

Innhold Vis
Tradisjonell OCR gir deg en tekststreng. Mistral OCR 4, lansert 23. juni 2026, gir deg en strukturert beskrivelse av hele dokumentet – med posisjoner, klassifisering og konfidenskår for hvert eneste ord. Det høres kanskje ut som en liten oppgradering, men for deg som bygger søkesystemer eller dokumentpipelines er det en ganske vesentlig forskjell.
Problemet med vanlig OCR i RAG-sammenheng har alltid vært det samme: du får ut tekst, men du mister konteksten. En tabell blir en lang rekke tall. En overskrift ser ut som en vanlig setning. Og sitater er umulige å verifisere fordi du ikke vet hvor på siden de stammer fra. Mistral OCR 4 er bygget for å løse akkurat dette.
Modellen støtter PDF, DOC, PPT og OpenDocument-formater, kjører i én enkelt selvhostet container for enterprise-kunder, og eksponeres gjennom ett API-endepunkt enten du vil ha rå tekstekstraksjon eller skjemadrevet Document AI. Her er hva som faktisk er nytt.
Hva er egentlig forskjellen fra vanlig OCR?
Vanlig OCR scanner et bilde eller en PDF og returnerer tekst. Det fungerer greit for enkle dokumenter, men begynner å slite så snart du har tabeller, ligninger, signaturer eller blandet layout. Du får ut noe som ser ut som tekst, men strukturen er borte.
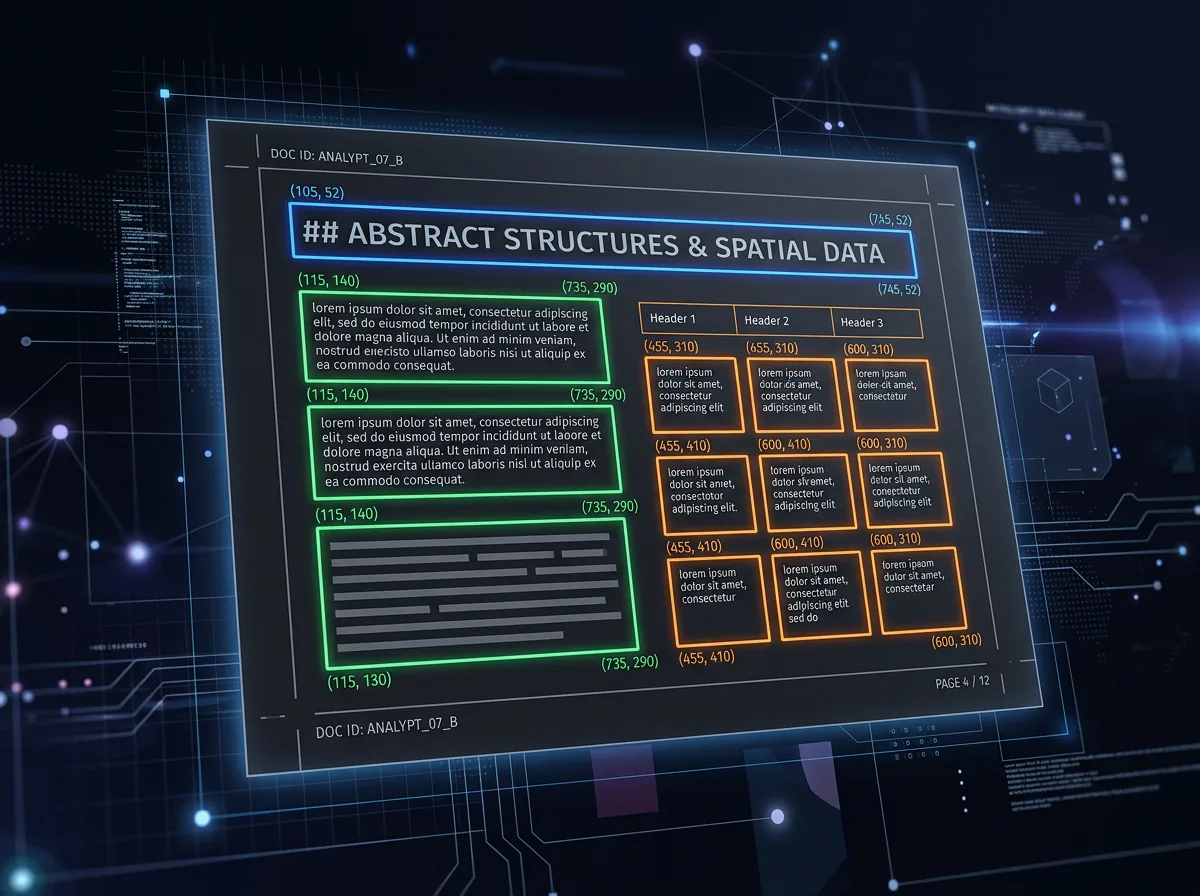
Mistral OCR 4 returnerer derimot noe mer – for hver blokk i dokumentet får du en bounding box (koordinatene for hvor blokken er på siden), en klassifisering av hva slags element det er (tittel, tabell, ligning, signatur, brødtekst og så videre), og konfidenskår på to nivåer: per side og per ord. Du velger selv granularitet – enten aggregerte sidetall eller per-ord-konfidenskår om du trenger det.
Det betyr at et juridisk dokument ikke lenger blir en tekststreng du må parse selv. Overskriften vet at den er en overskrift. Tabellen beholder sin tabellstruktur. Og en setning du trekker ut til et RAG-system bærer med seg nøyaktig informasjon om hvilken side og hvilken posisjon den stammer fra – klar for sitering.
