

Innhold Vis
Cohere slapp Command A+ den 20. mai 2026 – 218 milliarder parametere totalt, 25 milliarder aktive per token, Apache 2.0-lisens. Og nå er den ute i det ville på Apple Silicon via en ny MLX-port som kom fra fellesskapet i r/LocalLLaMA.
Dette er Coheres svar på spørsmålet: hva er den kraftigste åpne modellen du kan kjøre lokalt? 218B totale parametere høres brutalt ut, men Mixture-of-Experts-arkitekturen betyr at bare 25 milliarder av dem er aktive per forward pass. Det er nøyaktig det som gjør dette interessant for lokalkjøring.
En utvikler gikk inn og implementerte cohere2_moe-støtte direkte i mlx-lm, sendte en pull request, og nå venter verden. Slik fungerer open source.
Hva er Command A+ og hvorfor er 218B ikke så skremmende som det høres ut?
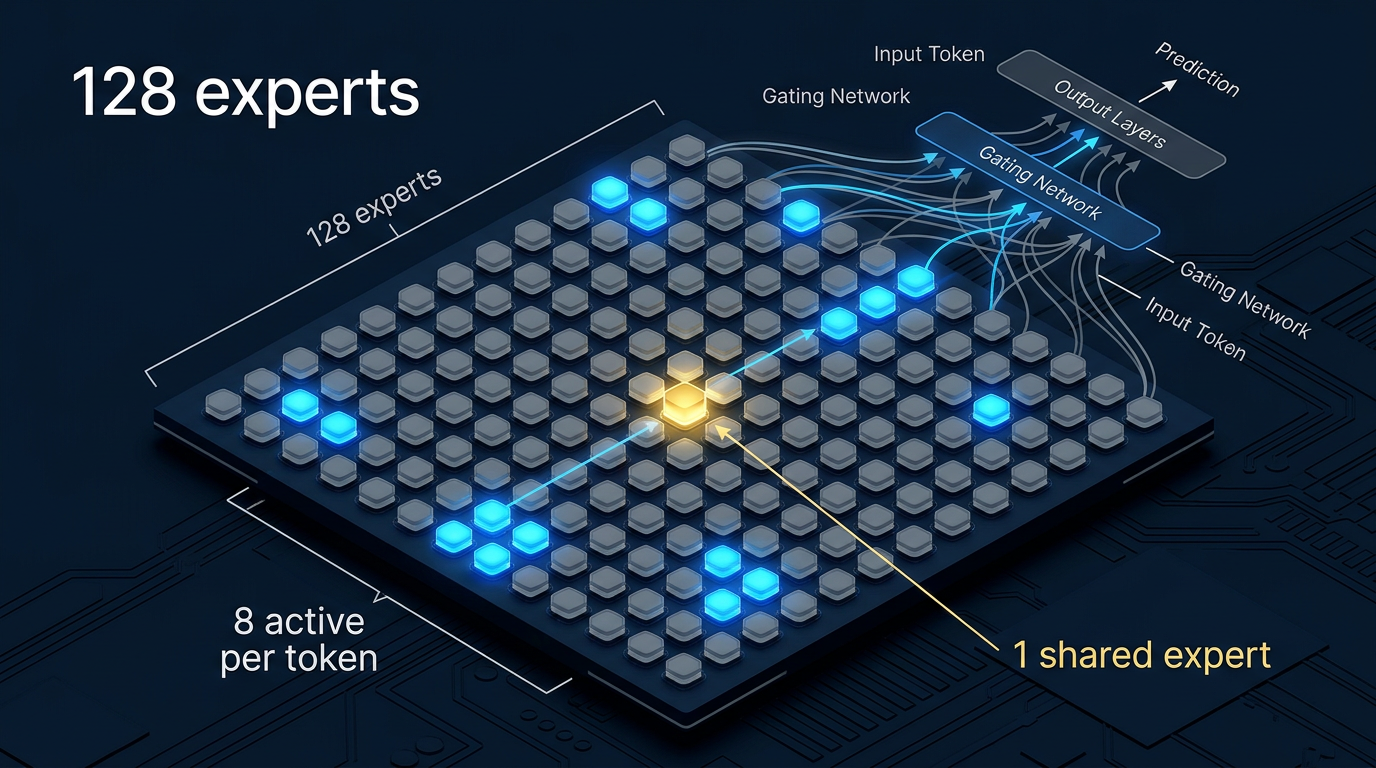
Mixture-of-Experts (MoE) er arkitekturen som har gjort det mulig å skalere modeller langt utover det RAM-budsjettet skulle tilsi. Command A+ har 128 eksperter totalt, og ved hvert token aktiveres topp-8 av dem – pluss en enkelt delt ekspert som alltid er med. Du betaler altså i praksis for en 25B-modell i beregningskraft, men får med deg mønstrene fra hele 218B-parameternettverket.
