

Innhold Vis
De fleste som kjører lokal LLM bruker den til koding eller chat. Men det finnes et bruksområde som er langt mer interessant – og underutnyttet: å bruke en lokal modell som din personlige, private kunnskapsbase. Dump inn egne notater, PDF-er, fakturaer, møtereferater, helsedokumenter – og spør om alt uten at en eneste byte forlater maskinen din.
Dette er ikke like enkelt som å laste ned Ollama og skrive en prompt. Det krever et gjennomtenkt oppsett med dokumentinnlasting, embedding-generering og et grensesnitt som faktisk fungerer i hverdagen. Men det er fullt mulig, og resultatene kan være overraskende gode.
Her går jeg gjennom hva som faktisk kreves, hvilke verktøy som er modne nok til daglig bruk, og hva du bør passe på underveis.
Hva er egentlig en lokal LLM kunnskapsbase?
En lokal LLM kunnskapsbase kombinerer to teknologier: en språkmodell som kjører på din egen maskin, og et RAG-system (Retrieval-Augmented Generation) som gjør det mulig for modellen å søke i dine egne dokumenter. I stedet for å svare basert på treningsdata alene, henter systemet relevante tekstbiter fra dine filer og sender dem som kontekst til modellen.
Praktisk betyr det at du kan laste opp 500 sider med PDF-er – eksempelvis legedokumenter, prosjektnotater eller gamle e-poster – og deretter stille spørsmål som «hva sa legen om medisinen min i mars?» eller «hva ble vi enige om i møtet med kunden?». Modellen leser ikke hele arkivet for hvert spørsmål; den bruker embeddings til å finne de mest relevante passasjene og svarer basert på dem.
Det viktige her er lokal. Ingen data lastes opp til OpenAI, Google eller noen andre. Alt skjer på din hardware.
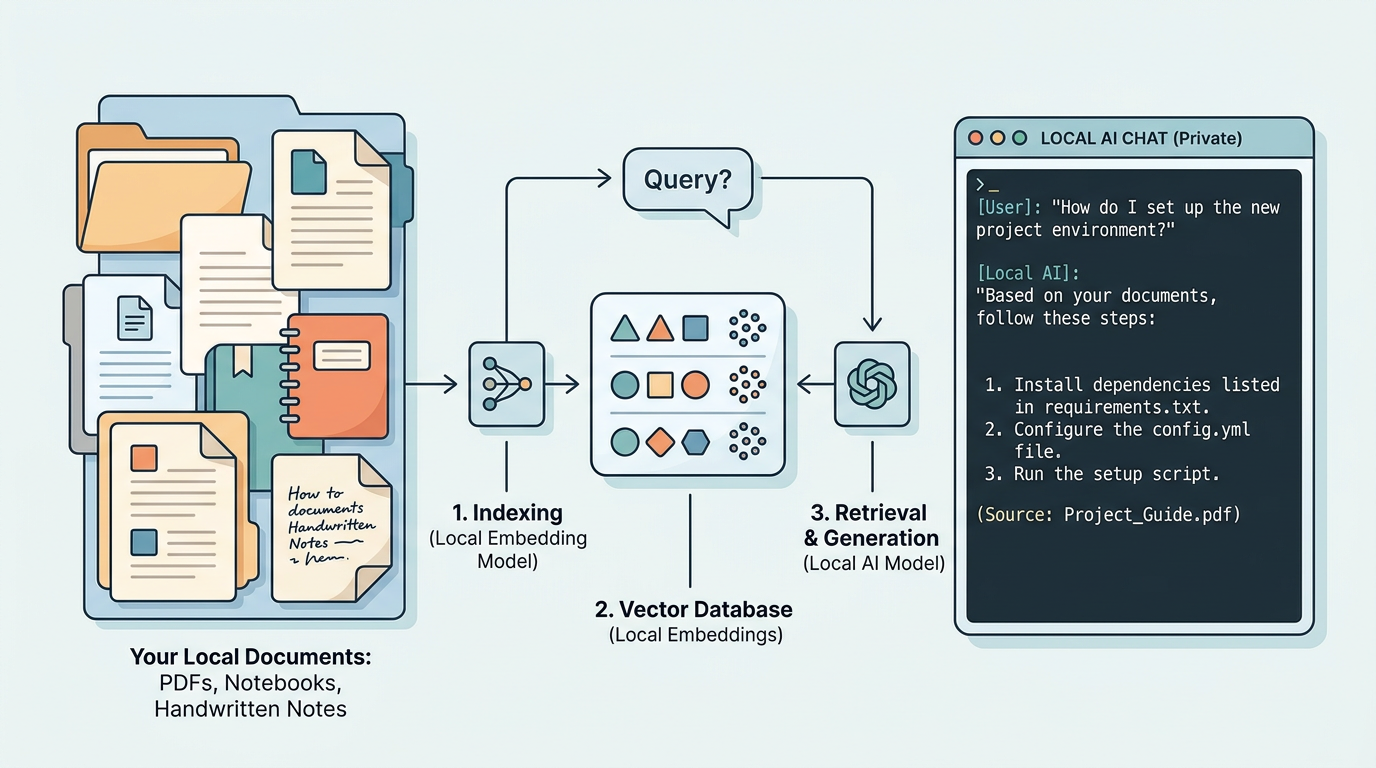
Hvilke verktøy er gode nok i 2026?
