

Innhold Vis
DeepSeek V4 Pro og Flash er de nyeste modellene fra kinesiske DeepSeek – lansert med 1,6 billiarder parametere i Pro-varianten og full MIT-lisens. Begge modellene er tilgjengelige som open source, støtter opptil 1 million tokens kontekst, og kan – kanskje viktigst av alt – kjøres på Huawei Ascend-chips i stedet for Nvidias hardware.
Det er noe jeg finner genuint fascinerende med dette. DeepSeek leverer igjen en modell som teknisk sett er imponerende på papiret. Spørsmålet er om det holder som benchmarks-leder. Kort svar: ikke lenger. Men det er mer her enn konkurranseplassering.
Her er hva V4 faktisk er, hva som er nytt, og hvorfor Huawei-støtten er mer interessant enn den kanskje ser ut.
Hva er DeepSeek V4 Pro og Flash?
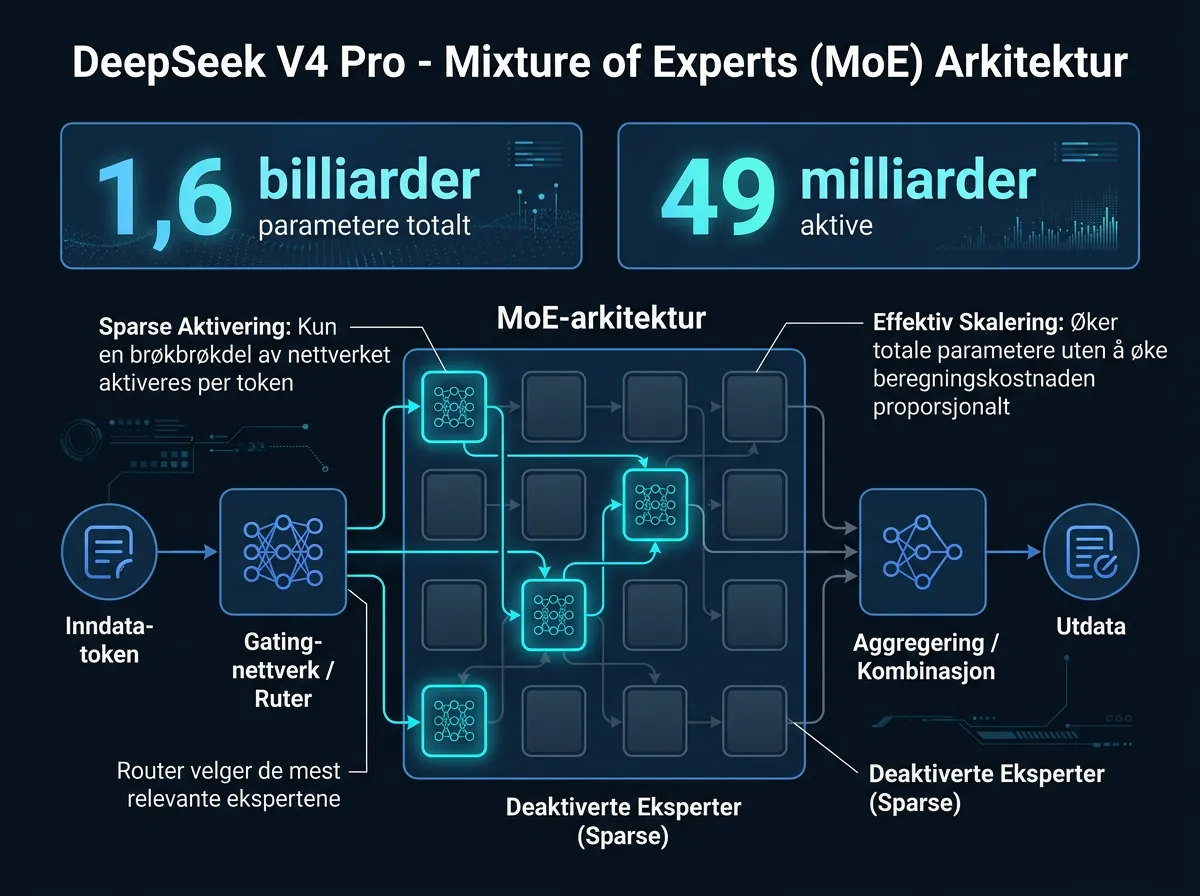
DeepSeek V4 kom i to varianter som treffer ganske forskjellige bruksområder. V4 Pro er den store: 1,6 billiarder totale parametere, men bare 49 milliarder aktive om gangen takket være Mixture of Experts-arkitektur (MoE). V4 Flash er langt mer letthåndterlig – 284 milliarder totale parametere med 13 milliarder aktive.
Begge er trent på 32-33 billiarder tokens, noe som gir omtrent 20 tokens per parameter. Begge har MIT-lisens, som betyr at du kan bruke dem kommersielt, modifisere dem, og bygge produkter oppå dem uten å betale DeepSeek noe som helst.
Og begge støtter nå 1 million tokens kontekst – en stor oppgradering fra 128 000 tokens i V3.2.