Hva betyr dette i praksis for RAG-systemer?
La oss si du bygger et søkesystem over et stort arkiv med kontrakter eller juridiske dokumenter. Med vanlig OCR ender du opp med en blanding av tekst der du ikke vet om en setning er fra en overskrift, en klausul eller en fotnote. Når systemet ditt finner et relevant utdrag og du skal presentere det for brukeren, kan du ikke peke til nøyaktig kilde uten mye manuelt etterarbeid.
Med Mistral OCR 4 er det annerledes. Hvert tekstsegment har allerede et bounding box-koordinat festet til seg. Du kan si «denne setningen er fra side 7, koordinat (142, 380, 640, 412)» og bygge et direkte referanselenke tilbake til originalposisjonen. Det er citation-ready output fra starten av, uten postprosessering.
For agentic workflows er dette enda viktigere. En AI-agent som skal behandle fakturaer, fylle ut skjemaer basert på kontrakter eller sammenligne dokumentversjoner trenger ikke bare teksten – den trenger å vite strukturen. Mistral OCR 4 gjør at agenten kan behandle «Betalingsfrist»-feltet i en faktura som et navngitt felt med en kjent posisjon, ikke som en tilfeldig setning midt i tekststrengen. Hvis du vil grave dypere i hvordan agenter henter og bruker dokumentkontekst, har jeg skrevet om agentic RAG i et eget innlegg.
Prisen er 4 dollar per tusen sider via standard API, eller 2 dollar per tusen sider via Batch API. Document AI-modus, der du gir modellen et spesifikt skjema å fylle ut, koster 5 dollar per tusen sider. For de fleste dokumentbehandlingsscenarier er det rimelig – en hel kontrakt på 20 sider koster deg åtte cent.
170 språk og selvhosting – to ting som teller for enterprise
Mistral OCR 4 støtter 170 språk fordelt på ti språkgrupper, med spesifikke forbedringer for lavressursspråk. Det er ikke bare en fin statistikk – det betyr at systemet håndterer norske dokumenter, flerspråklige kontrakter og arkivmateriale fra ulike land uten å måtte sende alt gjennom separate modeller.