AnythingLLM er per i dag det mest komplette alternativet for dette bruksområdet. Det er et open source-prosjekt med et grafisk grensesnitt som støtter dokumentopplasting (PDF, Word, TXT, Markdown, nettsider), lokal Ollama-integrasjon, og embeddings som lagres lokalt via ChromaDB. Ifølge AnythingLLMs dokumentasjon kan du koble til Ollama, LM Studio eller andre lokale backends direkte fra innstillingsmenyen.
Det er ikke perfekt. Søkekvaliteten varierer med hvilken embedding-modell du velger, og store dokumentsamlinger kan gjøre oppsett tregt. Men for daglig bruk med et par hundre dokumenter er det solid nok.
Open WebUI – det samme grensesnittet mange bruker som ChatGPT-alternativ med Ollama – har også fått RAG-funksjonalitet. Du kan laste opp filer direkte i chatten eller bygge et eget dokumentarkiv. Fordelen er at du kanskje allerede har Open WebUI kjørende, og da er det null ekstra oppsett. Ulempen er at RAG-implementasjonen er enklere enn AnythingLLMs, og søk i store samlinger kan bli upålitelig.
For de som vil ha full kontroll finnes det også Chroma, LlamaIndex og LangChain – men da er vi over i utviklerterritorium. Det krever Python-kode og en del tålmodighet. Resultatet kan bli bedre skreddersydd, men terskelen er høyere.
Et godt utgangspunkt er å ha Ollama oppe og kjørende først – resten av oppsettene bygger på det.
Hvilken modell bør du velge?
For en lokal kunnskapsbase er det to ting som betyr mest: kontekstvindu og instruksjonsforståelse. Du vil ha en modell som kan håndtere lange tekstpassasjer og forstå hva du faktisk spør om – ikke bare mønstermatche.
Modeller i 7B-14B-parametersklassen fungerer godt på de fleste moderne maskiner med 16 GB RAM eller mer. Mistral 7B og Qwen2.5 7B er begge gode valg – de har 32 000-128 000 tokens kontekstvindu avhengig av variant, og de forstår instruksjoner presist. Større modeller som Llama 3.1 70B gir bedre resonnementer, men krever en skikkelig GPU eller en maskin med mye RAM.
For embedding-modellen – den som konverterer dokumenter til vektorer som kan søkes i – er nomic-embed-text et solid valg via Ollama. Den er liten (274 MB), rask og gir god søkekvalitet. AnythingLLM bruker den som default når du kobler til Ollama.
Du kan lese mer om lokal LLM-kjøring og alternativer til Ollama i artikkelen om hvorvidt lokal LLM-kjøring egentlig trenger Ollama.
Hva fungerer bra – og hva fungerer ikke?
Det som fungerer overraskende bra er spørsmål om konkrete fakta i dokumenter du har lastet inn. «Hva er betalingsfristen i kontrakten fra januar?» eller «hvilke symptomer nevnte jeg i helseloggen fra februar?» – den typen spørsmål gir konsistente, presise svar når RAG-systemet har funnet riktig passasje.
Det som fungerer dårligere er sammendrag på tvers av mange dokumenter, spørsmål som krever at modellen sammenligner informasjon fra 15 ulike filer samtidig, eller spørsmål der relevansen er uklar. RAG er ikke magisk – den henter de passasjene som semantisk ligner mest på spørsmålet ditt, ikke nødvendigvis de som er mest nyttige. Formulering av spørsmålet betyr mye.
