

Innhold Vis
Noen lager ikke om på noe eksisterende – de bygger fra bunnen av. hipEngine er et nytt open source inference engine skrevet spesifikt for AMD-GPUer, uten PyTorch-avhengigheter i hot-pathen, med 120+ egenskrevne HIP-kjerner. Versjon 0.2.1 alpha ble sluppet 24. mai 2026 av teamet bak shisa-ai, og tallene er faktisk verdt å se på.
Bakgrunnen er prosjektet FastDMS – samme utviklere som tidligere eksperimenterte med KVCache-optimalisering. hipEngine er ikke en fork. Det er en ny kodebase som tar lærdom fra Nano-vLLM, ParoQuant og llama.cpp, og redesigner hele eksekveringsstakken rundt AMDs RDNA3-arkitektur. Resultatet er et verktøy som kjører Qwen3.6 35B direkte på RX 7900 XTX og Ryzen AI MAX+ 395 (Strix Halo) uten å gå via CUDA-kompatibilitetslag.
Jeg synes dette er interessant av en spesifikk grunn: AMD-siden av lokal LLM-inferens har lenge vært et stebarn. llama.cpp støtter ROCm via Vulkan og HIP, men ytelsen har vært ujamn – særlig på lange kontekster. hipEngine er et forsøk på å tette det gapet med native AMD-kode.
Hva er hipEngine, og hvem er det for?
hipEngine er et Python-basert inference engine der all tung kjøring skjer i HIP/C++. Det betyr at Python-grensesnittet er der, men GPU-kernelene – selve jobben med å kjøre transformer-lagene – er skrevet direkte mot AMD-hardware. Biblioteket bruker hipBLASLt for lineæralgebra, hipGraph for kommandografadministrasjon, og en vedlikeholdt delmengde av AOTriton for kernel-kompilering.
Målgruppen er folk som kjører store modeller lokalt på AMD-hardware: enten en dedikert GPU som RX 7900 XTX (gfx1100), eller en Strix Halo APU som Ryzen AI MAX+ 395 (gfx1151). Det støtter Qwen3.5 og Qwen3.6 35B-klassen, med ParoQuant (PARO) og GGUF Q4_K_M/Q4_K_S som kvantiseringsformater.
For deg som ikke har fulgt AMD-inferens-siden tett: dette er et steg opp fra «llama.cpp kjører, men litt treigt». hipEngine er laget av folk som vil se nøyaktig hva AMD-hardware faktisk kan levere når man skriver mot den direkte, ikke gjennom kompatibilitetsabstraksjoner.
Hva viser benchmarkene?
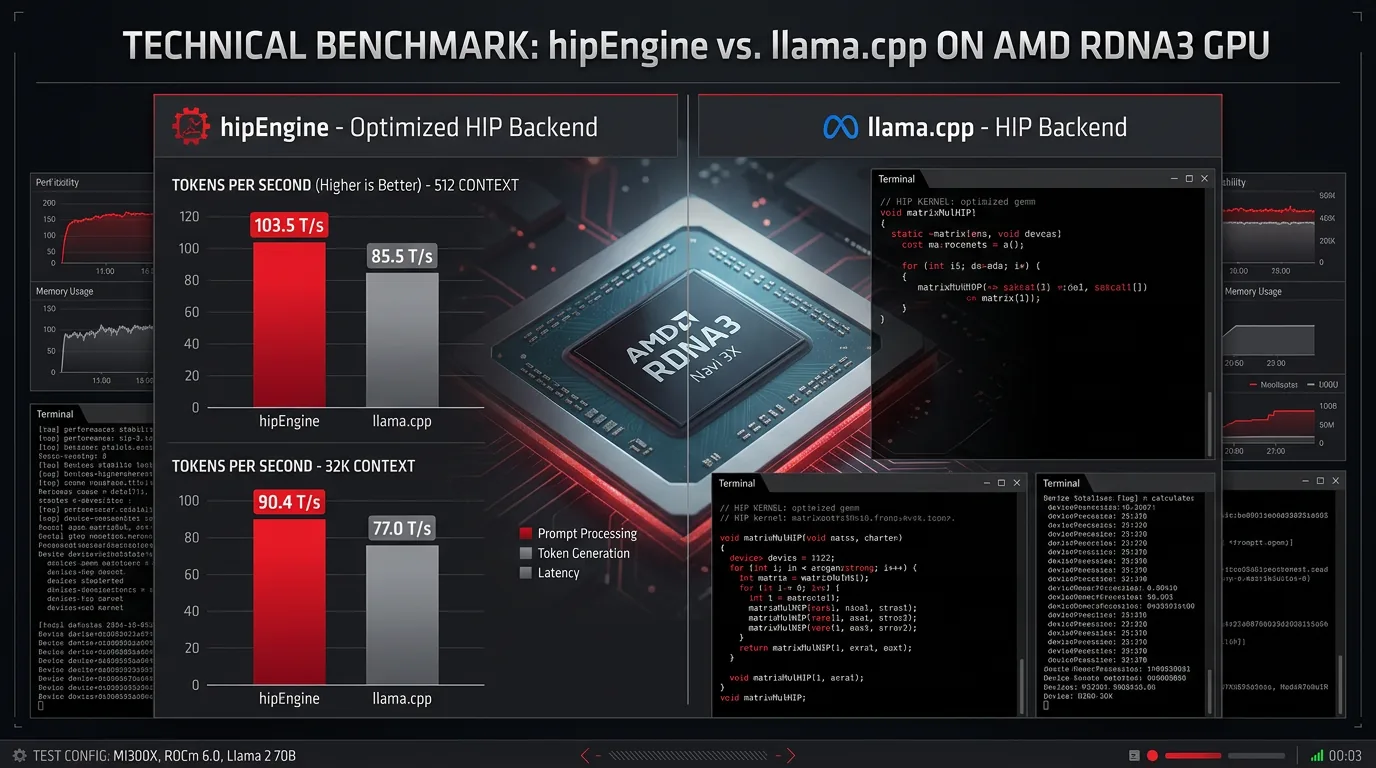