Selvhostingalternativet er det andre punktet som gjør dette interessant for enterprise. Hele modellen kjører i én enkelt container. Det vil si at sensitive dokumenter – pasientjournaler, juridiske saksdokumenter, konfidensiell forretningsinformasjon – aldri trenger å forlate ditt eget nettverk. Du setter opp containeren, peker API-kallet mot din egen infrastruktur, og prosesserer lokalt.
Det er ikke alle OCR-tjenester som tilbyr dette. Google Document AI og Azure Form Recognizer er skydrevne tjenester der dokumentene sendes til eksterne servere. Mistral OCR 4 gir deg alternativet til å holde alt in-house, noe som for mange organisasjoner ikke er et valg men et krav.
Mistral har vært konsistente i sin strategi med åpne og selvhostbare alternativer på tvers av modellene sine – jeg har skrevet om det samme mønsteret i forbindelse med Mistral Small 4 og Mistral Small Creative. OCR 4 følger samme linje.

Hva passer Mistral OCR 4 til – og hva passer det ikke til?
Modellen er tydelig posisjonert for dokumentheavy brukstilfeller der struktur og sitering betyr noe. Juridisk dokumentanalyse er det åpenbare eksempelet – du har hundrevis av kontrakter, du vil søke i dem, og du vil at systemet skal kunne peke nøyaktig til kilden når det finner noe relevant. Samme logikk gjelder for fakturabehandling, compliance-gjennomgang og digitalisering av historiske arkiver.
Det er også en naturlig del av pipelines der du har konfidensgate-logikk. Et system som prosesserer medisinske journaler og bare sender videre tekst der modellen er minst 95% sikker, er mye enklere å bygge når du faktisk har per-ord-konfidenskår tilgjengelig. Du trenger ikke prøve å gjette usikkerhet selv.
Der OCR 4 er overkill er enkle dokumenter med ren tekst, der du bare vil ha innholdet uten å bry deg om struktur. For det finnes billigere og enklere løsninger. OCR 4 er laget for de tilfellene der dokumentets layout faktisk betyr noe for det du skal gjøre med innholdet etterpå.
Konkurransen i dette segmentet er reell – NuExtract3 er et open-source alternativ med sterk ytelse på JSON-ekstraksjon, og Qwen-modellene har vist gode resultater på OCR-benchmarks. Mistral OCR 4 skiller seg med den kombinerte støtten for selvhosting, bred språkdekning og det strukturerte output-formatet som er direkte spiselig for RAG-systemer uten mellomliggende parsing.
Ofte stilte spørsmål
Hva koster Mistral OCR 4 per side?
Standard API koster 4 dollar per tusen sider (~0,044 kroner per side). Batch API gir 50% rabatt til 2 dollar per tusen sider. Document AI-modus, der du oppgir et spesifikt skjema for modellen å fylle ut, koster 5 dollar per tusen sider.
Kan jeg kjøre Mistral OCR 4 lokalt uten å sende dokumenter til skyen?
Ja. Mistral tilbyr selvhosting for enterprise-kunder via en enkelt container. Alle dokumenter forblir i ditt eget nettverk, noe som er avgjørende for sensitive data som pasientjournaler eller konfidensiell forretningsinformasjon.
Hvilke filformater støtter Mistral OCR 4?
Modellen godtar PDF, DOC, PPT og OpenDocument-formater. Den støtter 170 språk fordelt på ti språkgrupper, inkludert norsk og lavressursspråk med begrenset treningsdata.
Hva er forskjellen mellom OCR 4 og vanlig OCR for RAG-systemer?
Vanlig OCR returnerer en tekststreng uten posisjonsinformasjon. OCR 4 returnerer strukturert output med bounding boxes, blokktypeklassifisering og konfidenskår per ord – slik at hvert tekstsegment vet nøyaktig hvor på siden det stammer fra, klar for sitering i RAG-pipelines.







