
Innhold Vis
Systematisk prompting er fem konkrete teknikker som gjør AI-svar pålitelige nok for produksjonssystemer – ikke bare «ganske bra» i testing. De fem metodene er rolle-spesifikk prompting, negativ prompting, JSON-strukturerte svar, attentive reasoning queries (ARQ) og verbalized sampling. Ingen av dem krever modelltrening eller infrastrukturendringer – alt skjer i selve prompten.
De fleste som bruker AI i dag skriver en rimelig prompt, ser hva de får, og justerer. Det fungerer greit for personlig bruk. Men når du begynner å bygge systemer som kjører automatisk – fakturabehandling, kodegenerering, innholdspipelines – er «ganske bra» ikke godt nok. Én uventet svingtur fra modellen kan knekke hele flyten.
Her er en gjennomgang av de fem teknikkene som faktisk gir forutsigbare resultater – med eksempler du kan bruke med en gang.
Hva er systematisk prompting?
Det er en tilnærming der du behandler prompts som kode, ikke som samtale. Du definerer nøyaktig hva du vil ha, hva du ikke vil ha, og i hvilket format svaret skal komme. Resultatet er at modellen oppfører seg mer som en funksjon med kjent input/output enn som en chat-partner med humørsvingninger.
Disse teknikkene stammer fra AI-forskningsmiljøet og er formalisert etter hvert som språkmodeller har beveget seg fra hobbyprosjekter til produksjonssystemer. Det handler ikke om å finne magiske ord – det handler om å gi modellen presis nok kontekst til at den ikke trenger å gjette.
Grunnprinsippet fra min komplette prompting-guide holder fortsatt: spesifisitet, struktur og kontekst. De fem teknikkene er en systematisering av akkurat det.
Teknikk 1: Rolle-spesifikk prompting – hvorfor «ekspert» ikke er nok
De fleste har prøvd «Du er en ekspert på X» i system-prompten. Det hjelper, men det er en halvferdig løsning. Rolle-spesifikk prompting går lenger: du tildeler modellen en spesifikk domenepersona og beskriver tankemønstrene og prioriteringene som følger med den rollen.
Forskjellen er vesentlig. «Du er en sikkerhetsforsker» er åpent for tolkning. «Du er en senior sikkerhetsforsker som prioriterer trusselmodellering over compliance-sjekklister, og som alltid vurderer angriperens perspektiv før forsvarerens» – det gir modellen en konkret linse å se problemet gjennom.
I praksis filtrerer dette modellens kunnskap gjennom domenets egne prioriteringer. En juridisk revisor tenker annerledes enn en advokat. En systemarkitekt tenker annerledes enn en frontend-utvikler. Gi modellen den spesifikke tankemodellen, ikke bare tittelen. For en grundig forklaring av hvor rolle-prompten hører hjemme teknisk, se guiden om system prompt vs user prompt.
