

Innhold Vis
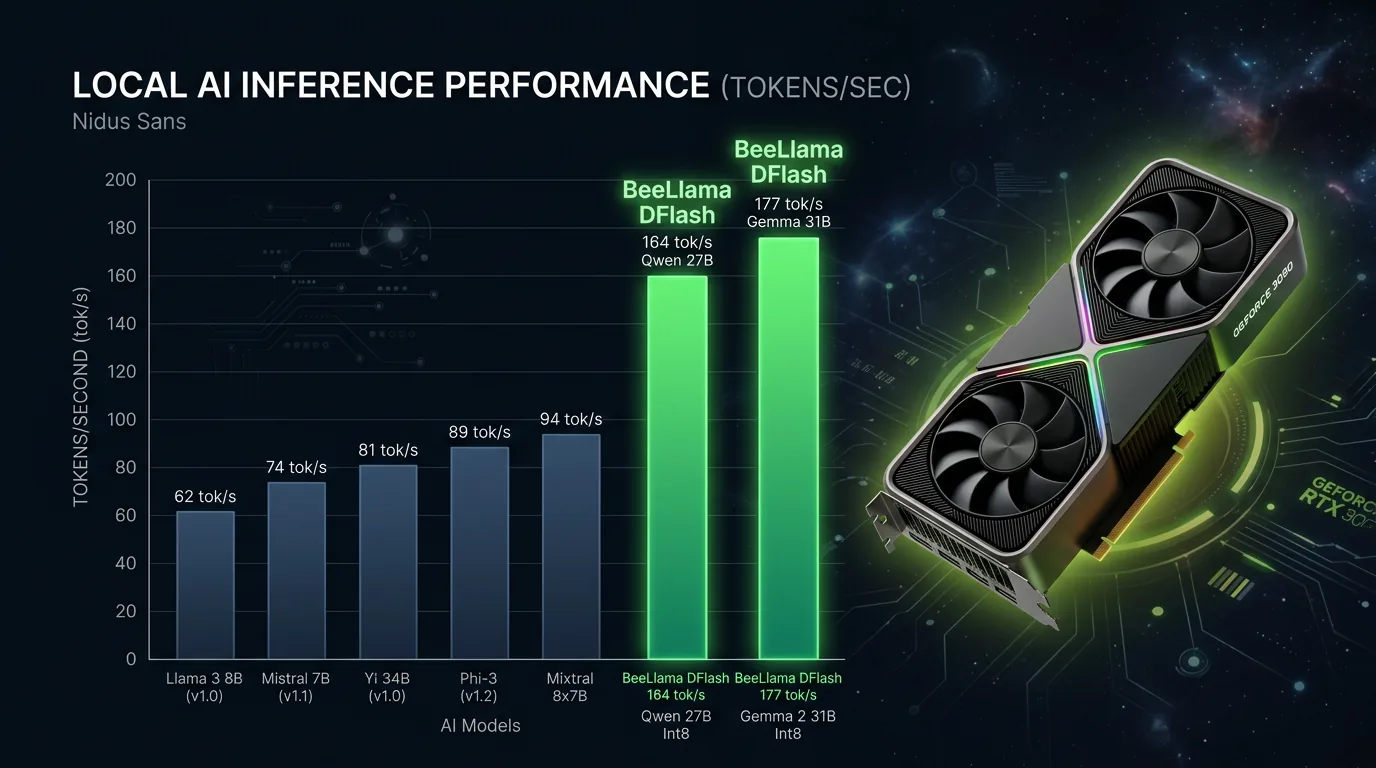
Du trenger ikke kjøpe flere GPUer for å kjøre store AI-modeller raskere. BeeLlama v0.2.0 er nettopp sluppet, og den henter ut nesten 5x raskere tekstgenerering fra én enkelt RTX 3090 – med Gemma 4 31B oppe i 177,8 tokens per sekund og Qwen3.6 27B på 164 tokens per sekund.
Det er ikke dårlig for et grafikkort som koster rundt 7 000 kr brukt. Og det skjer uten at du trenger å oppgradere maskinvare – det er pure programvareoptimalisering via DFlash, en teknikk for spekulativ dekoding som har dukket opp i stadig nye varianter det siste halvåret.
Jeg har fulgt med på denne utviklingen en stund. Luce DFlash på AMD Strix Halo viste 2,23x speedup, ExLlamaV3 DFlash leverte 2,5x på agentisk koding. BeeLlama er ikke beskjeden – den lover 4,9x. La oss se hva som faktisk skjer her.
