

Innhold Vis
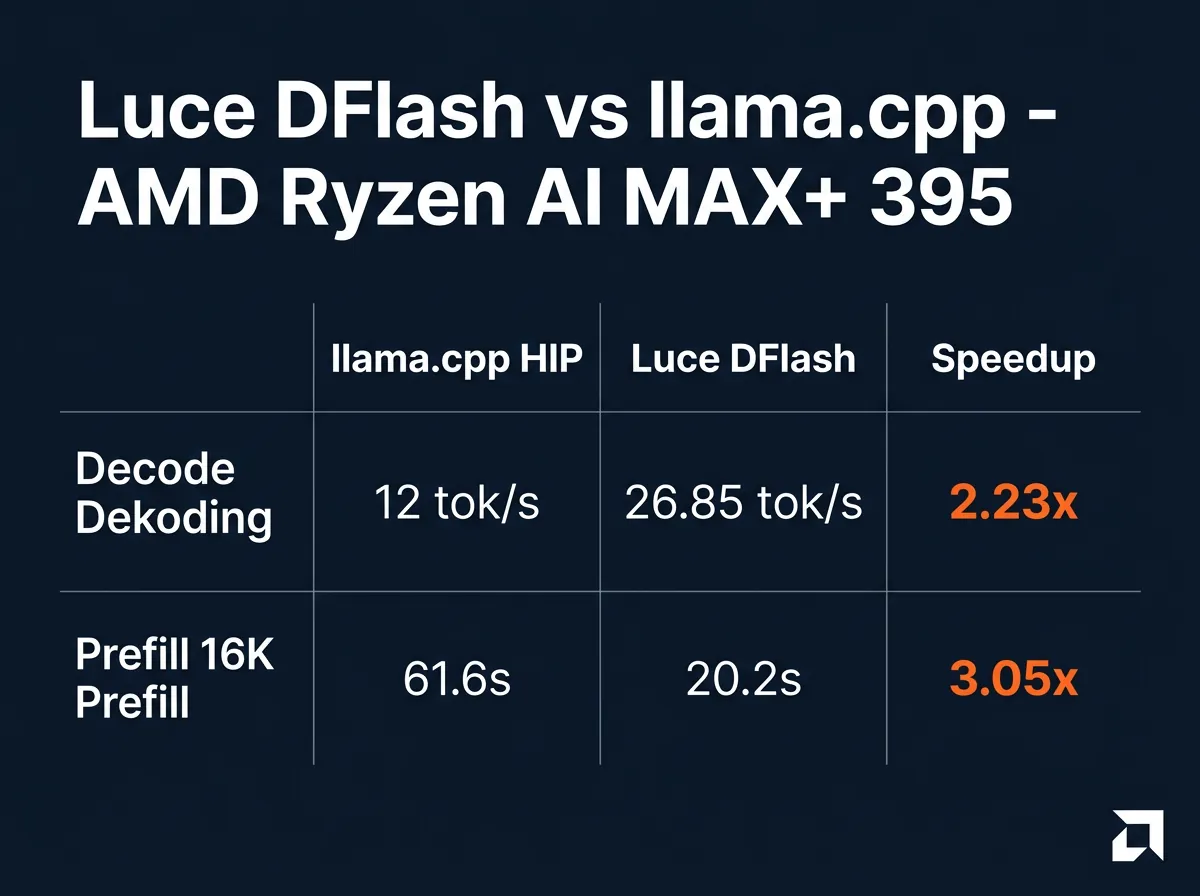
Luce har nå portert DFlash og PFlash til AMD Ryzen AI MAX+ 395 – den kraftige APU-en med 128 GB unified memory som sitter i Asus ROG Ally X og lignende maskiner. Det betyr at Qwen3.6-27B nå kjører 2,23 ganger raskere i decode og 3,05 ganger raskere i prefill sammenlignet med vanlig llama.cpp HIP på samme hardware. Alt via MIT-lisensiert kode publisert på GitHub.
Det er verdt å merke seg at vi allerede har sett DFlash levere heftige resultater på NVIDIA-hardware – blant annet ExLlamaV3 DFlash som ga 2,5 ganger raskere inferens. Nå krysser den altså over til AMD, og da spesielt til en plattform mange hobby-brukere faktisk eier eller vurderer.
AMD Strix Halo har vært spennende på papiret en stund – 128 GB unified memory er et slags lokalt LLM-drømmeoppsett. Spørsmålet er om programvaren klarer å utnytte det. Luce-teamets arbeid er et konkret svar på det spørsmålet.
Hva er DFlash og PFlash?