Alle tall under er fra GitHub-dokumentasjonen til hipEngine. Testplattformene er AMD Radeon Pro W7900 (gfx1100) og Ryzen AI MAX+ 395 / Strix Halo (gfx1151), begge med Qwen3.6 35B-A3B-modellen.
På W7900 (RX 7900 XTX-klasse) med PARO-kvantisering:
Decode-hastigheten ligger på 103,5 tokens per sekund med kort kontekst (512 tokens inn, 128 ut), og holder seg på 90,4 tok/s ved 32K kontekst. Standard llama.cpp HIP leverer 85,5 og 77,0 på de samme testene. Det er omtrent 20-17% raskere i decode. Og det er ikke uvesentlig når du sitter og venter på svar fra en lokal modell.
Prefill-ytelsen er enda mer markant ved lange kontekster: ved 128K kontekst leverer hipEngine 1 055 tokens per sekund mot llama.cpp HIP sine 710. Det er nesten 50% bedre gjennomstrømning der lange dokumenter skal prosesseres. Atlas inference engine (Rust/CUDA) viste lignende mønstre – native implementasjoner skalerer mye bedre på lange kontekster enn generelle løsninger.
På Strix Halo (gfx1151) – altså en bærbar APU, ikke dedikert GPU:
Decode på 62,1 mot llama.cpp sine 50,5 tokens/s ved 512 tokens kontekst – det er 23% raskere. Ved 32K kontekst: 50,6 mot 43,4 tok/s. Den ene plassen llama.cpp holder seg hakket over er 128K kontekst (31,3 vs 30,2 tok/s), men da er begge ganske presset av minnebåndbredden uansett.
Minneforbruket er en bonus: hipEngine bruker 22,1 GiB på 128K kontekst mot llama.cpp sine 23,6 GiB. Det er ikke dramatisk, men på en APU med delt minne teller det.
Hvordan fungerer PARO-kvantisering?
PARO (ParoQuant) er kvantiseringsformatet hipEngine primært er optimalisert rundt. Den anbefalte modellen er shisa-ai/Qwen3.6-35B-A3B-PARO-full4096-e5-packed på 19,07 GiB – det er 4,68 bits per vekt, omtrent på nivå med Q4_K_M i størrelse.
Utviklerne har validert INT8 KV-cache-kompresjon ved 256K kontekst og måler maksimal KL-divergens på 0,015 mot BF16 referanse, med 100% top-1 samsvar på alle testede oppmerksomhetslag. Med andre ord: kvaliteten på output holder seg på nivå med halvpresisjonsvarianten, selv med komprimert KV-cache.
Lastetiden er rundt 24 sekunder for PARO-modeller og 60 sekunder for GGUF (siden GGUF-vekter pakkes om til T16 tile-layout ved innlasting). Det er en engangskostnad per økt – ikke et problem i praksis.