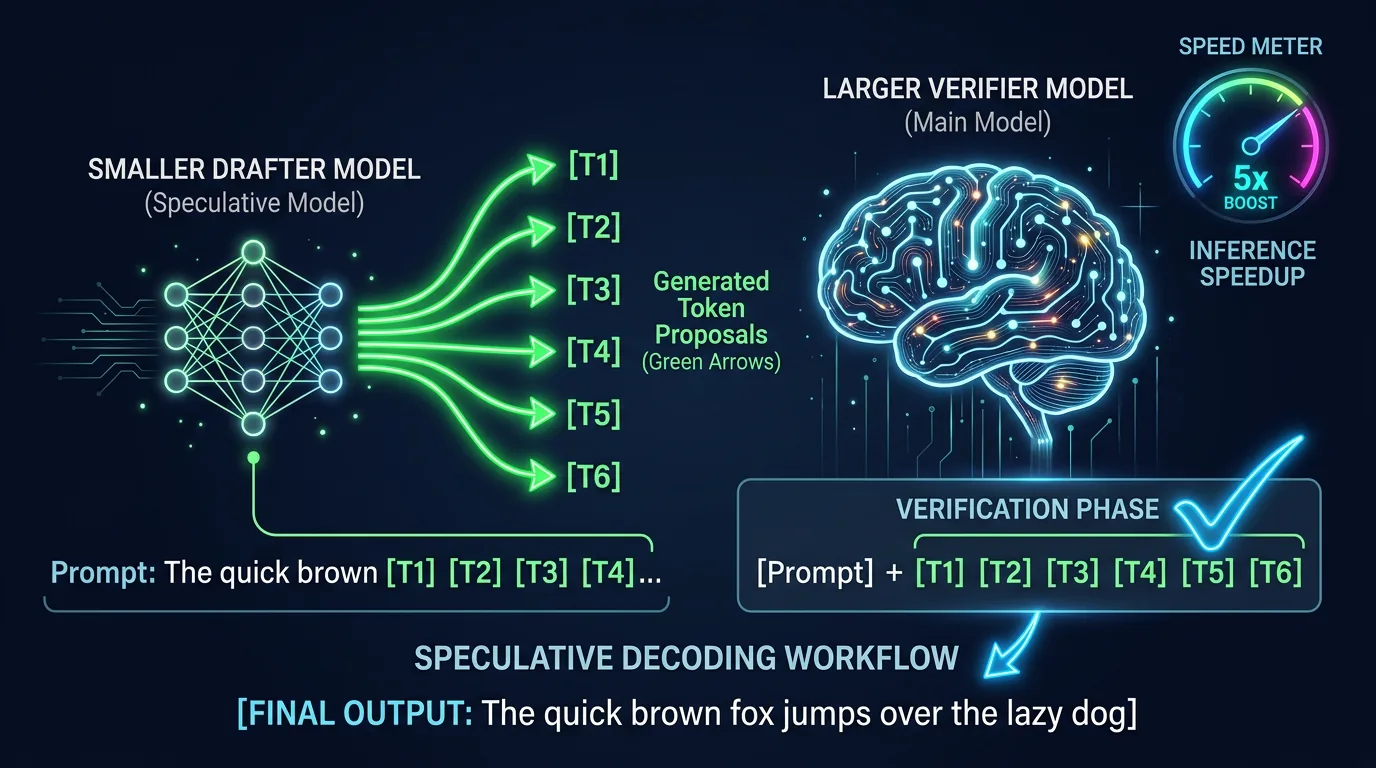
Hva er spekulativ dekoding – og hvorfor gjør det AI raskere?
Vanlig tekstgenerering fra en stor AI-modell er sekvensielt: ett token om gangen, frem og tilbake til GPU-en for hvert ord. Det er ikke GPU-en som er treg – det er minnet og overheaden per iterasjon som begrenser farten.
Spekulativ dekoding løser dette ved å bruke en liten, rask «drafter»-modell til å gjette de neste 4-8 tokenene på forhånd. Den store målmodellen får så en hel sekvens til verifisering i én runde istedenfor å sjekke ett og ett token. Hvis drafter-modellen gjettet riktig, sparer du mange rundturer. Gjettet den feil, kaster du bare drafter-forslaget og prøver igjen – du har ikke tapt noe.
DFlash er én implementering av denne ideen, med spesifikke valg rundt hvordan drafteren er bygget og hvordan K/V-hurtigbuffer (key-value cache) håndteres. BeeLlama er et inferens-verktøy som har bygget sin egen DFlash-implementering spesielt optimalisert for NVIDIA CUDA-hardware.
Hva er nytt i BeeLlama v0.2.0?
Denne oppdateringen er stor. Utviklerne kaller det selv «major DFlash update», og tallene backer det opp. Her er de viktigste endringene:
Full Gemma 4 31B-støtte er ny i v0.2.0. Modellen kjøres nå med effektiv DFlash-implementering og støtte for vision-input. Det betyr at du kan sende bilder til Gemma 4 lokalt og få rask respons. Ytelsesmålet: 177,8 tokens per sekund på én RTX 3090 – 4,93x raskere enn baseline.
Qwen3.6 27B fikk en massiv ytelsesoppgradering fra lavere DFlash-overhead. Konkret ble dette oppnådd gjennom renere prefill-håndtering, bedre K/V-projeksjonscaching i drafter-modellen og tryggere CUDA-kjøring. Resultatet: 164 tokens per sekund, opp 4,40x fra baseline.