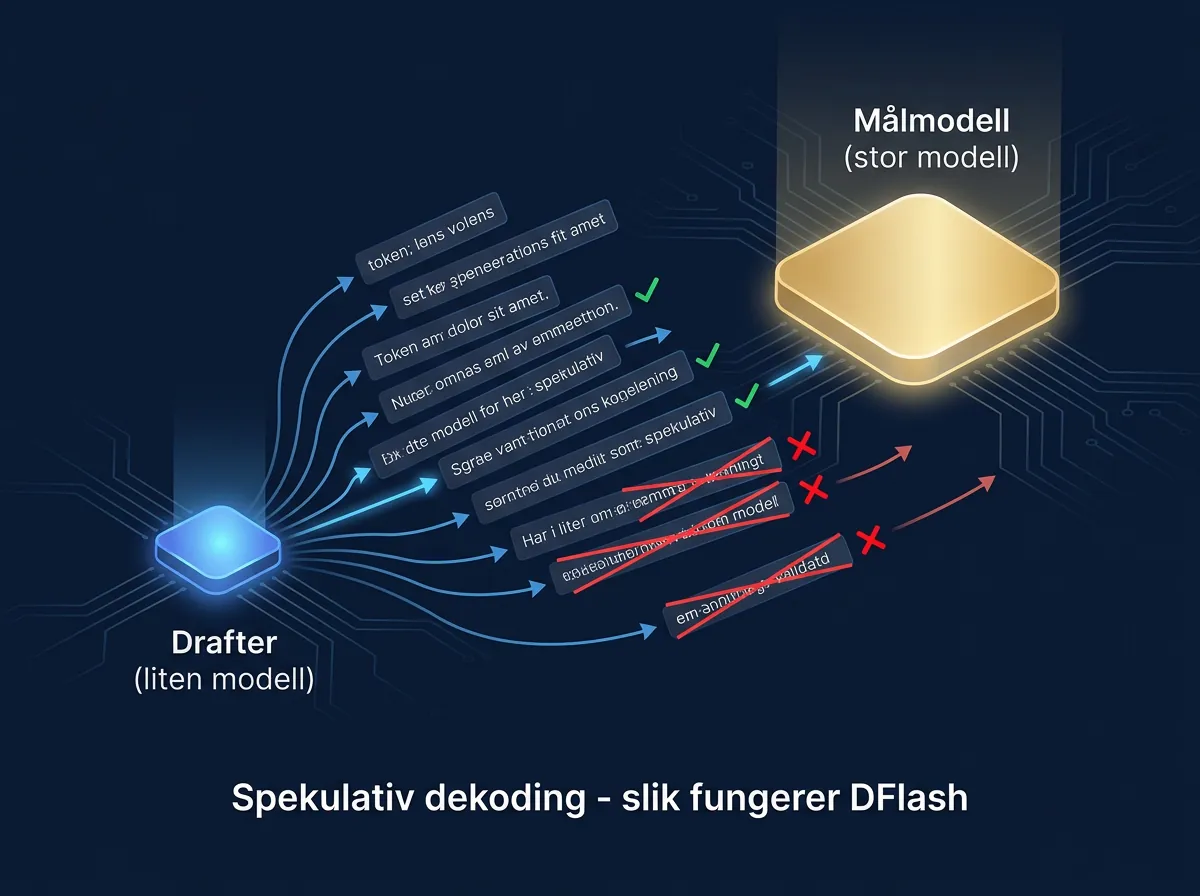
DFlash er en spekulativ dekodingsimplementering basert på en teknikk kalt «block-diffusion draft conditioned on target hidden states». I praksis betyr det at en liten drafter-modell (Qwen3-0.6B BF16) foreslår flere tokens fremover, og målmodellen bekrefter eller forkaster dem i blokker. Når det stemmer – og det gjør det ofte – sparer du enormt mange forward passes.
PFlash er en komplementær teknikk for prefill-fasen. I stedet for å la målmodellen prosessere hele prompten token for token, bruker PFlash drafteren til å score hvilke deler av prompten som er viktige. Bare de viktige delene sendes til målmodellen. Ved 16K kontekst – som er testet i denne kjøringen – gir det en dramatisk reduksjon i ventetid før modellen begynner å svare.
Det tekniske fundamentet er de samme HIP-kjernene Luce brukte på RTX 3090-kjøringen for noen uker siden, nå portert til AMD gfx1151-arkitekturen (Strix Halo). Det er ikke trivielt – AMD HIP er ikke CUDA, og mange optimaliseringer som fungerer godt på NVIDIA-arkitektur må skrives om fra bunnen av.
Hva er AMD Ryzen AI MAX+ 395 og Strix Halo?
Ryzen AI MAX+ 395 er AMDs kraftigste APU per nå – en brikke med 16 Zen 5-kjerner og en iGPU som deler 128 GB LPDDR5X-minne med CPU-en. Det er unified memory, samme prinsipp som Apple Silicon, men på AMD-plattformen. Datamaskinene som bruker denne brikken er typisk i klassen handheld gaming PC og high-end laptops.
