

Innhold Vis
21 tokens per sekund med LLaMA.cpp og TurboQuant – men kombiner det med Multi-Token Prediction, og plutselig er du oppe i 34. Det er en økning på 40 %, og det skjer på en vanlig MacBook Pro med M5 Max-chip og 64 GB RAM.
Prosjektet bak dette heter atomic-llama-cpp-turboquant, et community-drevet fork av LLaMA.cpp som patcher inn MTP-støtte og kombinerer det med TurboQuant KV-cache-komprimering. Resultatet er at Qwen 3.6 27B – en 27 milliarders parametersmodell – kjører raskere enn mange hadde ventet var mulig på forbrukerhardware.
Her ser jeg nærmere på hva som faktisk skjer under panseret, og hvorfor kombinasjonen av disse to teknologiene slår dem enkeltvis.
Hva er MTP og TurboQuant, og hvorfor kombinere dem?
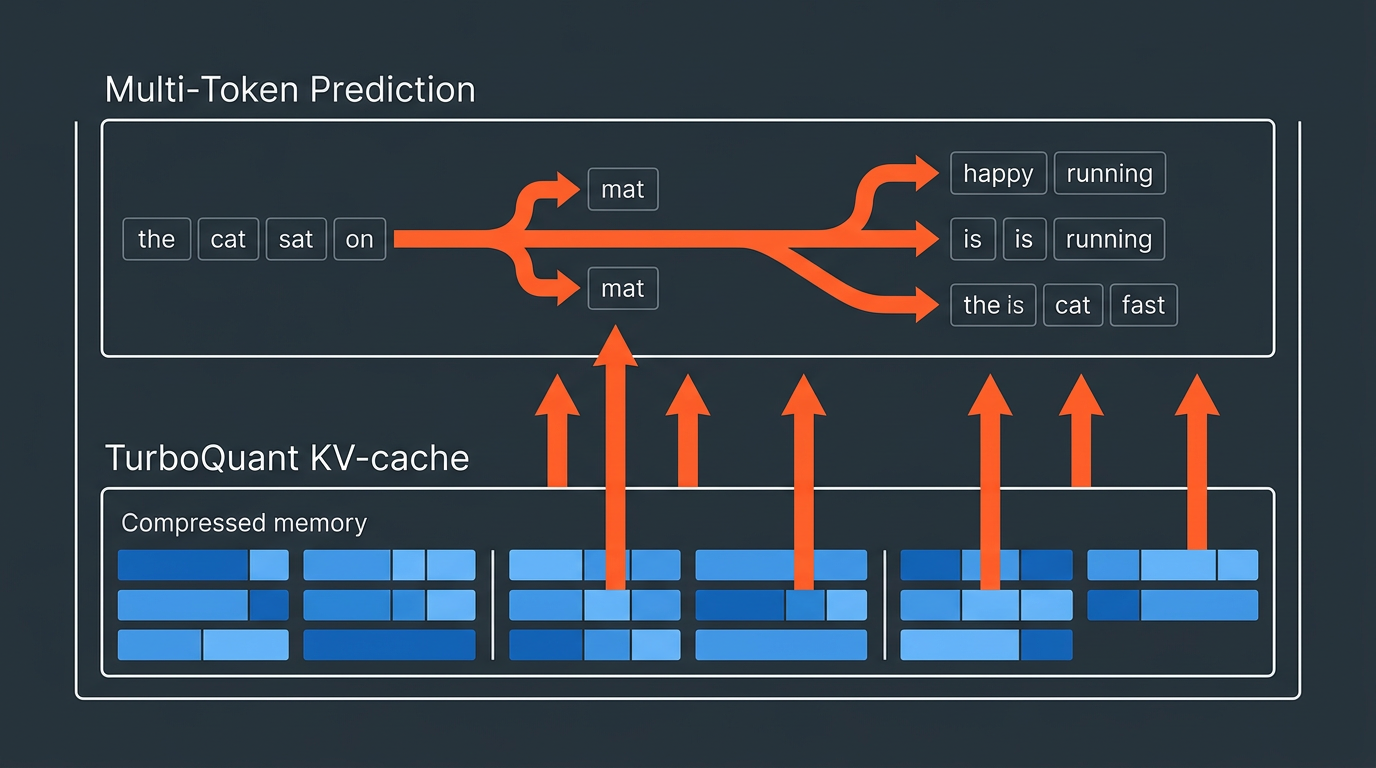
Multi-Token Prediction (MTP) er en teknikk der modellen gjetter flere tokens fremover i stedet for å produsere én om gangen. Jeg har skrevet mer grundig om dette i forklaringsartikkelen om MTP og speculative decoding, men kortversjonen er: ved å bruke et lite «utkast-hode» som gjetter de neste 2-4 tokenene, kan hoved-modellen verifisere dem i én runde i stedet for å generere dem sekvensielt. Akseptansegraden i dette prosjektet er 90 %, noe som betyr at nesten alle gjettene er riktige.
