

Innhold Vis
RTX 5090 er Nvidias råeste forbrukerkort – 32 GB GDDR7, 1792 GB/s minnebåndbredde og 575 watt TDP. Men trenger du faktisk alle de 575 wattene for å kjøre lokale AI-modeller? En grundig benchmarktest viser at svaret er nei – og forskjellen er mer interessant enn du kanskje tror.
Spørsmålet oppsto etter en analyse av strømforbruk og effektivitet ved lokal LLM-kjøring. Poenget var enkelt: kortet er dimensjonert for gaming, men lokal AI-inferens stiller fundamentalt forskjellige krav til GPU-en. Token-generering er nesten utelukkende begrenset av minnebåndbredde, ikke regnekraft. Det betyr at det er mulig å spare betydelig strøm uten at hastigheten faller tilsvarende.
Resultatet er kurvediagrammer som viser prompt parsing-hastighet, token-genereringshastighet og strøm-effektivitet (tokens per watt) ved alt fra 400 watt til full 575 watt. Her er hva tallene sier.
Hva begrenser faktisk hastigheten på lokal LLM-kjøring?
Før vi ser på tallene er det verdt å forstå hva som faktisk skjer når en GPU kjører lokale språkmodeller. For de fleste brukstilfeller er token-generering ikke CPU-bundet, ikke CUDA-kjerne-bundet – det er minnebåndbredde-bundet. Modellvektene må leses fra VRAM for hvert eneste token som genereres, og det er denne lesehastigheten som setter taket.
RTX 5090 har 1792 GB/s minnebåndbredde – nesten dobbelt av RTX 4090-ens 1008 GB/s og betraktelig mer enn Intel Arc Pro B70 med sine 608 GB/s. For token-generering er dette den viktigste enkeltspesifikasjonen.
Prompt parsing er annerledes. Her behandles mange tokens parallelt, og CUDA-kjernene får faktisk noe å gjøre. Det er her råkraft teller mer, og det er her vi ser større nedgang ved lavere strømnivåer.
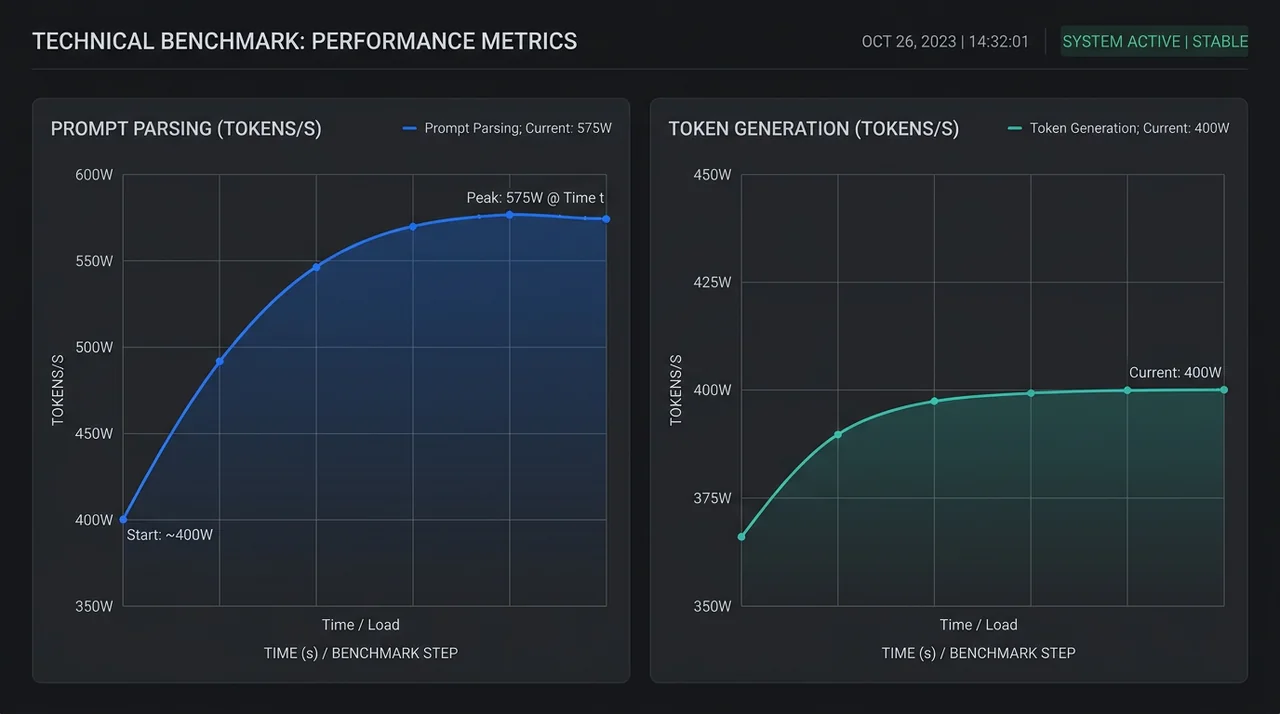
Hva viser kurvene for prompt parsing?
Prompt parsing (prefill-fasen) er ressurskrevende – her prosesseres hele kontekstvindinet på én gang. Resultatene viser en relativt tydelig sammenheng mellom tilgjengelig strøm og hastighet i dette steget.
Ved 400 watt – det anbefalte minimum sweet spot – synker prompt parsing-hastigheten merkbart sammenlignet med full 575 watt. Det gir mening: parsingen er den operasjonen som faktisk laster CUDA-kjernene, og disse skalerer med klokkefrekvens og spenning. Nvidia Blackwell-arkitekturen, som RTX 5090 er bygget på, bruker TSMC 4N-prosessen og har 21 760 CUDA-kjerner tilgjengelig ved full ytelse.