Hva er nytt sammenlignet med V3?
Det er ikke bare mer parametere. Arkitekturen har fått en skikkelig overhaling med et hybrid oppmerksomhetssystem som kombinerer flere smarte optimaliseringer:
- Delte KV-vektorer som halverer KV-cache-størrelsen
- Komprimerte KV-strømmer med 4x og 128x kompresjon
- Top-k sparsom oppmerksomhet over komprimerte tokens
- 128-tokens glidende vindu for lokal oppmerksomhet
Resultatet er ganske dramatisk i tall: V4 Pro bruker kun 27% av FLOPs-ene som V3.2 trengte ved 1 million tokens kontekst. KV-cache-minnet er redusert fra 83,9 GiB til 9,62 GiB – altså under 10% av det forrige generasjon krevde. Hele V4 Pro-modellen er designet for å passe på en enkelt 8×B200-node.
De har også innebygd tre forskjellige resonneringsmodi, og de eksponer nå både Base- og Instruct-varianter – noe som åpner for finjustering og spesialtilpasninger som ikke var like tilgjengelig tidligere. Basert på arkitekturvalget mener mange at dette er en slags forberedelse til en kommende DeepSeek R2.
Hvor god er DeepSeek V4 Pro egentlig?
Her er jeg nødt til å si det som det er: V4 Pro er veldig god, men den er ikke lenger benchmarks-kongen. Det er likevel ikke en liten prestasjon for en open source-modell.
På Artificial Analysis Intelligence Index scorer V4 Pro Max 52 poeng og er nummer to blant åpne vekt-modeller. V4 Flash Max scorer 47. På GDPval-AA (agentic real-world performance) topper V4 Pro listen blant åpne vekt-modeller med 1554 poeng. I LM Arena-rangeringen debuterte den som nummer to blant åpne modeller samlet, og faktisk nummer én i medisin og helsevesen.
Thinking-varianten ligger på nummer 8 i matematikk – ikke i toppen, men solid. Den best sammenlignbare posisjonen setter den rundt Claude Sonnet-klassen. Definitivt bedre enn GLM-5.1, men ikke på nivå med Opus 4.7, GPT-5.4 eller Gemini 3.1 Pro. Det er ikke nødvendigvis en skam – det er ganske vanlig at kinesiske modeller tar en kampsikker andreplass og konkurrerer hardt på pris.
Og prisingen er det virkelig noe å si på. V4 Pro koster $1,74 per million input-tokens og $3,48 per million output-tokens via API. Flash er enda billigere – $0,14 input og $0,28 output. For sammenligning er forrige generasjon DeepSeek V4 allerede et godt kjøp, og Flash er nesten latterlig billig for en 284 milliarder-parametermodell.
Hvorfor er Huawei Ascend-støtten interessant?
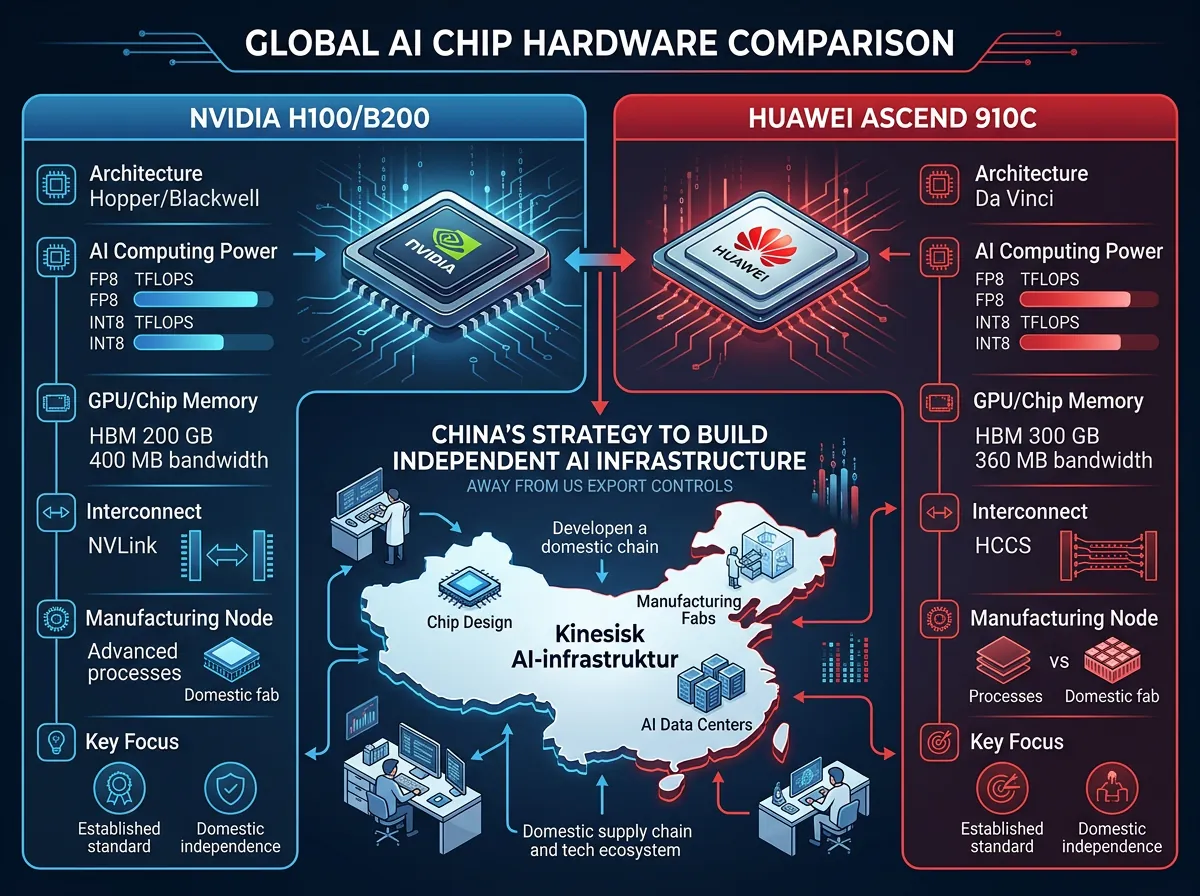
Dette er den biten av historien som fortjener mer oppmerksomhet enn den kanskje får. V4 er eksplisitt designet for å kjøre på Huawei Ascend-chips – ikke bare Nvidias H100 og B200.
