

Innhold Vis
En enkelt konfigurasjonsfil skal kutte Claude-output med 63 prosent – uten én linje kode. Det er løftet bak Universal Claude.md, et GitHub-prosjekt som har fått mye oppmerksomhet på Hacker News. Ideen er enkel: plasser en CLAUDE.md-fil i rotkatalogen din, og Claude Code leser den automatisk og justerer oppførselen sin.
Jeg har sett på hva som faktisk er inni denne filen, testet tallene, og lest gjennom hva folk på Hacker News mener. Konklusjonen er litt mer nyansert enn overskriften tilsier – men det er likevel noe her som er verdt å forstå.
CLAUDE.md er ikke noe nytt konsept. Det er den samme mekanismen jeg bruker daglig i mine egne prosjekter – inkludert i dette nettstedet. Men ideen om å lage en «universell» versjon som alle kan bruke, er interessant.
Hva er Universal Claude.md?
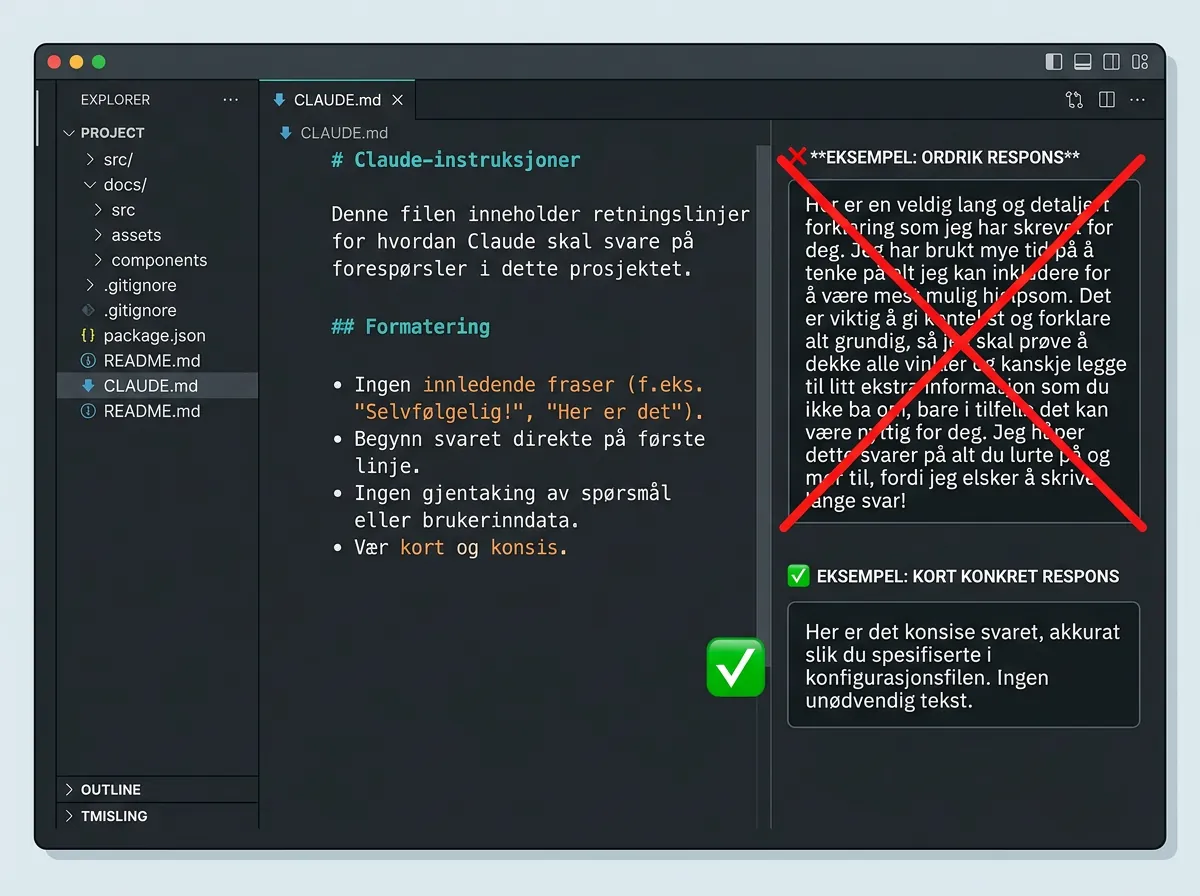
Prosjektet er rett og slett én markdown-fil med atferdsregler for Claude. Filen sier i bunn og grunn: «Slutt å tøffe deg. Bare svar.» Det baner vei for instruksjoner som:
- Ingen innledende høflighetsfraser («Absolutt! La meg hjelpe deg med det!»)
