

Innhold Vis
NuExtract3 er en 4 milliarder parameter vision-language modell som er bygget for én ting: å trekke strukturert informasjon ut av dokumenter. PDF-er, skjemaer, fakturaer, kvitteringer, tabeller – gitt en JSON-mal returnerer modellen presise data i stedet for løs tekst. Apache 2.0-lisens, selvhostbar, og gratis å prøve på HuggingFace uten innlogging.
Modellen er bygget av Numind og baserer seg på Qwen3.5-4B som grunnmodell. Kodenavnet sier egentlig alt: NuExtract – ekstraksjon er hele poenget. Der generelle LLM-er kan hjelpe deg å lese et dokument og oppsummere det, er NuExtract3 laget for å konvertere visuelt strukturert innhold direkte til maskinlesbare data.
Det er en distinksjon som faktisk betyr noe i praksis. Mange AI-arbeidsflyter i 2026 handler om å sette opp en RAG-pipeline eller automatisert dokumentbehandling, og da er nøyaktighet og forutsigbar output det som gjelder – ikke kreativitet eller språklig flyt.
Hva gjør NuExtract3 annerledes enn en vanlig LLM?
En standard LLM kan lese en faktura og fortelle deg hva den inneholder – men output-formatet varierer fra gang til gang. NuExtract3 tar en annen tilnærming: du definerer en JSON-mal med feltene du vil ha ut, og modellen fyller den inn basert på dokumentet. Resultatet er konsistent, strukturert, og direkte brukbart i kode.
Malen-systemet støtter ulike datatyper: verbatim-strenger, dato/tid, tall, valuta og egendefinerte enums. Det betyr at du kan spesifisere at et felt skal være en dato i ISO-format, eller at et annet felt bare kan være én av tre mulige verdier – og modellen forstår det.
I tillegg til strukturert ekstraksjon gjør modellen to ting til: konvertering av dokumentbilder til Markdown, og multimodal input der du kan kombinere tekst og bilder. Alle tre funksjonene er tilgjengelige i både reasoning-modus og ikke-reasoning-modus, avhengig av hva oppgaven krever.
Hvordan er ytelsen sammenlignet med større modeller?
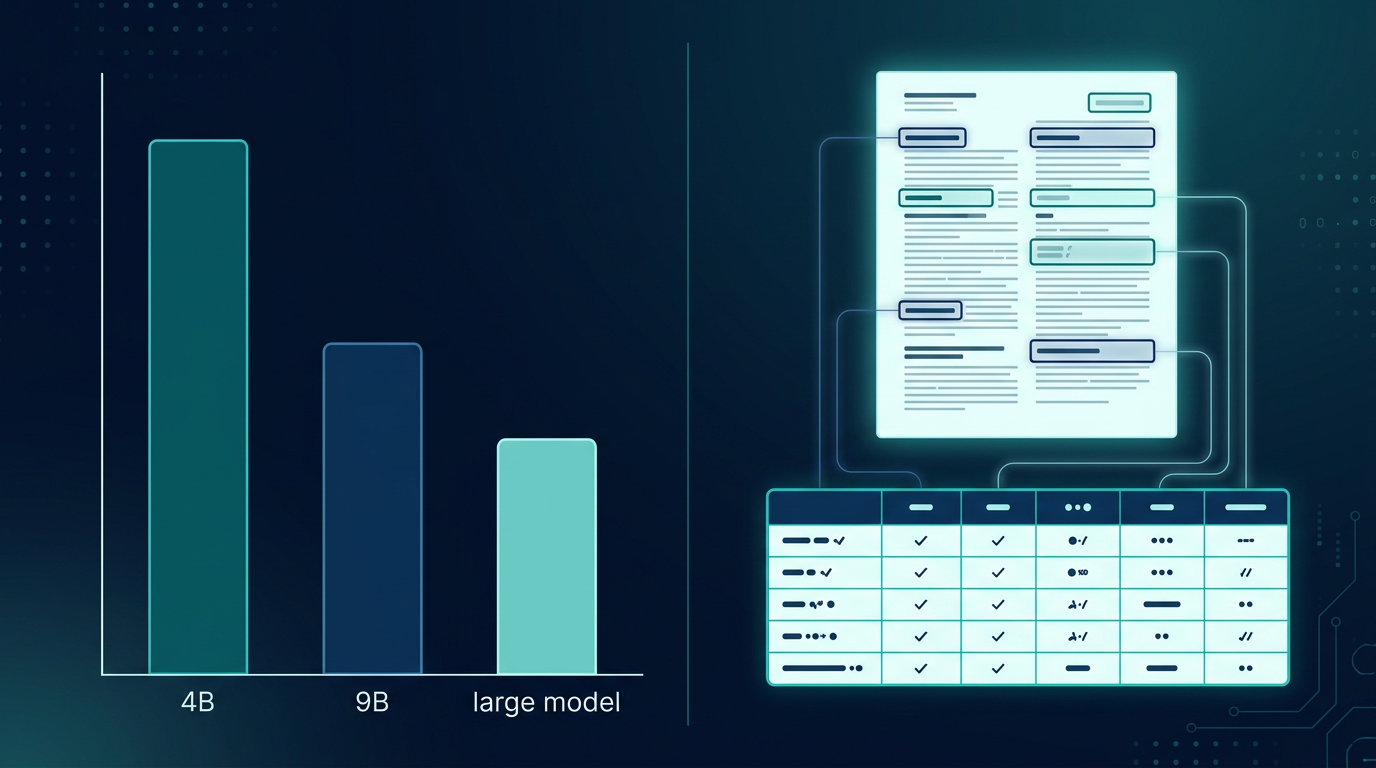
På Numinds interne benchmark – rundt 600 diverse dokumenter inkludert fakturaer og skjemaer – scoret NuExtract3 0,651 i gjennomsnitt på strukturert ekstraksjon. Det høres kanskje ikke spektakulært ut før du ser hva den slår: Qwen3.5-9B scoret 0,479 og Gemma-4-E4B scoret 0,538. En 4B-modell som overgår både en 9B generalist og en konkurrerende 4B-modell på sin spesialoppgave.