USA har siden 2022 gradvis strammet inn eksportkontrollene på avansert AI-hardware til Kina. Det betyr at kinesiske selskaper som DeepSeek i prinsippet ikke kan kjøpe de nyeste Nvidia-chipene. Svaret fra Kina har vært å investere tungt i egne alternativer – og Huawei Ascend 910C og kommende 950-serien er der de satser.
DeepSeek signaliserte selv at prisene på V4 Pro kan «falle kraftig» når Huawei Ascend 950-supernoder distribueres i stor skala. Det forteller deg noe viktig: de forventer å kjøre store deler av infrastrukturen sin på kinesisk maskinvare fremover, ikke vestlig.
Dette er et stille, men viktig skift. Kinesiske AI-laboratorier er aktivt i ferd med å gjøre seg uavhengige av NVIDIA-avhengigheten. Har det ennå kommet til det punktet der Ascend er på nivå med H100? Ikke fullt ut. Men retningen er tydelig. Jeg har tidligere sett på GLM-5.1 som ble trent uten Nvidia-hardware – det er ikke lenger et unntak, det er en trend.
Bør du ta i bruk DeepSeek V4?
Det avhenger av hva du trenger. Flash er på mange måter det interessante alternativet for de fleste – 284 milliarder parametere til nesten ingen kostnad via API gjør den til en sterk kandidat for koding, skriving, og enklere agentoppgaver der du trenger volum og fart. Prisingen er mer som et «trykkbar uten å tenke»-nivå.
V4 Pro er for de som trenger topp åpen-modell-kvalitet til en brøkdel av hva lukkede modeller koster. Den sitter i et litt underlig spenn – den er ikke helt på nivå med de absolutt beste proprietære modellene, men den er åpen, redigerbar, og kan finjusteres for spesifikke domener.
Og hvis du er skeptisk til å sende data til kinesiske servere – noe jeg forstår – kan du i prinsippet kjøre den selv. Det er jo hele poenget med MIT-lisensen. Du trenger ganske mye hardware for V4 Pro (det er snakk om en 8×B200-node), men Flash er langt mer tilgjengelig for de som har tilgang til skikkelige GPUer.
Noe av det som irriterer meg litt med DeepSeek-debatten er at den alltid ender i enten overdrevet hype eller paranoiabasert avvisning. Modellene er teknisk gode. MIT-lisensen er ekte. Personvernspørsmålene ved å bruke deres API er reelle – men det er fullt mulig å bruke modellene uten å røre DeepSeek-serverne. Mer om hvordan den kinesiske AI-utfordreren posisjonerer seg har jeg skrevet om tidligere.
Hva betyr dette for open source AI-landskapet?
DeepSeek V4 bekrefter noe som har vært tydelig en stund: gapet mellom proprietære og åpne modeller krymper fortsatt. For et år siden var det utenkelig at en open source-modell kunne konkurrere med GPT-4 på bred basis. Nå sitter V4 Pro og sloss om topp-10-plasser globalt.
Mixtral, Llama, Qwen, GLM, og nå DeepSeek V4 – open source AI-landskapet er langt rikere og mer kompetitivt enn det noen hadde sett for seg. Det er bra. Konkurranse driver innovasjon, og åpne modeller gir deg kontrollen over egne data.
Jeg er fremdeles skeptisk til å bruke DeepSeek-API-et direkte – kinesisk lovgivning gjør det vanskelig å vite hvem som har tilgang til data som passerer gjennom. Men selve modellene, kjørt lokalt eller på infrastruktur du kontrollerer? Det er en annen samtale. V4 Flash spesielt er verdt å ha på radaren.








1 kommentar