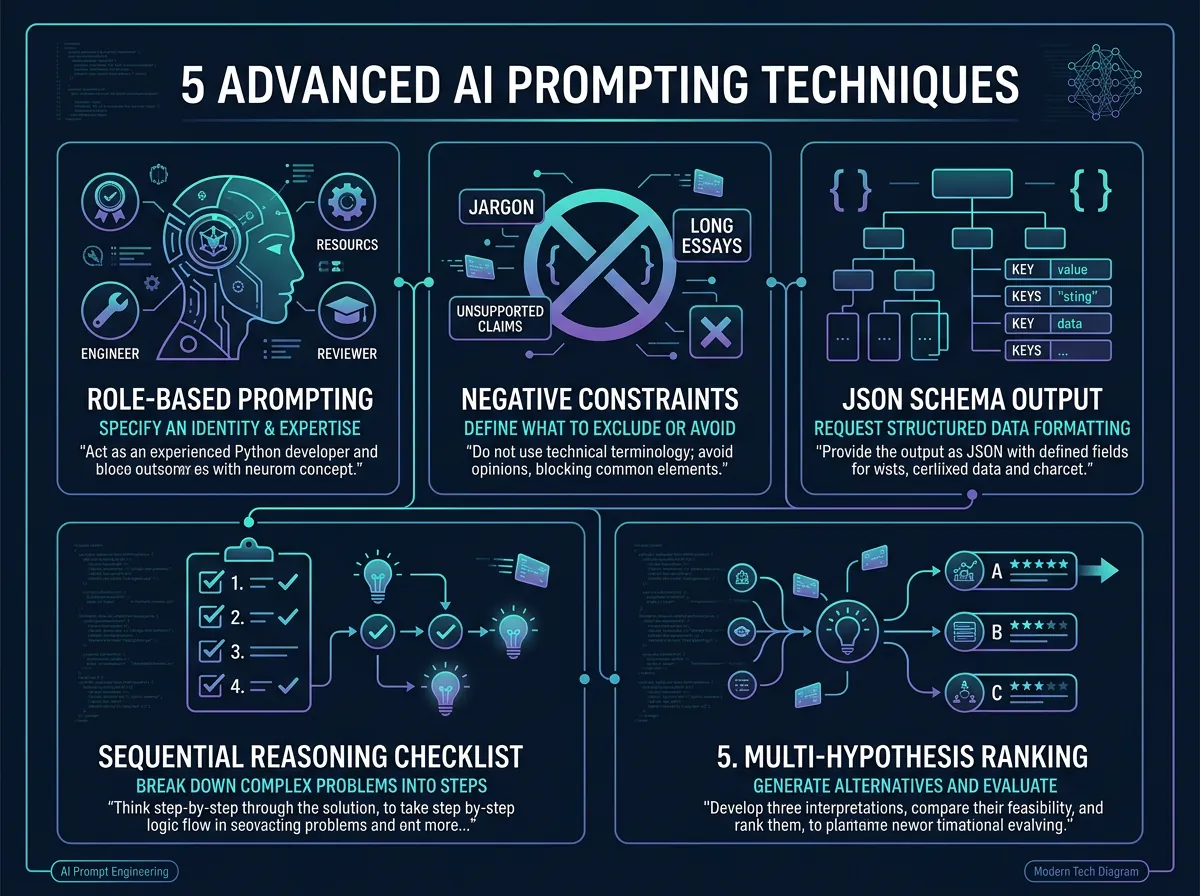
Teknikk 2: Negativ prompting – fortell AI hva den IKKE skal gjøre
Dette er kanskje den mest undervurderte teknikken av de fem. De fleste prompt-er forteller modellen hva den skal gjøre. Negativ prompting legger eksplisitt til hva den ikke skal gjøre.
Eksempel: Du ber om en produktanalyse og legger til «Unngå markedsføringsspråk, fyllfraser og vage generaliseringer. Ikke bruk ord som ‘revolusjonerende’, ‘banebrytende’ eller ‘best-in-class’.» Resultatet er analyser som faktisk er nyttige, ikke reklamekopi.
Det morsomme er at dette speiler noe jeg har skrevet om i artikkelen om vanlige prompting-feil: modeller har en tendens til å gi deg det de tror du vil ha, ikke det du faktisk trenger. Negativ prompting brekker den syklusen ved å lukke bakdørene modellen ellers vandrer gjennom.
Teknisk sett fungerer det ved å innsnevre sannsynlighetsrommet for neste token. Når du sier «ikke bruk listepunkter», fjerner du hele den klassen av svar fra kandidatene. Resultatet er tettere, mer direkte output.
Teknikk 3: JSON-strukturerte svar – gjør AI-output maskinleselig
Hvis du bygger automatiserte pipelines der AI-output skal prosesseres videre, er ustrukturert tekst et problem. JSON-prompting løser det ved å definere et strengt schema i prompten og kreve at svaret følger det.