- Ingen oppsummering av spørsmålet før svar
- Ingen unødvendige ansvarsfraskrivelser og forbehold
- Svar kommer på linje 1 – resonnement etter, aldri før
- Kun ASCII-tegn i output
Plasser filen i rotkatalogen av et Claude Code-prosjekt, og Claude leser den automatisk ved oppstart. Claude Code er bygget slik at disse instruksjonene har høy prioritet – men brukerens egne instruksjoner vinner alltid.
Hva sier tallene – og hva sier de ikke?
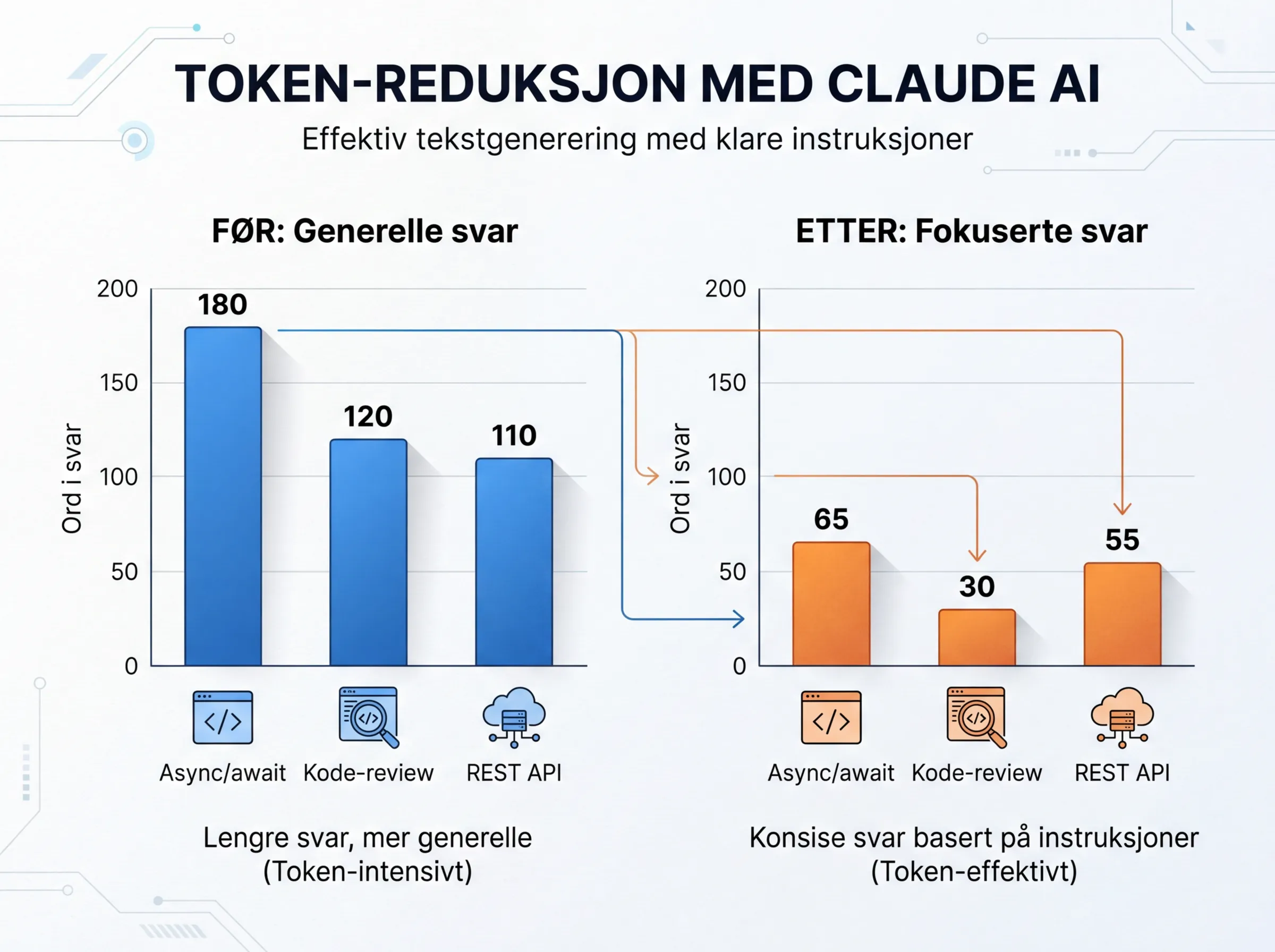
Prosjektet rapporterer 63 prosent reduksjon i output-tokens, basert på fem testprompts. Tallene ser slik ut:
- Forklaring av async/await: 180 ord ned til 65 (64% reduksjon)
- Kode-review: 120 ord ned til 30 (75% reduksjon)
- REST API-forklaring: 110 ord ned til 55 (50% reduksjon)
Totalt: 465 ord ned til 170. Det er 63 prosent.