TurboQuant er en annen sak. Det er en kvantiseringsmetode som komprimerer KV-cachen – den midlertidige minnetabellen modellen bruker for å holde kontekst – ned til 2, 3 eller 4 bits i stedet for 16. TurboQuant bruker WHT-rotert Lloyd-Max-kvantisering, noe som gir remarkabelt lite nøyaktighetstap. Med turbo3 (4,3× komprimering mot F16) frigjøres nok minnebåndbredde til at modellen kan prosessere data raskere.
Alene gir hver teknologi en gevinst. Sammen forsterker de hverandre: TurboQuant frigjør minnebåndbredde, og den ekstra kapasiteten brukes av MTP til å verifisere flertokens-gjett raskere. Summen av de to er mer enn delene.
Hva er ytelsestallene i praksis?
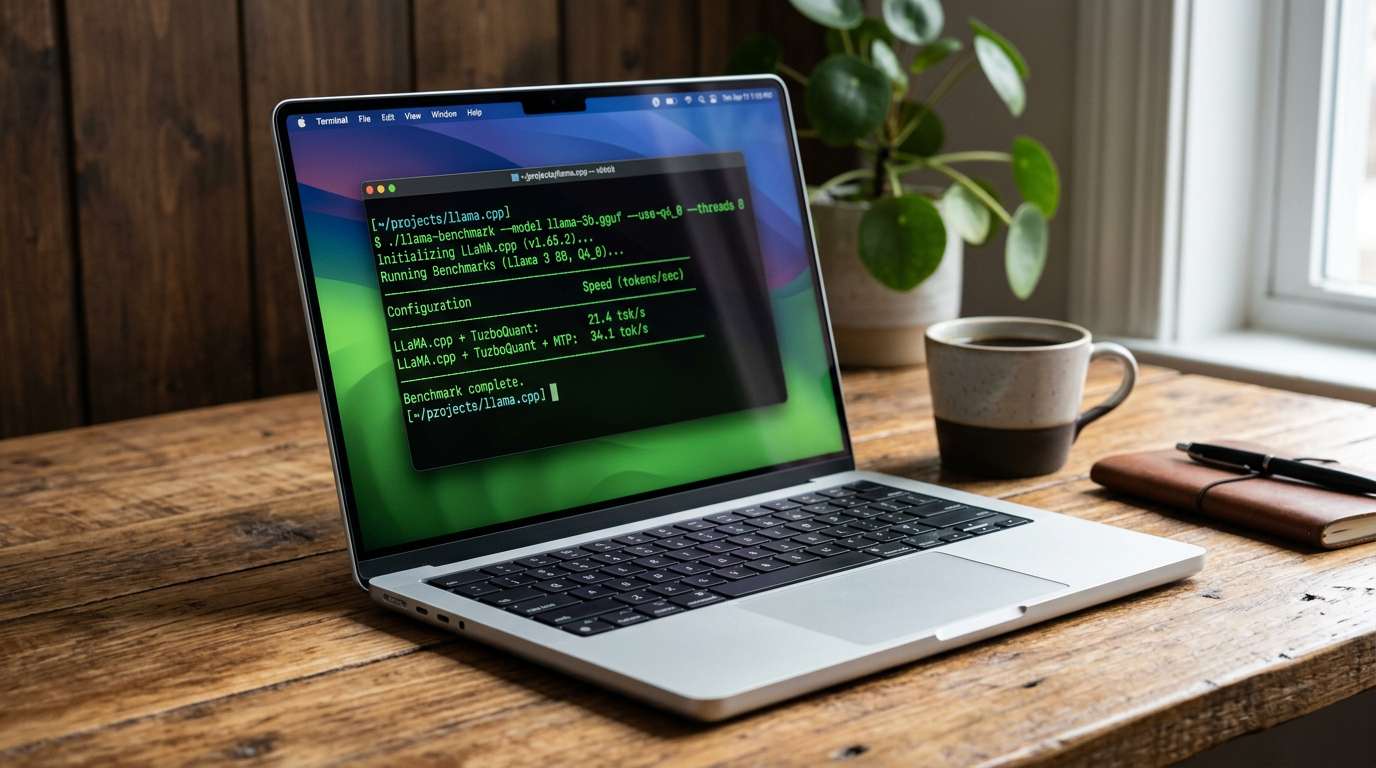
Tallene fra prosjektet er målte på MacBook Pro med M5 Max og 64 GB RAM:
- Kun LLaMA.cpp + TurboQuant: 21 tokens per sekund
- LLaMA.cpp + TurboQuant + MTP: 34 tokens per sekund
Det er 13 tokens mer per sekund – en økning på nøyaktig 62 % fra basislinjen. Og 90 % akseptanserate betyr at MTP-hodene treffer blink nesten hver gang. En dårlig akseptanserate (under 60-70 %) ville sluppet disse tallene tilbake, men 90 % er godt over det som trengs for reell gevinst.