En annen ting å ha i bakhodet: dokumentkvalitet slår alt annet. En skannet PDF uten OCR gir null nyttig tekst. Word-dokumenter med mye formatering kan gi uventet støy. Rene tekstfiler og Markdown-dokumenter er det RAG-systemer er best på.

Hva slags dokumenter egner seg?
Noen kategorier peker seg ut som spesielt nyttige for en privat kunnskapsbase:
- Medisinske dokumenter – journaler, prøvesvar, utskrivningsbrev. Spesielt nyttig for folk med kroniske sykdommer som trenger å holde oversikt over behandlingshistorikk.
- Møtereferater og prosjektnotater – finn igjen beslutninger, hvem som sa hva, og hvilke oppgaver som ble avtalt.
- Kontrakter og avtaler – søk etter spesifikke klausuler uten å lese 40 sider manuelt.
- Egne skriverier – dagbøker, tanker, ideer. Spesielt interessant kombinert med verktøy som Obsidian.
- Faglig litteratur – legg inn PDF-er av bøker og artikler og still spørsmål til dem.
Det som er verdt å merke seg er at dette ikke erstatter et skikkelig dokumenthåndteringssystem. RAG søker i tekst, ikke i metadata. Hvis du vil finne «alle dokumenter fra 2024» trenger du fremdeles en mappe eller tagging-system i tillegg.
Slik setter du opp AnythingLLM med Ollama
Grunnoppsettet er relativt rett frem:
- Installer Ollama og last ned en modell – for eksempel
ollama pull qwen2.5:7bogollama pull nomic-embed-text. - Last ned AnythingLLM Desktop (finnes for Mac, Windows og Linux).
- Under innstillinger – velg «Ollama» som LLM-leverandør og skriv inn
http://localhost:11434. - Velg samme URL for embedding-modellen og velg
nomic-embed-text. - Opprett et workspace, last opp dokumenter, og start å chatte.
Det tar 10-15 minutter å sette opp første gang, og de fleste trinn er pek-og-klikk. Embeddingen av dokumentene tar litt lenger tid avhengig av filstørrelse – en vanlig PDF på 20 sider er ferdig på sekunder, en stor dokumentsamling kan ta noen minutter.
For de som er interessert i mer avanserte agentoppsett lokalt, er AMDs GAIA-rammeverk for lokale AI-agenter verdt å se på – spesielt hvis du vil automatisere dokumentinnsamlingen.
Personvern er hele poenget
Det er verdt å stoppe opp ved dette. Grunnen til at lokal kunnskapsbase er interessant er ikke at det er billigere enn skybaserte alternativer (det er det ikke nødvendigvis, hardware koster). Det er at dataene forblir dine.
Når du laster opp helsedokumenter til en skybasert RAG-tjeneste, aksepterer du at de dataene havner på servere du ikke kontrollerer, under betingelser du ikke kan verifisere. Det kan godt hende at tjenesten er trygg. Men du vet det ikke sikkert.
Med en lokal modell og lokale embeddings forblir alt på maskinen din. Ingen tredje part ser spørsmålene dine, ingen tredjepartsmodell trenes på journalnotatene dine. Det er en reell forskjell – og for sensitive dokumentkategorier bør det veie tungt i valget.
En god oversikt over open source AI-alternativene generelt finnes i artikkelen om open source AI i 2026.
Hva er realismen for vanlige brukere?
La meg være ærlig: dette er ikke noe du setter opp på fem minutter og glemmer. Det krever litt teknisk appetitt, vilje til å eksperimentere med hvilke dokumenter som gir gode resultater, og tålmodighet med at systemet ikke alltid svarer optimalt.
For den som har prøvd og synes det er for mye friksjon, finnes det et mellomløsning: skybaserte RAG-tjenester med strenge personverngarantier. Noen europeiske leverandører tilbyr GDPR-kompatibel dokumentanalyse uten at data brukes til trening. Det er ikke lokalt, men det er et steg opp fra å dytte helsejournalen sin rett inn i ChatGPT.
For de som er villige til å sette av et par timer: mulighetene er der. Verktøyene er modne nok. Og det er en merkbar følelse av kontroll i å spørre en AI om dine egne dokumenter – og vite at svaret forblir mellom deg og maskinen.
Mer om lokal AI og hva Ollama-agenter faktisk kan gjøre i praksis: Ollama-skrivebordsagent med lokal AI.








1 kommentar