Et konkret eksempel fra originalartikkelen: i stedet for å be om «en analyse av dette produktet», ber du om et JSON-svar med felt som «pros», «cons», «rating» og «recommendation». Svaret er direkte parseable og kan sendes videre til neste steg i pipelinen uten manuell tolkning.
For de som bruker API-er direkte: dette er grunnen til at Claude, GPT-4 og Gemini alle støtter JSON-modus og function calling. Systematisk JSON-prompting lar deg få det samme resultatet uten å lene deg på modellspesifikke features – det fungerer på tvers av alle modeller. Og som jeg forklarer i guiden om system prompts: schema-definisjonen hører hjemme i system-prompten, der den gjelder for alle svar i sesjonen.
Hva er Attentive Reasoning Queries (ARQ)?
ARQ er en mer sofistikert erstatning for standard chain-of-thought prompting. I stedet for å bare si «tenk steg for steg», gir ARQ modellen en fast sjekkliste av domenespesifikke spørsmål den må besvare sekvensielt.
Forskjellen er viktig. Vanlig chain-of-thought lar modellen bestemme hva som er relevant å tenke på. ARQ overstyrer det med en forhåndsdefinert struktur. For en sikkerhetsanalyse kan sjekklisten være: 1) Identifiser angripervektorer, 2) Vurder konsekvens ved brudd, 3) Evaluer eksisterende kontroller, 4) Prioriter risikoer etter sannsynlighet × konsekvens.
Dette sikrer at alle kritiske aspekter dekkes, ikke bare de modellen finner mest interessante å snakke om. I produksjonssystemer der konsistens er viktig – tenk medisinske diagnoser, juridiske vurderinger, finansiell risiko – er ARQ vesentlig mer pålitelig enn fri chain-of-thought. Du kan lese mer om beslektede resonneringsteknikker i AI-ordlisten under «chain-of-thought».

Teknikk 5: Verbalized sampling – la AI innrømme usikkerhet
Dette er kanskje den mest verdifulle teknikken for beslutningsstøtte. I stedet for å be om ett svar, ber du modellen om flere rangerte hypoteser med konfidensscorer.
Eksempel: «Gi meg de tre mest sannsynlige årsakene til dette problemet, rangert fra mest til minst sannsynlig. For hver årsak, oppgi en konfidensscore fra 0-100 og hva som ville bekrefte eller avkrefte hypotesen.»
Resultatet er to ting: du unngår falsk sikkerhet (modellen gir deg ett svar som virker autoritativt, men egentlig bare er det mest sannsynlige alternativet), og du får eksplisitte valideringskriterier for hver hypotese. Det er mye mer nyttig for faktisk beslutningstaking enn ett enkelt svar levert med overbevisende tone.
Hvilke teknikker bør du prioritere?
Det avhenger av hva du bygger. For automatiserte pipelines er JSON-prompting og negativ prompting de viktigste – de sikrer at output er maskinleselig og fri for støy. For beslutningsstøtte er verbalized sampling og ARQ mer verdifulle. Rolle-spesifikk prompting er nyttig i begge kontekster.
Det viktigste poenget er at disse teknikkene ikke er «tips og triks» – de er en ingeniørdisiplin. Når du behandler prompts med samme grundighet som kode, går du fra «ganske bra» til «pålitelig nok for produksjon». Det er et fundamentalt skifte i hvordan du tenker på AI i systemene dine.
Ingen av dem krever at du bytter modell, betaler for fine-tuning eller endrer infrastruktur. Alt skjer i teksten du sender. For å komme i gang med grunnprinsippene, se den komplette prompting-guiden og artikkelen om å slutte å krangle med ChatGPT. Ganske elegant, egentlig.
Har du testet noen av disse teknikkene? Jeg er nysgjerrig på hvilke du finner mest nyttige – og om det er kombinasjoner som fungerer spesielt godt.