128 GB unified memory er mer enn nok til å kjøre svært store modeller. Qwen3.6-27B Q4_K_M veier rundt 15-17 GB kvantisert, så dette er ikke problemet. Problemet har tradisjonelt vært at iGPU-ene i APU-klassen har lav minnebåndbredde sammenlignet med dedikerte GPU-er, og dermed treg inferens. Det er akkurat det DFlash og PFlash forsøker å kompensere for.
Hva sier tallene egentlig?
End-to-end på Qwen3.6-27B Q4_K_M med Luce Q8_0 DFlash drafter:
- 26,85 tokens per sekund i decode
- 20,2 sekunder prefill ved 16K kontekst
- 2,23 ganger raskere decode enn llama.cpp HIP
- 3,05 ganger raskere prefill enn llama.cpp HIP
26 tokens per sekund på en laptop-APU med en 27B-modell er ganske bra. Til sammenligning er dette i nærheten av hva mange ser på dedikerte GPU-er med eldre arkitektur. Og 3 ganger raskere prefill betyr konkret at en lang samtalehistorikk eller et langt dokument prosesseres mye raskere før du får første svar.
Det er verdt å sette dette i kontekst. llama.cpp MTP-støtte i beta leverte opptil 2,4 ganger raskere inferens på NVIDIA. Luce DFlash leverer 2,23 ganger på AMD APU. Det er sammenlignbare tall, men på fundamentalt annerledes hardware – og det er poenget.
Hva skiller Luce fra llama.cpp og ExLlamaV3?
llama.cpp er allrounderen – støtter alt, kjører overalt, tusenvis av bidragsytere. Det er standardverktøyet for lokal LLM på de fleste plattformer. Men allrounder-status betyr at den ikke alltid er optimal for én spesifikk arkitektur eller teknikk.
ExLlamaV3 er mer spesialisert – primært NVIDIA, med fokus på EXLM2-kvantitering og spekulativ dekoding. Det er raskere enn llama.cpp på NVIDIA i mange tilfeller, men AMD-støtten har vært begrenset.
Luce posisjonerer seg som et tynt daemon-lag med egendefinerte kjerner bygget spesifikt for DFlash og PFlash. Det er ikke en full inferensmotor i tradisjonell forstand – det er et akselerasjonslag som kan operere på toppen av eksisterende rammeverk. Det gjør det enklere å adoptere for de som allerede har satt opp llama.cpp-baserte løsninger.
For AMD-brukere er dette konkret interessant. AMDs GAIA-rammeverk for lokale AI-agenter er et skritt i riktig retning fra AMD selv, men tredjepartsverktøy som Luce beveger seg raskere.
Hvilke plattformer støtter Luce nå?
Luce støtter per nå følgende hardware:
- NVIDIA: RTX 3090, 4090, 5090, RTX 2080 Ti, DGX Spark/GB10, Jetson AGX Thor
- AMD: Ryzen AI MAX+ 395 (gfx1151 / Strix Halo), gfx1100 og gfx1201 i CMake
Lisensen er MIT, koden ligger åpent på github.com/Luce-Org/lucebox-hub. MIT er den mest permissive lisensen som finnes – du kan gjøre hva du vil med den, også kommersielt.
Modellfokuset er foreløpig Qwen-serien – Qwen3.6-27B og Qwen3.5-27B Q4_K_M er testedmodellene. Drafter-modellen er Qwen3-0.6B BF16. Det betyr at du trenger begge nedlastet for å kjøre DFlash.
Er dette relevant for deg?
Hvis du kjører lokal LLM på en av de nyere AMD APU-maskinene – Asus ROG Ally X, Minisforum AI X1 Pro, eller lignende – er dette direkte relevant. Du har hardware som potensielt kan kjøre 27B-modeller skikkelig raskt, men du har kanskje opplevd at inferenshastigheten var skuffende med standard llama.cpp.
For den mer teknisk interesserte er Luce også interessant som et eksempel på hva som skjer når folk bygger spesialiserte kjerner i stedet for å vente på at generalverktøyene tar igjen. Spekulativ dekoding forklart fra bunnen gir god bakgrunn hvis du vil forstå mekanikken bedre.
Det er fortsatt tidlig. Luce støtter ikke alle modeller, ikke alle plattformer, og dokumentasjonen er sparsom. Men det faktum at de eksplisitt har portert til AMD HIP – og at tallene faktisk holder – er et godt tegn. AMD Strix Halo som lokal LLM-plattform er blitt ett skritt mer attraktivt. Se også testen av Qwen3.5 122B som lokal LLM for mer kontekst om hva som er mulig med store modeller lokalt.








1 kommentar