DFlash GGUF-er med upstream-arkitektur støttes nå. Det betyr at BeeLlama kan bruke standard GGUF-modellformat – det samme formatet som brukes i llama.cpp og Ollama. Det gjør det langt lettere å hente modeller direkte fra Hugging Face og sette dem opp.
Prefill-hastighet er nær baseline, noe som er viktig å merke seg. Spekulativ dekoding hjelper på decode-steget (når modellen genererer svar token for token), men ikke nødvendigvis på prefill-steget (når den leser inn prompten din). BeeLlama har jobbet med å sørge for at prefill-overhead fra DFlash ikke trekker ned totalytelsen, og i v0.2.0 er dette i stor grad løst.
Hva betyr 177 tokens per sekund i praksis?
For å sette dette i perspektiv: en gjennomsnittlig person leser rundt 250-300 ord per minutt, eller cirka 5 ord per sekund. Det tilsvarer omtrent 6-8 tokens per sekund. Med 177 tokens per sekund genererer BeeLlama tekst mange ganger raskere enn du klarer å lese den.
Det er nok til at lokal AI faktisk føles rask og responsiv – ikke som å vente på en treig internettforbindelse. For agentisk bruk, der en AI-agent genererer kode, analyserer filer og kjeder operasjoner, er dette spesielt verdifullt. Ventetiden per steg kuttes dramatisk, og du sitter ikke og stirrer på en spinner mellom hvert trinn.
Sammenlign med hva to RTX 2080 Ti-kort gir med Qwen3.6 27B – 38 tokens per sekund. BeeLlama med én RTX 3090 gir over fire ganger mer. Det er et tydelig signal om at optimalisert software kan bety mer enn råkraft i hardware.
Hvilke modeller støtter BeeLlama?
Per v0.2.0 er disse to modellene primærmålene:
- Qwen3.6 27B – Alibabas modell på 27 milliarder parametere. Sterk på koding og resonnering. 164 tokens/s, 4,40x speedup.
- Gemma 4 31B – Googles åpne modell. Ny med vision-støtte i denne oppdateringen. 177,8 tokens/s, 4,93x speedup.
Begge er modeller i 27-31 milliarders parametere-klassen – store nok til å være genuint nyttige, men akkurat store nok til å presse grensene på en 24 GB GPU. DFlash med spekulativ dekoding er spesielt effektivt for modeller i denne størrelsesklassen, der minnebåndbredden er den primære flaskehalsen.
For Gemma 4 31B spesifikt er det verdt å nevne at DFlash-teknikken fungerer ekstra godt med tette oppmerksomhetsmodeller – altså modeller som bruker full attention istedenfor Mixture-of-Experts. Gemma 4 er en slik modell, noe som forklarer de høye tallene.
Hvor stor er speedupen egentlig?
4,93x er et sterkt tall – sterkere enn det jeg har sett fra andre DFlash-implementeringer. Eksisterende benchmarks fra lignende teknologi:
- Luce DFlash på AMD Strix Halo: 2,23x (Qwen3.6 27B)
- ExLlamaV3 DFlash, agentisk koding: 2,51x
- Gemma 4 31B DFlash på L40S: opptil 8x (datasenter-GPU)
- BeeLlama v0.2.0 på RTX 3090: 4,93x (Gemma 4 31B), 4,40x (Qwen3.6 27B)
Tallene er fra utviklernes egne målinger – slike benchmarks bør tas med en klype salt, og det er alltid verdt å teste på din egen hardware og dine egne prompts. Speedup fra spekulativ dekoding varierer mye basert på hva du ber om: repetitiv, forutsigbar tekst (kode, strukturert output) gir høy speedup. Kreativ, uforutsigbar tekst gir lavere speedup fordi drafter-modellen oftere gjetter feil.
Men selv om du i praksis ser 2-3x istedenfor 4-5x på dine egne brukstilfeller, er det fortsatt veldig bra.
Bør du prøve BeeLlama?
Hvis du allerede kjører store modeller lokalt på NVIDIA-hardware og bruker llama.cpp eller ExLlamaV3 – ja, det er absolutt verdt å teste. BeeLlama bruker GGUF-format fra v0.2.0, noe som gjør overgangen langt enklere enn før.
Krav: NVIDIA GPU med CUDA-støtte. RTX 3090 er referansehardwaren med 24 GB VRAM. Med mindre VRAM må du kvantisere modellene hardere, noe som typisk reduserer kvaliteten noe. Det er ingen nettside eller grafisk grensesnitt – BeeLlama er et kommandolinjeverktøy for folk som er komfortable med terminalen.
Hvis du er ny til lokal AI, er ExLlamaV3 med DFlash et mer modent og bredere støttet alternativ å starte med. BeeLlama er for deg som allerede vet hva du driver med og vil presse ut mer av eksisterende hardware.
Den virkelige poenget her er at DFlash-teknikken modner raskt. Det begynte med eksperimentelle implementeringer for noen måneder siden. Nå er den tilgjengelig på tvers av AMD og NVIDIA, i flere rammeverk, og med stadig bedre ytelse. Lokal AI på forbrukerhardware er ikke lenger bare mulig – det begynner å bli genuint rask.








1 kommentar