Men README-en er ærlig nok til å si det direkte: «Dette er en 5-prompt indikator, ikke en statistisk kontrollert studie.» Og det stemmer. Fem prompts er ikke nok til å si noe universelt. Resultatet varierer dramatisk basert på hva du spør om.
Det som er mer interessant er kommentaren om input-tokens. Filen selv bruker input-tokens for å laste inn instruksjonene. Anthropic priser input og output ulikt – output koster gjerne mer, men CLAUDE.md-overhead er ikke gratis. Sparer du på output men betaler mer på input totalt sett? Det kommer an på volumet.
Hva sier Hacker News?
Kommentarfeltet på Hacker News er mer nyansert enn selve prosjektet. Et par poenger er verdt å nevne.
Én bruker peker på at instruksjonen «svar er alltid på linje 1, resonnement kommer etter» faktisk kan svekke modellens reasoning-kvalitet. Argumentet er at LLM-er er autoregressive – de genererer token for token, og å tvinge frem et svar før resonnementet er ferdig, kan føre til at modellen låser seg til en retning for tidlig. Det er et reelt poeng hvis du bruker Claude til komplekse problemstillinger.
En annen bruker bemerker det åpenbare: de fleste Claude-kostnader i API-sammenheng kommer fra input-tokens, ikke output. Å legge til 400 ord med instruksjoner for å spare 55-90 output-tokens kan faktisk gjøre ting dyrere for lavvolum-bruk. Jeg har skrevet om dette tidligere i sammenhengen med Claude API vs. Claude Max – kostnadsstrukturen er ikke alltid intuitiv.
Det er også de som sier de kjører «nær vanilla-setup» og foretrekker det. Teknologien utvikler seg så raskt at radikale endringer av standardoppførselen kan gi problemer når neste modellversjon lanseres.
Når er det faktisk nyttig?
CLAUDE.md-tilnærmingen gir mest mening i to scenarioer:
Automatiseringspipelines med høyt volum. Hvis du kjører hundrevis eller tusenvis av Claude-kall per dag i en automatisert workflow, betyr hvert ord i output noe. Da kan en enkel instruksjonsfil faktisk gi målbar kostnadsreduksjon. Jeg bruker n8n for automatisering, og der er token-effektivitet noe jeg tenker på.
Repetitive utviklingsoppgaver. Hvis du sitter og koder hele dagen i Claude Code og irriterer deg over at den stadig åpner med «Absolutt! Her er min analyse av problemet ditt…» – da er det nyttig å fjerne det. Det handler ikke om penger, men om å slippe støy.
For enkeltspørsmål og ad hoc-bruk er det derimot ikke sikkert det lønner seg. Overhead fra selve instruksjonsfilen spiser opp gevinsten.
CLAUDE.md er allerede en ting – bare ikke «universell»
Det som gjør dette prosjektet interessant er ikke at det oppdager noe nytt. CLAUDE.md har eksistert siden Claude Code ble lansert. Det interessante er at noen har laget en «drop-in» versjon som er optimalisert for token-effektivitet og delt den åpent.
Og det funker faktisk – innenfor sine begrensninger. Problemet er «universell»-påstanden. Det finnes ingen universell CLAUDE.md som passer alle. Mine prosjekter har CLAUDE.md-filer som er tilpasset akkurat det prosjektet: stilen, konteksten, og hva jeg trenger Claude til å huske mellom øktene. En generisk versjon er et godt utgangspunkt, men den trenger tilpasning.
Lignende tokenreduksjon-tankegang har dukket opp på andre måter – jeg skrev nylig om Claw Compactor, som komprimerer LLM-tokens med 54 prosent uten ML-avhengigheter. Tilnærmingene er forskjellige, men begge handler om å bruke færre tokens for å oppnå det samme.
Er det verdt å prøve?
Ja, med forbehold. Last ned filen, les gjennom den, og fjern instruksjonene som ikke passer ditt bruksmønster. Spesielt ville jeg vurdert nøye om «svar på linje 1 alltid» er noe du vil ha – det kan gå ut over reasoning-kvaliteten på komplekse spørsmål.
Kildekoden er åpen, filen er liten, og eksperimentet koster ingenting. Det er den typen verktøy jeg liker.
Har du testet din egen CLAUDE.md-konfigurasjon? Jeg er nysgjerrig på hva slags instruksjoner som faktisk gir utslag i hverdagen – skriv gjerne i kommentarfeltet.