Dette er ikke overraskende hvis man tenker på det. En modell som er spesialisert og finjustert for én oppgave slår generalistmodeller på den oppgaven – det er prinsippet bak verktøyspesialisering. Tidligere forskning viste samme mønster: Qwen 3.5 4B løste abstraksjonstester som mye større modeller feilet på, nettopp fordi størrelse ikke er det eneste som betyr noe.
For Markdown-konvertering scoret modellen 0,683 uten reasoning-modus. En annen interessant funksjon er støtte for Multi Token Prediction, som gir bedre gjennomstrømning ved bruk av spekulativ dekoding – noe jeg har skrevet om i gjennomgangen av MTP og speculative decoding.
Hvilke dokumenttyper støttes?
Listen er bred: kvitteringer, fakturaer, skjemaer, kontrakter, tabeller, plantegninger, skannet papir og diverse andre visuelt strukturerte dokumenter. Modellen er trent til å håndtere både digitalt native PDF og fotograferte dokumenter – altså ekte OCR-tilfeller der bildet ikke er perfekt.
Flerspråklige dokumenter støttes også. Det er ikke uvanlig at norske bedrifter behandler dokumenter på norsk, engelsk og kanskje tysk eller polsk, og da er det et pluss å ikke måtte bytte modell avhengig av språket på inngangsdataene.
For utviklere som bygger RAG-pipelines er Markdown-konverteringsfunksjonen særlig nyttig: i stedet for å sende råtekst fra et PDF-parsing-bibliotek til embedding-modellen, kan du konvertere dokumentet til velformatert Markdown som bevarer struktur, tabeller og hierarki. Det gir langt bedre chunk-kvalitet. Se gjerne oversikten over open source AI-verktøy for kontekst om hva som ellers finnes i dette landskapet.
Hvordan kjører du NuExtract3 selv?
Modellen er tilgjengelig via HuggingFace (numind/NuExtract3-4B) under Apache 2.0-lisens, som betyr at du kan bruke den kommersielt, modifisere den og distribuere den fritt. Gratis demo uten innlogging finnes på HuggingFace Spaces.
For produksjonssetting er den kompatibel med vLLM via OpenAI-kompatibel API – samme grensesnitt som mange allerede bruker for API-tilgang til AI-modeller. Standard HuggingFace Transformers fungerer også for enklere oppsett.
En 4B-modell er relativt håndterbar på moderne hardware. Med 4-bit kvantisering bør den gå på en GPU med rundt 4-6 GB VRAM, noe som gjør den tilgjengelig på forbrukerhardware. For serverkjøring er den lett nok til å kjøre på en enkel A10 eller sammenlignbar GPU uten at det sprenger budsjettet.
Hvem bør se nærmere på dette?
Bedrifter som behandler store mengder dokumenter manuelt er den åpenbare målgruppen. Fakturabehandling, kontraktsgjennomgang, skjemautfylling fra PDF – alt dette er kandidater for automatisering med NuExtract3 som ekstraksjonslag. Kombinert med et orkestreringssystem som for eksempel n8n for automatisering kan man bygge ganske solide arbeidsflyter uten sky-API-kostnader per kall.
For utviklere som allerede bygger med open source modeller er det verdt å teste NuExtract3 spesifikt mot dokumentoppsett der du i dag bruker en generell modell. Spesialiseringseffekten er reell: 0,651 mot 0,479 er ikke marginal forskjell, det er nesten 36 prosent bedre score på samme oppgave med færre parametere.
Apache 2.0-lisensen fjerner den vanlige usikkerheten rundt kommersiell bruk. Ingen proprietære restriksjoner, ingen per-kall-prising, ingen API-hemmeligheter. Det er open source slik det skal fungere – du eier infrastrukturen og dataene.