Til sammenligning: LLaMA.cpp med offisiell MTP-beta-støtte gir opptil 2,4 ganger raskere inferens under ideelle forhold, men det er toppnivå. Her ser vi +40 % på en kombinert baseline som allerede inkluderer TurboQuant-optimering. Det er en solid gevinst oppå en allerede optimert stack.
MoE-varianten Qwen 3.6 35B-A3B er også støttet. Den bruker Mixture of Experts-arkitektur, som betyr at bare en del av parametrene er aktive per token. For den varianten melder prosjektet 24-36 % økning i tokens per sekund med turbo3 KV-cache.
Hvilke modeller støttes, og hvordan laster du dem ned?
AtomicChat har kvantisert to Qwen 3.6-varianter med MTP-hoder bygget inn i GGUF-formatet. De finnes på HuggingFace under AtomicChat/qwen-36-udt-mtp:
- Qwen 3.6-27B-UDT-MTP-GGUF (tett modell, 27 milliarder parametre)
- Qwen 3.6-35B-A3B-UDT-MTP-GGUF (MoE-variant, 35B total / 3B aktiv per token)
Begge er dynamic-imatrix GGUF-kvantiserte og støtter TurboQuant3 KV. «UDT» i navnene refererer til «Unified Dynamic Tokenizer». Modellene er klare for bruk med den patchede LLaMA.cpp-builden fra prosjektet.
Koden og instruksjoner finnes i atomic-llama-cpp-turboquant på GitHub. Bygger du fra source med CMake, er prosessen standard LLaMA.cpp-bygging – ingen eksotiske avhengigheter kreves.
Hvordan kjøre det – grunnleggende oppsett
Selve serveren startes med kjente LLaMA.cpp-flagg, men med noen nye tillegg for TurboQuant KV og MTP:
llama-server -m qwen3.6-27b-mtp.gguf -c 32768 -ngl 99 \
-ctk turbo3 -ctv turbo3 -fa onHer setter -ctk turbo3 og -ctv turbo3 KV-cache-komprimering til turbo3-nivå (4,3× komprimering). -fa on aktiverer flash attention, som Apple Silicon-brukere bør ha på. MTP-støtten aktiveres automatisk når modellen har MTP-hoder inkludert i GGUF-filen.
For å få full effekt på Apple Silicon bør du bruke Metal-backend – det er standard i LLaMA.cpp-builden på macOS, og TurboFlash flash-attention-kjernen er dedikert optimert for Metal. Prosjektet støtter også CUDA, Vulkan, HIP og CPU, så det er ikke begrenset til Mac-brukere.
Hva betyr dette for deg som kjører AI lokalt?
Dette er interessant av én enkel grunn: modellen er ikke begrenset til én konkret hardware-plattform, og forbedringen er reell på vanlig forbrukerhardware. Du trenger ikke en dedikert GPU-server for å få nytte av det.
MacBook Pro M5 Max med 64 GB RAM er ikke billig, men det er en bærbar maskin folk faktisk bruker. Qwen3.5 122B er fortsatt en sterk kandidat for lokal LLM, men Qwen 3.6 27B til 34 tokens per sekund er i et brukbart interaktivt modus – fort nok til å ha en flytende samtale uten å vente.
Til sammenligning viser MTPLX-prosjektet at Qwen3.6-27B kan komme opp i 63 tokens per sekund på M5 Max med en annen tilnærming. De to prosjektene overlapper i målsetning men ikke i metode – MTPLX bruker en egenutviklet inferensmotor, mens atomic-llama-cpp-turboquant bygger direkte på LLaMA.cpp som mange allerede bruker. Stabiliteten i en kjent codebase er en fordel for folk som vil ha noe som bare virker.
MTP-støtte i LLaMA.cpp er uansett i rask utvikling. Google fjernet MTP fra offentlige Gemma 4-modeller – men open source-communityen bygger dette inn i eksisterende modeller på egenhånd. Det er slik det pleier å gå.
Hvis du allerede kjører Qwen 3.6 lokalt og har en M-serie Mac med nok RAM, er det liten grunn til å ikke prøve denne patchede builden. Verste fall er at du bytter tilbake. Beste fall er 40 % raskere inferens uten en eneste ekstra kostnad.