Praksiskonsekvensen: hvis du har lange kontekstvindu og kjører mye re-parsing (for eksempel ved mange parallelle forespørsler med stor kontekst), vil strømbegrensning treffe deg mer her enn under generering. For typisk chatbot-bruk med kortere kontekster er dette sjelden flaskehalsen.
Hva skjer med token-generering ved lavere strøm?
Her er den interessante observasjonen: token-genereringshastigheten holder seg overraskende godt selv med redusert strøm. Kurvene flater betydelig ut sammenlignet med prompt parsing. Det er direkte i tråd med teorien om at generering er minnebåndbredde-bundet – og minnebåndbredden endrer seg ikke mye med strømbegrensning.
400 watt fremstår som et naturlig sweet spot. Under dette punktet begynner hastigheten å falle mer markant, og effektivitetsgevinsten (tokens per watt) begynner å avta. Over 400 watt og opp mot 575 watt gir du kortet mer strøm, men token-genereringshastigheten øker ikke proporsjonalt – du brenner mer strøm for marginalt mer ytelse.
For sammenligning: i benchmarker fra tidligere tester med RTX 5090 og fullstendig lokal inferens med Nemotron 9B lå token-genereringen på rundt 235 tokens/s for Gemma 3 27B. Med strømbegrensning til 400 watt vil du typisk se 10-15% lavere tall, men med nesten 30% strømsparingen.

Hva er tokens per watt – og hvorfor er det viktig?
Effektivitetsmålet tokens per watt er kanskje den mest nyttige metrikken for lokal LLM-bruk. Det kombinerer ytelse og strømforbruk til ett tall – jo høyere, desto mer «AI per strømkrone» får du.
Kurvene viser at tokens per watt topper seg rundt 400 watt og begynner å falle ved høyere strømnivåer. Det betyr at full 575 watt gir absolutt høyest token-hastighet, men dårligst effektivitet. Hvis du betaler norsk strømpris (over 1 kr/kWh mange steder) og kjører modeller mange timer daglig, er dette ikke uvesentlig.
For å sette det i perspektiv: 175 watt ekstra strøm (fra 400W til 575W) i 8 timer daglig er 1,4 kWh, eller omtrent 1,40 kr per dag med en strømpris på 1 kr/kWh. Over et år er det over 500 kr – for marginal ytelsesgevinst i token-generering. Strømbegrensning til 400 watt lønner seg for de fleste som kjører kontinuerlig.
Hvordan setter du strømbegrensning på RTX 5090?
På Linux gjøres dette via nvidia-smi:
sudo nvidia-smi -pl 400Det setter en myk strømbegrensning (power limit) på 400 watt. Kortet vil da dynamisk justere klokkene for å holde seg under grensen. Endringen er midlertidig og tilbakestilles ved omstart – ønsker du det permanent, kan du legge det inn i et systemd-script eller i /etc/rc.local.
På Windows bruker de fleste MSI Afterburner eller EVGA Precision X1 for tilsvarende funksjonalitet. Sett power limit til 70% (ca. 400W) som utgangspunkt og juster basert på dine egne benchmarker.
Det er også verdt å nevne at PCIe-båndbredde kan fungere som en separat flaskehals i noen oppsett – ikke bare GPU-ytelsen isolert.
Sammenligning med andre kort til lokal LLM
RTX 5090 er åpenbart ikke det eneste alternativet. For de fleste som primært kjører lokale modeller uten behov for absolutt toppytelse, finnes rimeligere alternativer.
RTX 4090 har 24 GB VRAM og 1008 GB/s minnebåndbredde til rundt halvparten av prisen for et brukt kort. For modeller som passer i 24 GB er båndbredde-gapet (1008 vs 1792 GB/s) det som faktisk teller – omtrent 43% lavere token-genereringshastighet i teorien. I praksis er det noe lavere enn det fordi inferensrammeverk som llama.cpp og Ollama ikke alltid utnytter full båndbredde.
RTX 5090 sin styrke er primært 32 GB VRAM – nok til å kjøre 70B-modeller med medium kvantisering, og nok til å holde store kontekstvindu i minnet. Det er VRAM som er den reelle differensieringsfaktoren, ikke rå strøm.
For den som er interessert i Nvidias posisjon i AI-akselerert databehandling mer generelt, er RTX 5090 et godt eksempel på at CUDA-arkitekturen fortsetter å optimalisere for de oppgavene som faktisk driver GPU-salg i 2026.
Hva er den praktiske konklusjonen?
Tallene er ganske tydelige. 400 watt er sweet spot for de fleste som kjører lokale LLM-er på RTX 5090. Du får:
- Tilnærmet uendret token-genereringshastighet (minnebåndbredde er ikke direkte strømskalerbar)
- Noe lavere prompt parsing-hastighet (akseptabelt for de fleste brukstilfeller)
- Omtrent 30% strømsparingen sammenlignet med full 575 watt
- Høyere tokens per watt – bedre effektivitet totalt sett
Under 400 watt begynner token-genereringen å synke merkbart. Over 400 watt brenner du ekstra strøm uten proporsjonal ytelsesgevinst. Det ligner mye på det vi ser med andre GPU-arkitekturer til lokal LLM – det finnes nesten alltid et effektivitetsgulv, og det lønner seg å finne det.
Har du gjort egne strøm-benchmarker på RTX 5090 eller andre kort? Tallene mine stemmer ikke alltid med teorien, og det er mer interessant enn når de gjør det.