Hvordan installerer du hipEngine?
Kravene er Python 3.11+, en fungerende ROCm-installasjon med libamdhip64.so, og enten en gfx1100- eller gfx1151-GPU. Selve installasjonen er enkel:
git lfs install && git lfs pull
pip install -e .Det gir kjerne-pakken uten PyTorch-avhengighet – totalt rundt 125 MB. Vil du ha OpenAI-kompatibel servermodul: pip install -e "[server]". Torch-broen for dlpack-interoperabilitet: pip install -e "[torch]". Servermodus starter en lokal API med /v1/chat/completions-endepunkt og SSE-streaming, så den dropper rett inn mot alle klienter som snakker OpenAI-format.
from hipengine import LLM, SamplingParams
llm = LLM("/sti/til/modell", quant="w4_paro")
outputs = llm.generate(["Hei fra hipEngine."], SamplingParams(max_tokens=64, temperature=0.0))Dette er ALFA-programvare. Versjon 0.2.1 er et tidlig utgave. Kodebasen er dokumentert som langt unna det teoretiske ytelsstaket for gfx1100, og modellstøtten er begrenset til Qwen3-familien foreløpig. Det er ikke en erstatning for llama.cpp i dag – det er et prosjekt å følge med på. DFlash/PFlash-optimalisering på Strix Halo som jeg dekket for noen uker siden er en annen tilnærming til samme problem – det er tydelig at AMD-hardware tiltrekker seg utviklere som vil presse grensene.
Hva skiller hipEngine fra andre løsninger?
Det er tre ting som skiller seg ut teknisk. Første er den PyTorch-fri hot-pathen: du trenger ikke installere 2 GB PyTorch for å kjøre inferens. Hele GPU-kommunikasjonen går via hipengine.Tensor – en tynn innpakning rundt rå HIP-minnepekere. Det gir raskere oppstart og lavere minneoverhead i drift.
Andre er plugin-registersystemet: kernels registreres med en fire-akset nøkkel (backend, lag, kvantering, variant). Det betyr ingen if-else-kjeder i dispatch-logikken – riktig kernel velges direkte ut fra modellkonfigurasjonen. Open source AI-verktøy som bygger på spesialiserte backends har historisk sett slitt med nettopp denne type overhead.
Tredje er langt-kontekst-optimaliseringen: hipEngine bruker chunk-basert prefill (512 uchunket, over 1K bruker 1024/1024/4096 chunk-størrelse) kombinert med fusion-planlegging som foretrekker fuserte kernels men beholder ikke-fuserte fallbacks for korrekthetssikkerhet. Det er grunnen til at den lange-kontekst-ytelsen ser bedre ut enn llama.cpp – design valget er eksplisitt optimalisert for det.
Mot GGUF Q4_K_S på W7900: PARO er raskere på prefill gjennomgående, men llama.cpp sin Vulkan-backend slår hipEngine PARO på decode ved korte kontekster (127,5 vs 103,5 tok/s). Det er en ærlig innrømmelse fra prosjektets side – de har ikke optimalisert alt enda, og det er mer å hente.
Er dette verdt å prøve nå?
Svaret avhenger helt av hva du har liggende. Har du en RX 7900 XTX eller en Strix Halo-maskin og vil kjøre Qwen3.6 35B lokalt – ja, hipEngine er verdt å eksperimentere med. Ytelsestallene ved lange kontekster er genuint imponerende for et alfa-prosjekt, og PyTorch-fri installasjon er en lettelse sammenlignet med den typiske ROCm-installasjonsritualen.
Har du en NVIDIA-GPU, hold deg til llama.cpp, Atlas eller NadirClaw for ruting. hipEngine er eksplisitt AMD-first, og NVIDIA sm86-støtte er merket som planlagt, ikke tilgjengelig.
Det som er interessant her er ikke nødvendigvis de spesifikke tallene – det er at noen faktisk bygger dette. AMD-hardware har vært tilgjengelig for lokal AI i årevis, men CUDA-monolittens effekt på verktøyøkosystemet har vært massiv. Prosjekter som hipEngine, DFlash, og GAIA AMD-rammeverket jeg dekket i april tyder på at det begynner å bygge seg opp et reelt AMD-alternativ. Sakte, men det skjer.
hipEngine er tilgjengelig på GitHub under AGPLv3-lisens. Versjon 0.2.1 alpha, sluppet 24. mai 2026.







