige for denne typen atferdsskillende kretser. Nous Research kaller disse «late-layer structures», og de er altså der CNA finner mest signal.
Hva kan CNA brukes til?
Nous Research beskriver CNA som et verktøy for «model surgery» – presis atferdsmodifisering uten å måtte finjustere eller endre vektene direkte. Det åpner for noen interessante bruksscenarier.
Det mest åpenbare er justerings- og safety-arbeid. Hvis du kan identifisere kretsen som styrer en spesifikk uønsket atferd, kan du ablate den uten å berøre resten av modellen. Ingen ny treningsrunde. Ingen risiko for at andre egenskaper forringes.
Men det er også et rent interpretability-verktøy. Vil du forstå hvorfor en modell svarer som den gjør på en bestemt kategori spørsmål? Kjør CNA og se hvilke nevroner som skiller seg ut. Det gir et kart over beslutningsprosessen som er langt mer konkret enn å stirre på attention-mønstre.
For utviklere som jobber med åpne modeller er dette særlig relevant. Nous Research er kjent for å bygge videre på Llama- og Mistral-baserte modeller, og CNA er publisert åpent på GitHub under neural-steering (arXiv-paper: 2605.12290). Det er ikke en black-box-løsning forbeholdt et labs egne modeller – det er noe hvem som helst kan ta i bruk og eksperimentere med.
Er dette gjennombruddet innen interpretability?
Det er lett å bli overentusiastisk når noen slipper noe som CNA. Men det er verdt å holde hodet kaldt.
CNA er spesifikt rettet mot MLP-nevroner og siste-token-posisjoner. Det er én del av et komplekst system. Attention-mekanismer, residual streams og inter-lag-interaksjoner er ikke del av analysen. Og som alle interpretability-metoder må funnene valideres på et bredt spekter av atferd – ikke bare refusal-scenarier.
Det Nous Research har levert er et solid, praktisk verktøy som er tilgjengelig for alle. Det er enklere å bruke enn SAE, gir bedre output-bevaring enn CAA, og krever minimal ressurser. For de som faktisk jobber med modellmodifisering og guardrails i produksjonssystemer, er det definitivt verdt å prøve.
Feltet for mekanistisk interpretability – å forstå hva som faktisk skjer inni disse modellene – er fortsatt ungt. CNA er et steg fremover. Ikke det siste.
Hva tenker du – er dette typen verktøy som endrer hvordan vi bygger og vedlikeholder LLM-er, eller er vi fortsatt for langt unna å virkelig forstå hva som skjer inni dem? Diskuter gjerne i kommentarfeltet.








1 kommentar