Cohere oppgir 128K tokens kontekstvindu med mulighet for utvidelse til 1 million tokens, støtte for 48 språk, og spesialstyrker innen agentbaserte arbeidsflyter, RAG og multimodale dokumenter. Lisensen er Apache 2.0, som betyr at du kan bruke den kommersielt uten å betale Cohere en krone.
Til sammenligning: Qwen3-5 122B som lenge har vært den sterkeste lokale modellen har 122B totale parametere og 10B aktive – Command A+ slår den på begge fronter.
Hva er det tekniske som gjør MLX-porten interessant?
MLX er Apples eget maskinlæringsrammeverk, bygget spesifikt for Apple Silicon. Det utnytter unified memory – det vil si at GPU og CPU deler samme minneplass – noe som betyr at en M2 Max med 96 GB RAM faktisk kan laste en kvantisert versjon av en 218B-modell.
Utvikleren som laget MLX-porten dokumenterte arkitekturen grundig, og det er noen interessante valg Cohere har gjort her:
- Sigmoid routing i stedet for softmax – mer stabil normalisering av ekspert-vektene
- Sliding window attention i 3:1-forhold (tre sliding + ett full attention-lag), interleaved
- RoPE (Rotary Position Embeddings) kun på sliding window-lagene
- Delt ekspert med større intermediate-størrelse (16384 = 4096×4), kombinert med routed output via gjennomsnittsoperasjon
Dette er ikke standard MoE-oppsett. Sigmoid routing er uvanlig – de fleste modeller bruker softmax for å normalisere ekspert-vektene. Coheres valg kan gi bedre stabilitet ved trening, men det betyr også at mlx-lm trengte en dedikert cohere2_moe-implementasjon i stedet for å gjenbruke eksisterende MoE-logikk.
Pull requesten er åpen per nå. Når den merges, vil Command A+ bli tilgjengelig som en førsteklasses modell i mlx-lm – den mest brukte veien for å kjøre store modeller på Mac. Du kan følge MTPLX-implementasjonen for å se hva Apple Silicon allerede klarer med store modeller.
Hva trenger du for å kjøre dette?
Her er den kjedelige nyheten: 218B MoE er stort. Selv med kvantisering ned til 4-bit trenger du rundt 130-150 GB RAM for å laste hele modellen. Det betyr i praksis en M2/M3/M4 Ultra med 192 GB unified memory, eller to maskiner i en pipeline-konfigurasjon.
Cohere oppgir at modellen i sky-kontekst kjører greit på to H100-er med W4A4-kvantisering, eller én NVIDIA Blackwell-GPU. Apple Silicon er ikke direkte sammenlignbart, men unified memory-fordelen er reell – en Mac Studio Ultra med 192 GB RAM er faktisk et kandidatoppsett.

For de fleste vil Command A+ via API være det praktiske alternativet inntil videre. Men det at MLX-porten finnes betyr at lokal kjøring er på vei – og for de som har maskinvaren, er det bare å vente på at PR-en merges.
Hvis du vil ha en god lokal modell som faktisk kjører i dag uten ekstrem hardware, er lokale modell-guidene et godt sted å begynne.
Hva betyr dette for Cohere og open source AI?
Cohere er primært et enterprise-selskap – de selger API-tilgang og private deployments til bedrifter. Men de har valgt Apache 2.0 på Command A+, den samme lisensen de brukte på Cohere Transcribe tidligere i år.
Det er et kalkulert valg. Vektene er åpne, community-en bygger porter og integrasjoner, og Cohere får distribusjon og troverdighet uten å miste inntektsstrømmene fra enterprise-kundene som vil ha managed inference og SLA-garantier.
Modellen leverer 63% høyere output tokens per sekund sammenlignet med Command A Reasoning, og 17% lavere latency for time-to-first-token. Det er ikke irrelevante tall – det er forskjellen på en responsiv agent og en som føles treaktig. For de 48 støttede språkene gjelder også forbedret tokenisering: arabisk +20%, koreansk +16%, japansk +18%.
For open source-landskapet er dette uansett godt nytt. En 218B Apache 2.0-modell med dokumentert arkitektur og aktiv community-tilpasning til Apple Silicon – det var ikke normalt for to år siden. Nå er det en nyhet, men ikke en overraskelse.
Følg med på mlx-lm GitHub for statusen på PR-en. Og hvis du tester Command A+ – enten via API eller når MLX-støtten er klar – er det interessant å høre hva du synes sammenlignet med Qwen3-5 122B og andre tungvekter i lokalt AI-landskap.







